Detecting overfitting in Neural Networks during long-horizon grokking using Random Matrix Theory
Abstract: Training Neural Networks (NNs) without overfitting is difficult; detecting that overfitting is difficult as well. We present a novel Random Matrix Theory method that detects the onset of overfitting in deep learning models without access to train or test data. For each model layer, we randomize each weight matrix element-wise, $\mathbf{W} \to \mathbf{W}_{\mathrm{rand}}$, fit the randomized empirical spectral distribution with a Marchenko-Pastur distribution, and identify large outliers that violate self-averaging. We call these outliers Correlation Traps. During the onset of overfitting, which we call the "anti-grokking" phase in long-horizon grokking, Correlation Traps form and grow in number and scale as test accuracy decreases while train accuracy remains high. Traps may be benign or may harm generalization; we provide an empirical approach to distinguish between them by passing random data through the trained model and evaluating the JS divergence of output logits. Our findings show that anti-grokking is an additional grokking phase with high train accuracy and decreasing test accuracy, structurally distinct from pre-grokking through its Correlation Traps. More broadly, we find that some foundation-scale LLMs exhibit the same Correlation Traps, indicating potentially harmful overfitting.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of the Paper
What is this paper about?
This paper is about spotting when a neural network (a kind of AI model) starts to overfit—meaning it memorizes the training data instead of learning general rules—without needing any training or test data. The authors introduce a simple test that looks only at the model’s saved weights (the numbers inside the model) to detect a warning sign of overfitting they call Correlation Traps.
What questions are the researchers asking?
- Can we tell if a trained model is overfitting just by examining its weights, without seeing any training or test examples?
- Is there a clear difference between two look-alike situations: 1) before the model learns to generalize (pre-grokking) and 2) after it has generalized but then starts to fail again from over-training (anti-grokking)?
- Can we tell which “traps” are actually harmful and which are harmless?
How did they study it? (Methods in simple terms)
First, a bit of background:
- Grokking is when a model first memorizes the training set and only much later suddenly “gets it” and starts doing well on new (test) examples.
- Anti-grokking is what the authors call the next stage: after the model has learned to generalize, if you keep training for too long, its test performance can start dropping again, even though training performance stays great. That’s classic overfitting—just happening late.
Their main tool comes from Random Matrix Theory (RMT), which you can think of as the math of “what big grids of random numbers usually look like.” If a big grid of numbers (a matrix) is truly random, its “fingerprint” (a certain shape of values called a spectrum) should follow a standard pattern. If it doesn’t, something non-random is going on.
What they do:
- Every layer in a neural network has a weight matrix (a big grid of numbers).
- They shuffle the entries of that matrix like shuffling cards, which breaks clever patterns but keeps the overall collection of numbers the same.
- Then they check whether the shuffled matrix looks “normal-random” by comparing it to a known baseline shape (called the Marchenko–Pastur, or MP, distribution). Think of MP as the “typical histogram” you’d expect if the entries were random.
- If they see big spikes far beyond what “normal-random” would produce, they call those spikes Correlation Traps. These spikes mean some directions in the weights are unusually strong even after shuffling—so the model has hidden, non-random structure that can reflect overfitting.
In short:
- If the shuffled weights still show big, standout patterns, that’s suspicious—like finding a “cheat sheet” that remains even after you scramble the pages of a book.
To check if a trap is actually harmful, they use a simple, data-free behavior test:
- They “remove” a trap (replace it with random noise) and feed the model random inputs.
- They compare how the model’s output probabilities change before vs. after removal (using a score called Jensen–Shannon divergence, or JSD). If outputs change a lot, the trap is probably important and potentially harmful. If nothing much changes, the trap may be benign.
A short version of their trap-finding steps:
- Pick a layer’s weight matrix.
- Shuffle its entries.
- Measure the spectrum (how strongly the matrix stretches in different directions).
- Fit the normal-random baseline (MP).
- Count any big outliers beyond the normal range—these are Correlation Traps.
A simple intuition for “why traps matter”:
- In healthy learning, many small effects average out—like lots of pebbles balancing on a scale.
- A trap is like one heavy rock that dominates the scale. When one direction dominates, the model can latch onto specific quirks of the training data instead of general rules. This is what statisticians call a failure of “self-averaging.”
What did they find, and why is it important?
They tested their idea in three settings:
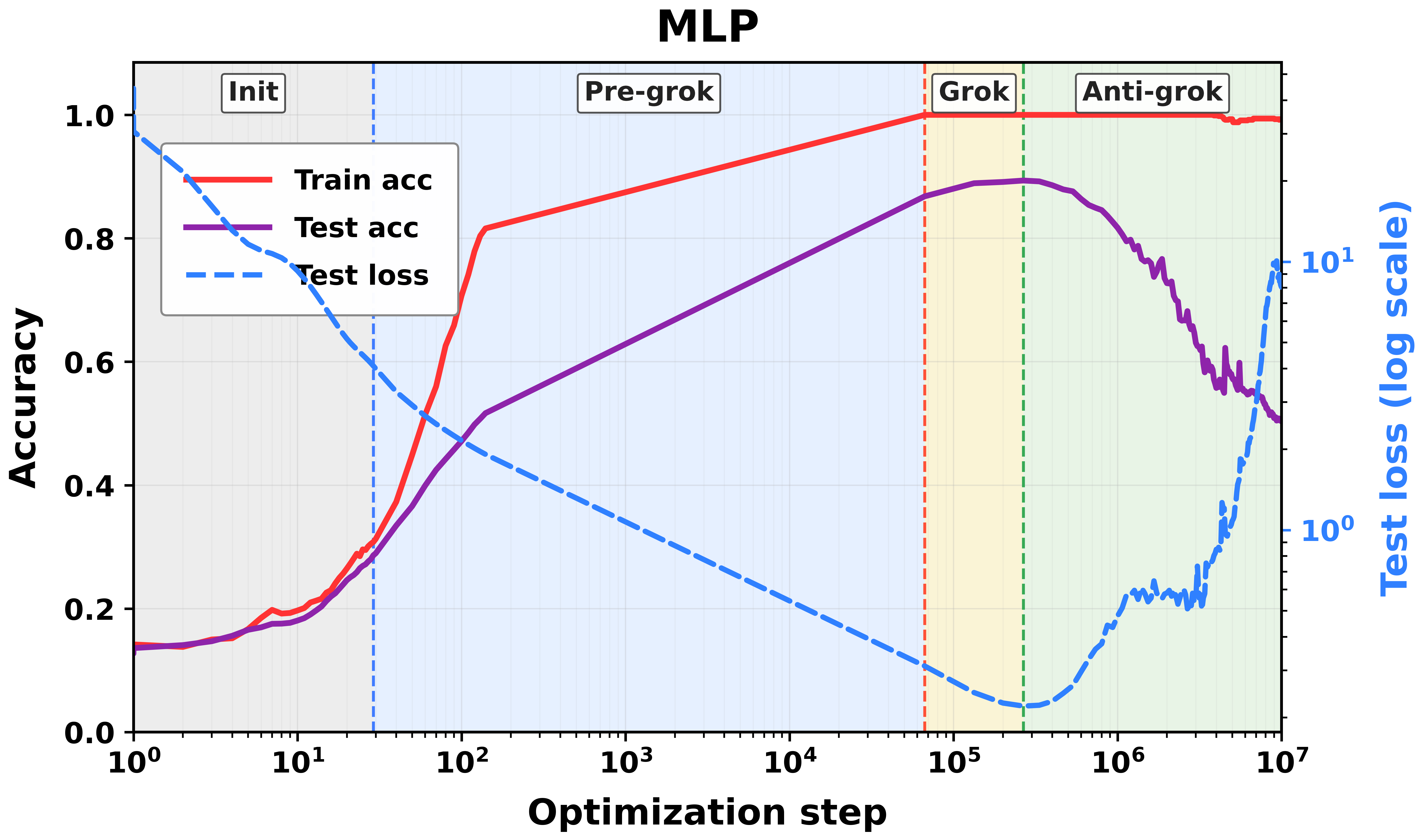
- A small image classifier (an MLP) on a tiny MNIST subset.
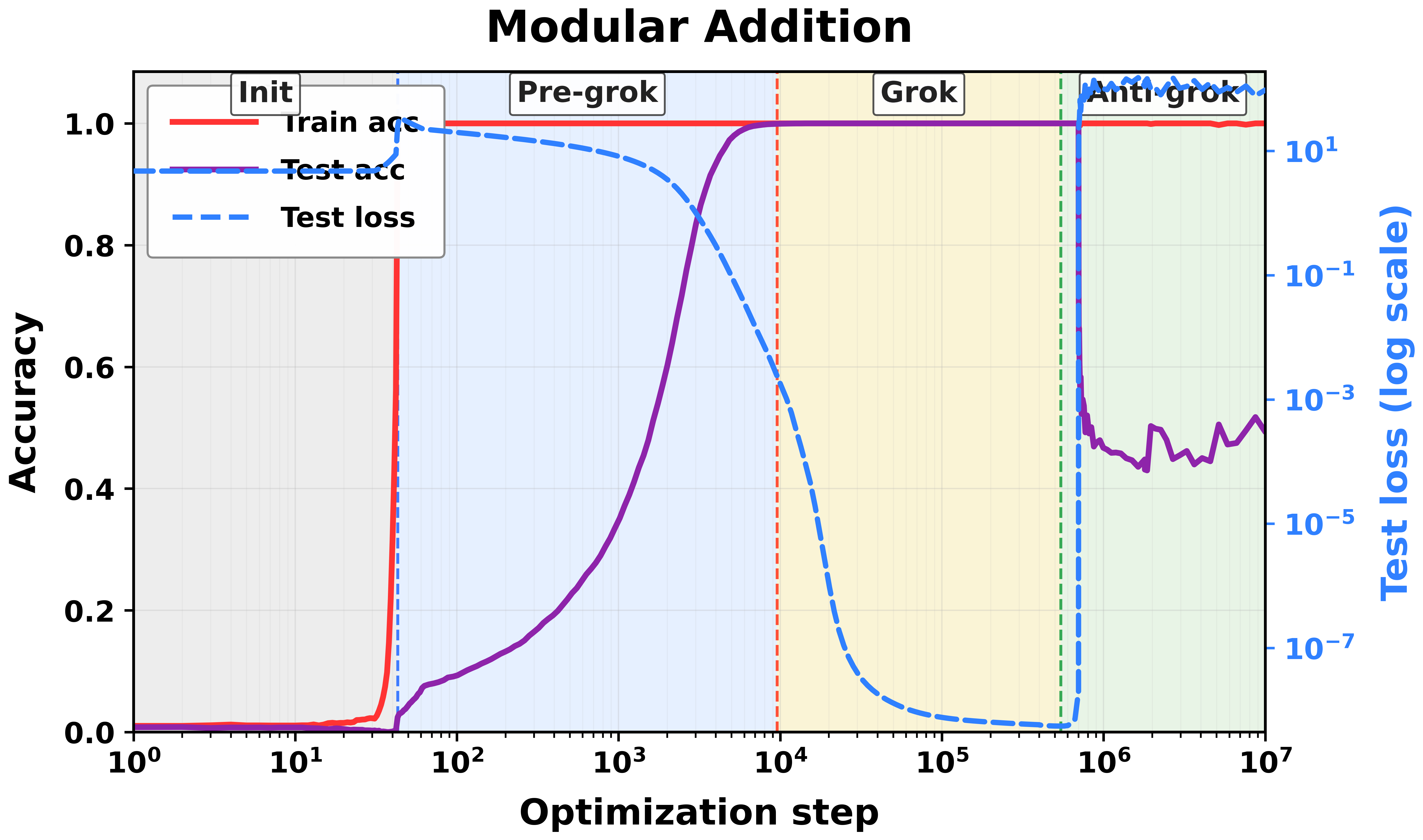
- A toy math task (Modular Addition) with a small Transformer.
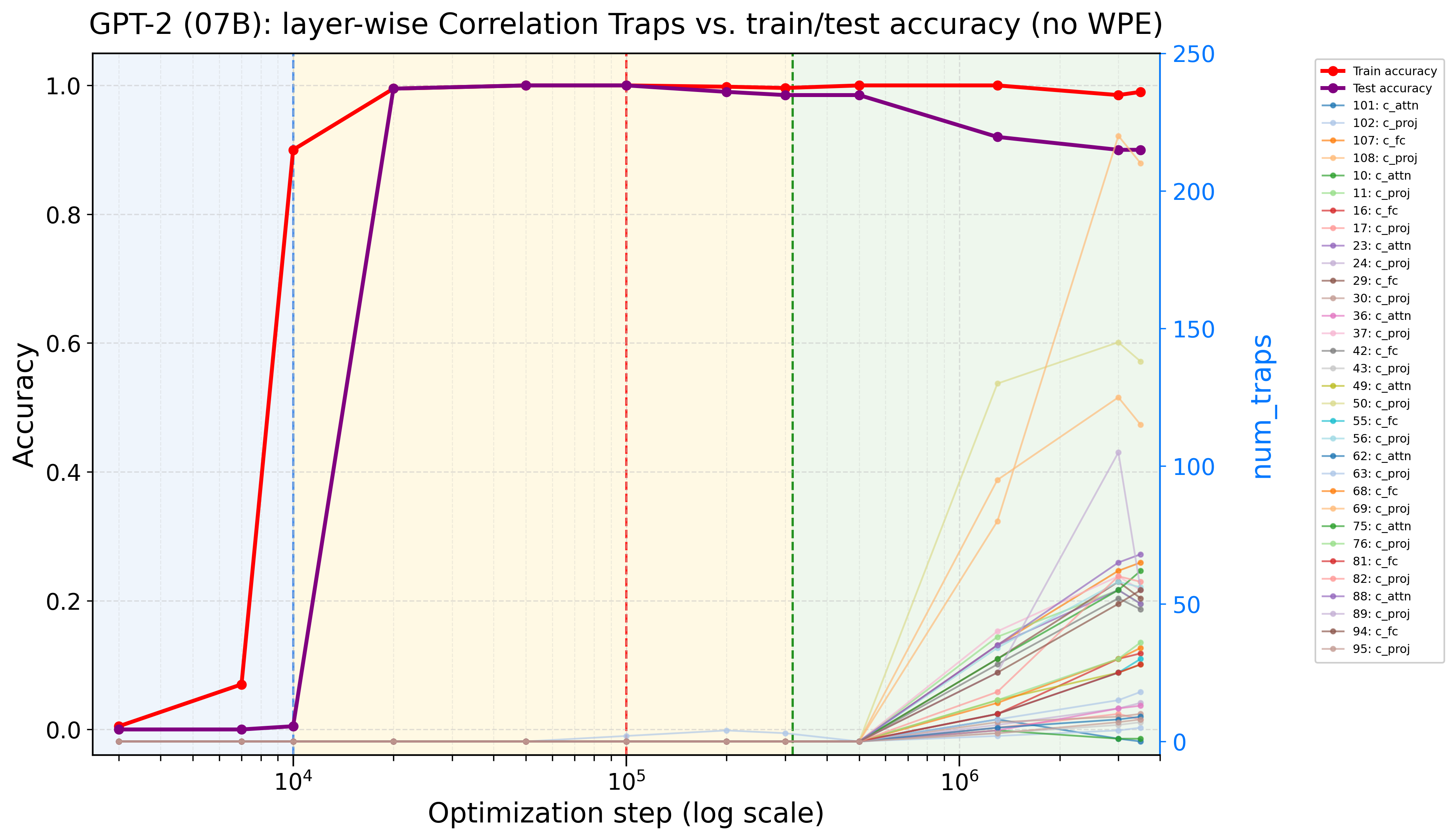
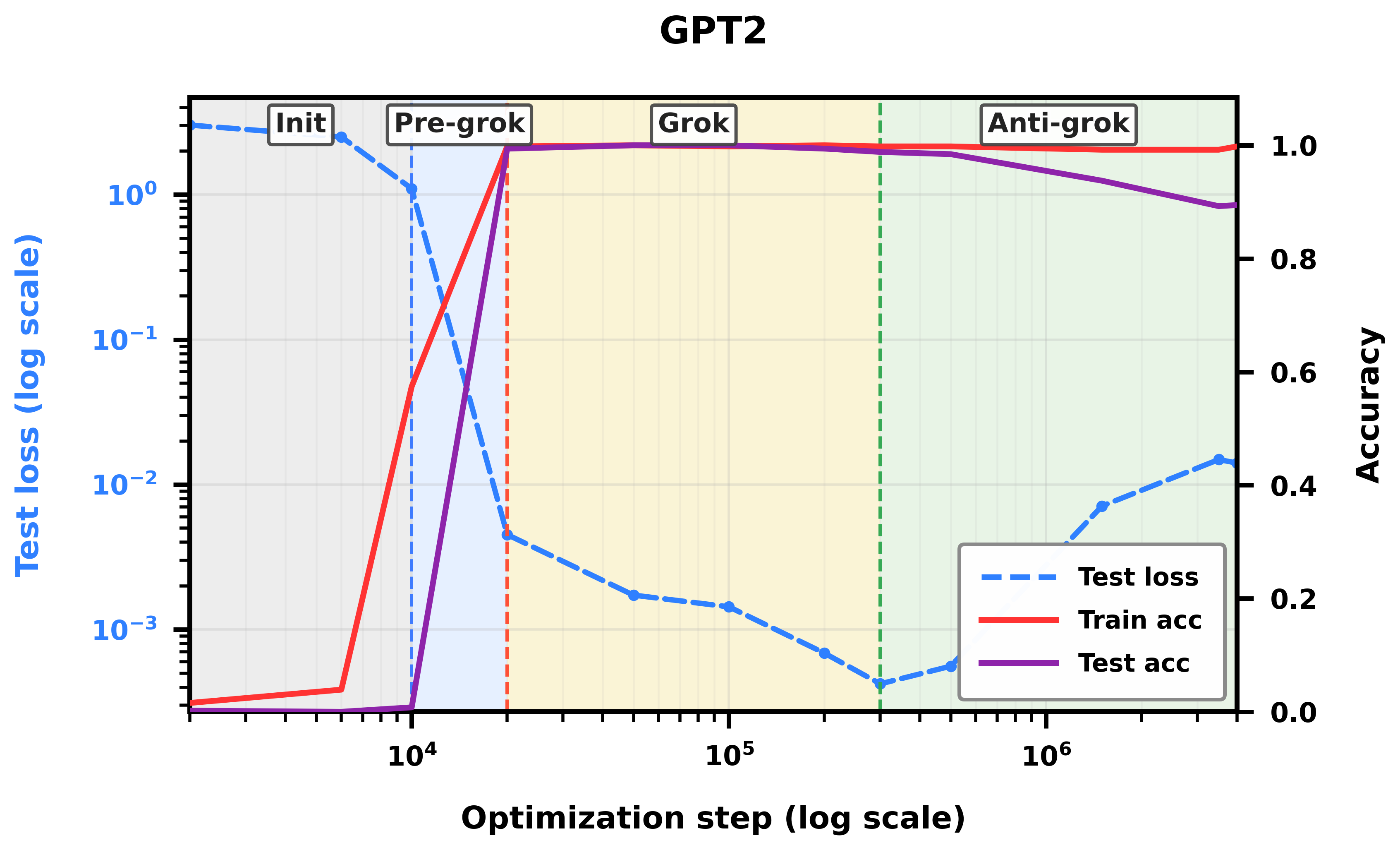
- A GPT-2–style model trained on a synthetic reasoning task.
Across all three:
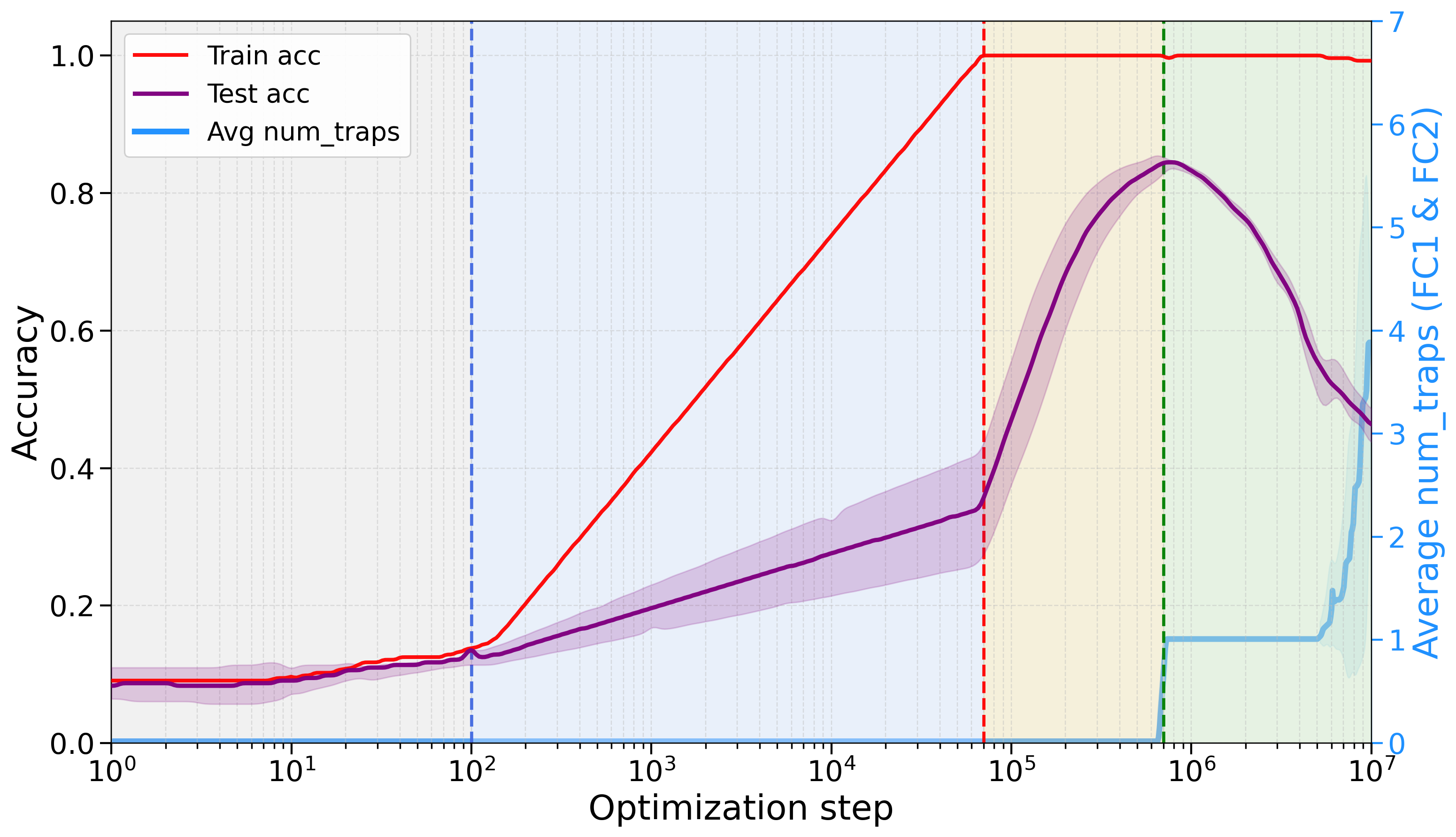
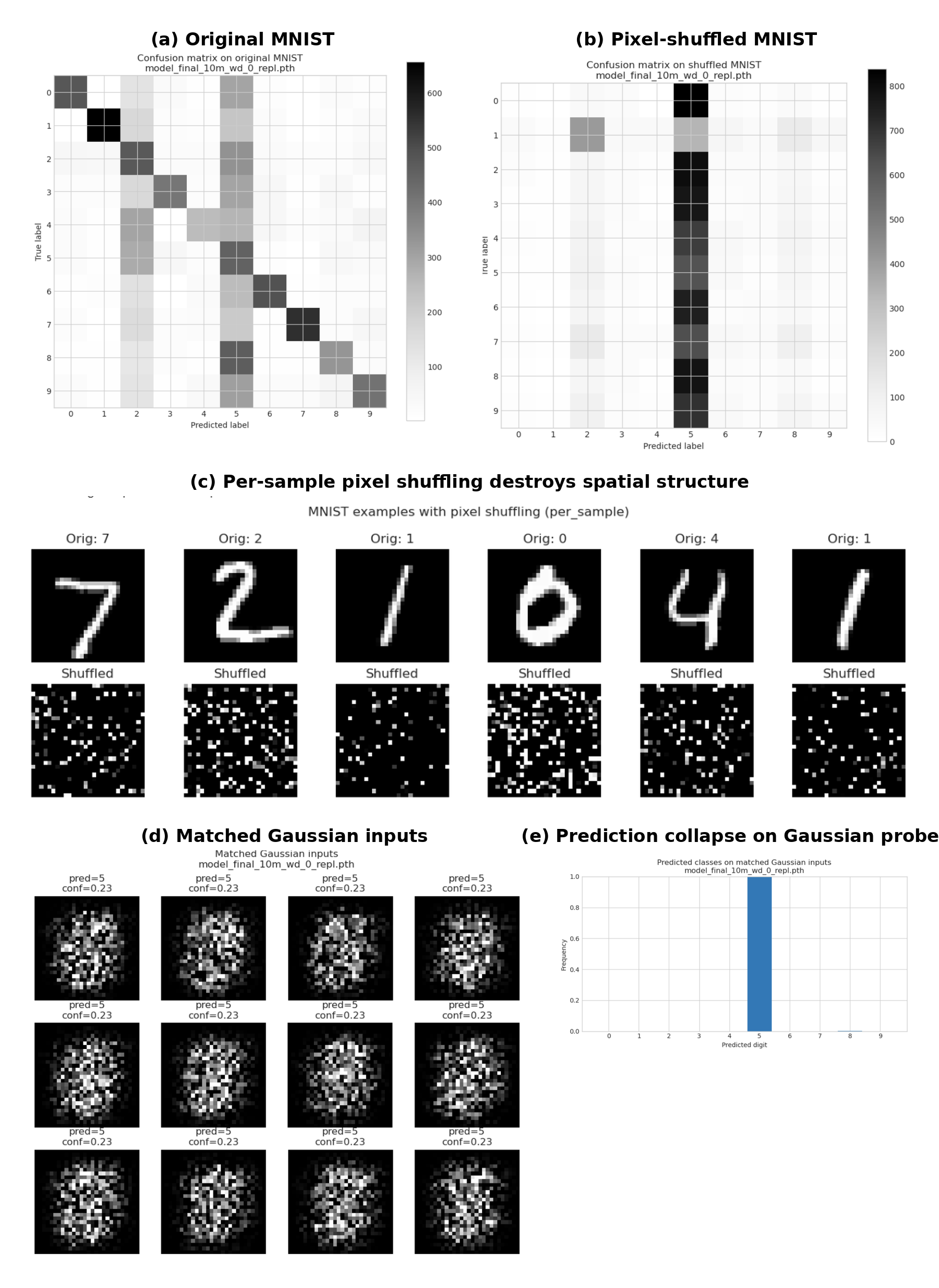
- Training goes through three phases: 1) Pre-grokking: training accuracy rises; test accuracy stays low. 2) Grokking: test accuracy suddenly improves—generalization! 3) Anti-grokking: after long extra training, test accuracy starts to drop again while training accuracy stays high.
- Correlation Traps stay near zero during pre-grokking and grokking.
- Traps appear and grow only during anti-grokking, and they track the decline in test accuracy. In other words, the traps “switch on” right when overfitting begins.
They also checked two more things:
- Weight decay (a regularization trick that discourages very large weights) reduces both the number of traps and the amount of overfitting. This supports the idea that traps are tied to harmful overfitting.
- A stress test showed traps aren’t just measuring “big weights.” Even when they changed weight scales, traps still only appeared in anti-grokking, not earlier.
Finally, they ran the diagnostic on two large open-weight LLMs and found many traps in some layers. That doesn’t prove those models are overfitting in a harmful way, but it’s a warning sign worth investigating.
Why this matters:
- You can run this diagnostic using only a model checkpoint—no training data, no test data, no training logs. That’s perfect for open-source models where we often don’t have the original data.
What could this change or influence?
- Model auditing: People who download open models can quickly screen them for signs of overfitting using just the weights.
- Training and fine-tuning: Teams could monitor trap counts during training as an early warning and adjust regularization, learning rates, or stop earlier.
- Safety and quality checks: Trap profiles could help decide which layers or checkpoints need extra testing, and could help regulators or evaluators assess models without accessing private training data.
A note of caution:
- Not every form of overfitting will produce traps, and not every trap is harmful. The JSD “remove-and-check” test helps tell harmful traps from benign ones, but trap counts alone shouldn’t be used as a universal quality score.
Key takeaways in one place
- Overfitting can show up late, after a model has already learned to generalize (anti-grokking).
- The paper introduces Correlation Traps—weight-only signals that appear precisely when this late overfitting begins.
- Traps can be found by shuffling layer weights and checking for unusually large spectral spikes beyond the normal-random baseline.
- Traps rise during anti-grokking across very different models and tasks.
- You can identify which traps are harmful using a simple, data-free JSD ablation test.
- This gives a practical way to detect and investigate potential overfitting in open-weight models without needing any datasets.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain or unexplored in the paper, framed as concrete gaps that future work can directly address.
- External validity: Does the trap diagnostic generalize beyond the three long-horizon grokking settings (MNIST MLP, modular addition transformer, GPT2 on synthetic composition) to diverse, real-world data, tasks (e.g., natural language, vision, speech), and architectures (CNNs, ViTs, MoE, graph nets, diffusion models)?
- Architectural coverage: How should traps be defined and measured for layers with weight sharing or nonstandard structure (convolutions, depthwise separable convs, attention Q/K/V/O matrices, embeddings, tied weights, layernorm/scale parameters, biases), and do results persist across these components?
- Heavy-tailed marginals: Entry-wise shuffling preserves the marginal distribution of weights; if layer weights are heavy-tailed (common in trained nets), the MP fit may be mis-specified. When do heavy-tailed marginals produce spurious outliers, and what is a principled heavy-tailed RMT baseline for trap detection?
- Finite-size calibration: How should the Tracy–Widom buffer ΔTW be estimated at realistic finite N,M, and how sensitive are trap counts to this calibration and to histogram/spectral density estimation choices?
- Multiple comparisons: With many layers and checkpoints, how should trap-outlier decisions be corrected for multiple testing to control false discovery rates?
- Sensitivity to aspect ratio: How robust is trap detection to layer aspect ratio Q=N/M, especially in very rectangular matrices and in layers whose shapes change (e.g., projections, grouped ops)?
- Shuffling null model: Do alternative nulls (e.g., row/column permutations, block shuffles, sign randomization, phase randomization, preserving column norms) change trap incidence, and which null best isolates correlations rather than heavy-tail artifacts?
- Mapping from shuffled traps to original weights: The ablation “replace trap with a suitable random vector” is under-specified—how exactly are trap directions identified in Wrand mapped back to modify W, and how reproducible is this mapping across runs?
- Localization/condensation quantification: The paper informally invokes localization and condensation but lacks a standardized metric and decision rule (e.g., IPR, participation ratio, mass-on-top-k) to predict harmfulness ex ante. Which localization/condensation metrics best predict generalization impact?
- Harmful vs benign discrimination without labels: Beyond the JSD-on-random-probes heuristic, is there a purely weight-only or activation-only criterion that reliably predicts harmful traps without any labeled test data or random-input probing?
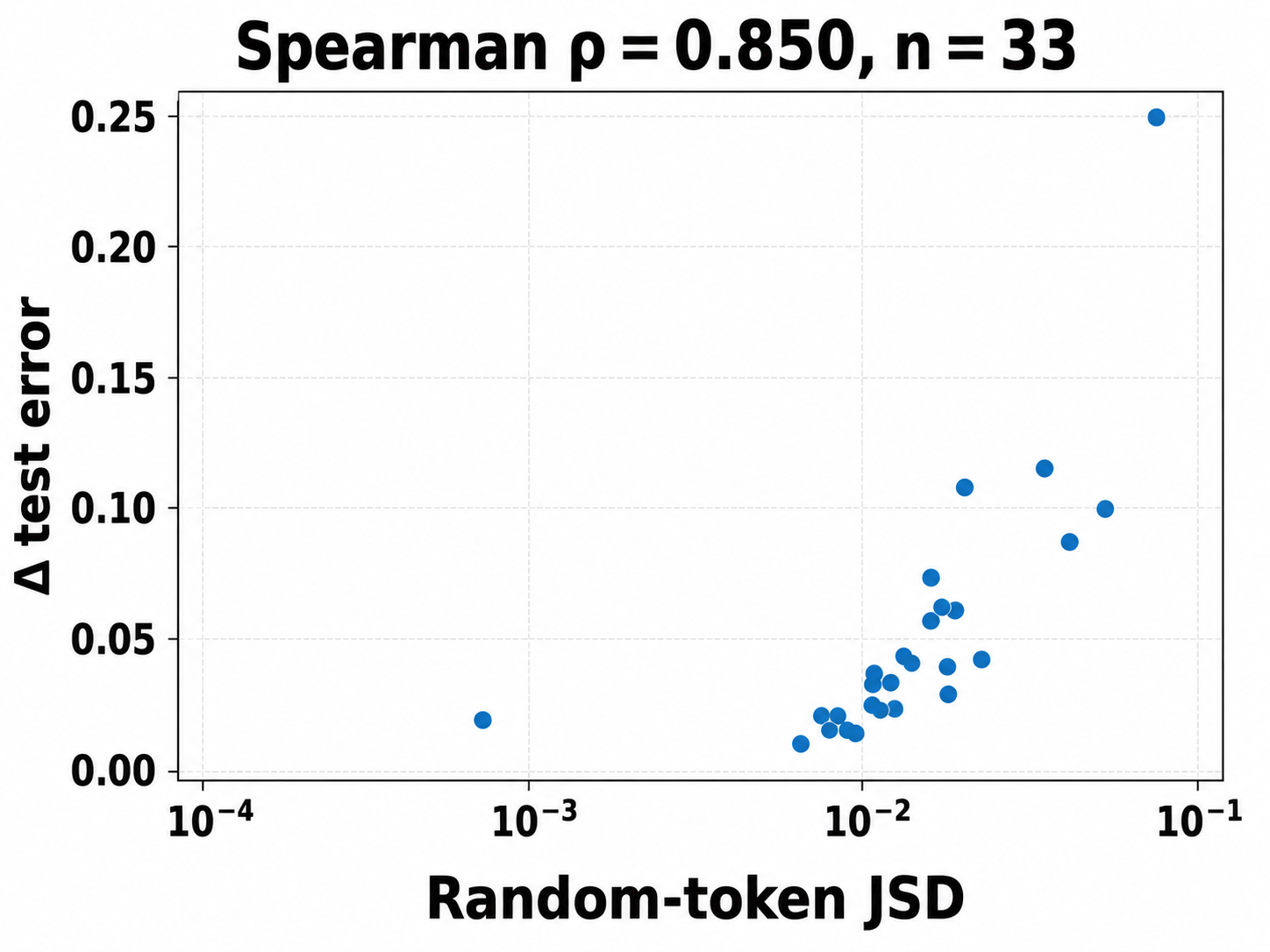
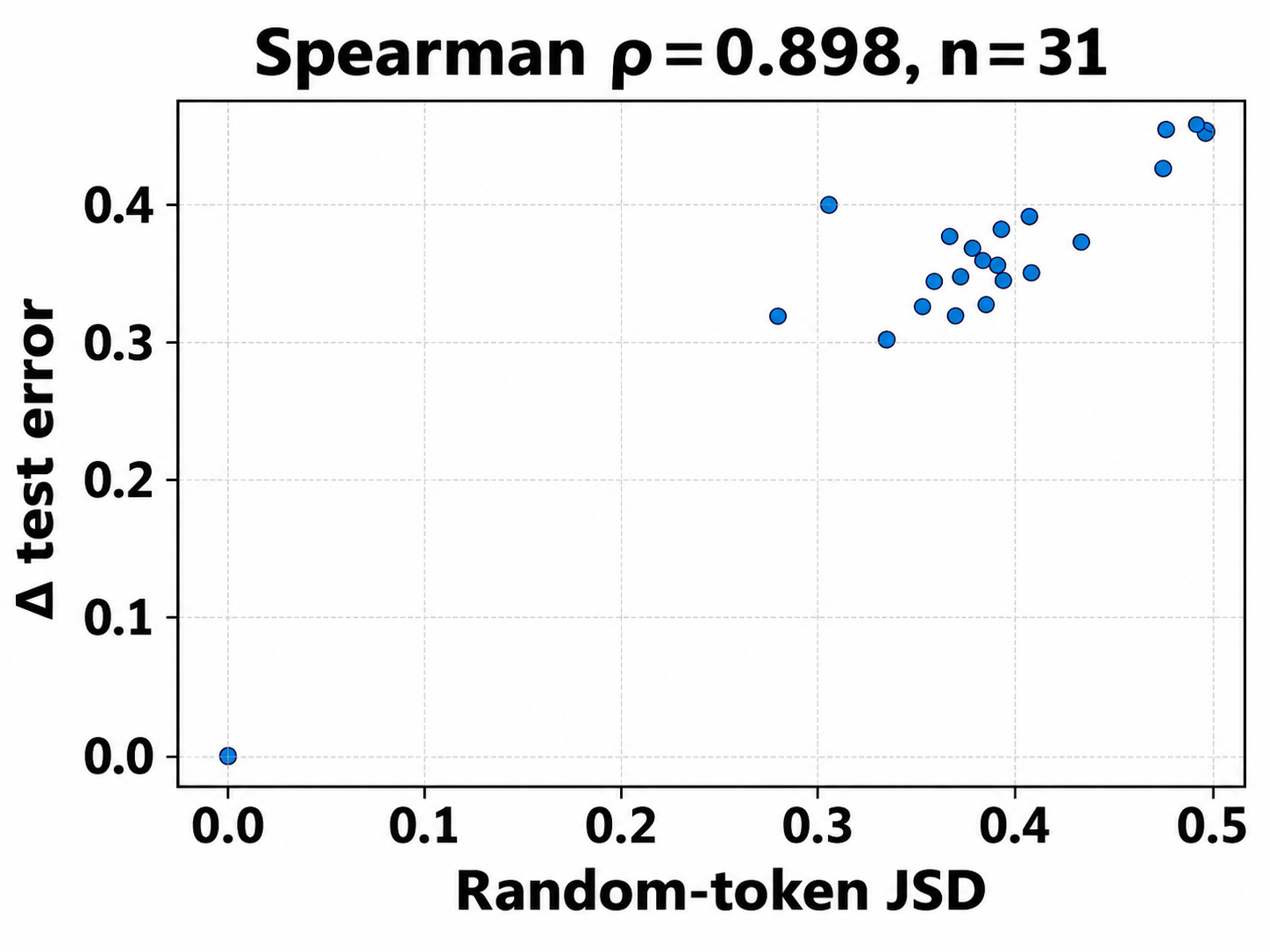
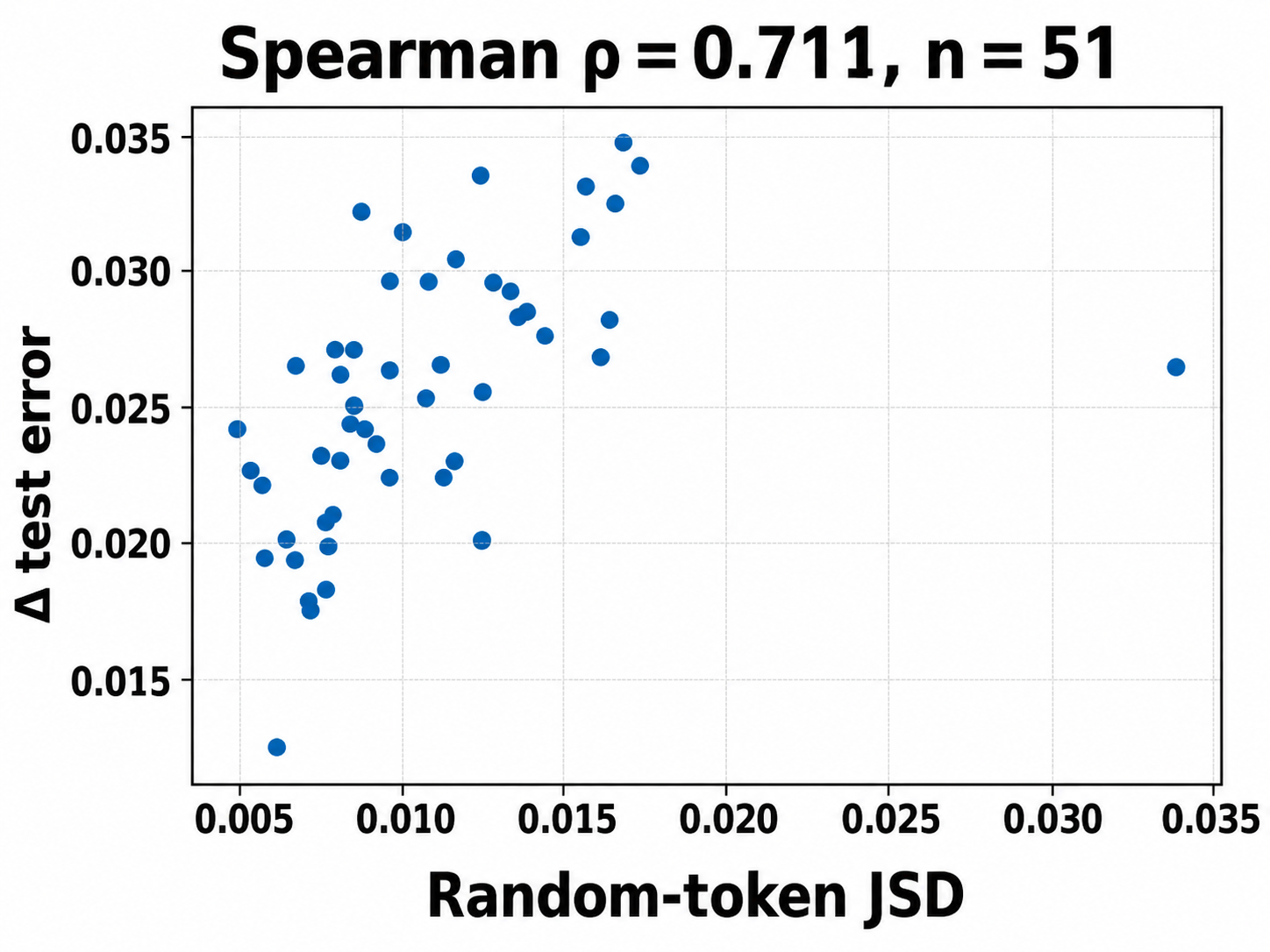
- JSD probe distribution: Using random tokens or Gaussian inputs may not reflect operational input distributions. How does the JSD diagnostic’s utility vary with probe choice, temperature T, and task domain, and does it predict harm on real data reliably?
- JSD scale and calibration: Can Jk(T) be calibrated for cross-model comparisons (different sizes/training regimes) so that an absolute threshold indicates risk, rather than only within-model ranking?
- Causal remediation: Can targeted regularizers or surgical interventions suppress harmful traps while preserving benign/salutary structure (e.g., trap-shrinkage penalties, spectral clipping, trap-aware weight decay, SWA/weight averaging, structured noise injections)? Do such interventions improve generalization in anti-grokking?
- Early-warning utility: Can trap onset be used prospectively during training to trigger early stopping or adaptive regularization before generalization collapses? What detection thresholds/timings minimize false alarms and missed detections?
- Hyperparameter and optimizer sensitivity: How do learning rate schedules, batch size, optimizer choice (SGD, AdamW, Lion), weight decay, dropout, label smoothing, mixup/augmentations, and data curriculum affect trap formation?
- Seed and run-to-run variability: What is the variance of trap counts and their timing across random seeds and training replicates, and how consistent are harmful/benign classifications?
- Relationship to existing diagnostics: How do traps compare or combine with other overfitting indicators (loss landscape sharpness/flatness, linear mode connectivity, representation collapse metrics, activation sparsity, NTK/CK metrics, WeightWatcher heavy-tailedness on unshuffled W)? Are traps complementary or redundant?
- False positives/negatives: Under what conditions do non-overfitting phenomena (e.g., useful specialization, gating, routing, rare-token experts) produce trap-like spectra, and when does overfitting proceed without detectable traps?
- Frontier-scale interpretability: In large LLMs, which submodules (Q/K/V/O, MLP-in, MLP-out, embeddings) carry most traps, and do trap hotspots align with behavioral regressions or safety issues (e.g., brittleness, memorization, toxic amplification)?
- Size normalization for cross-model comparison: How should trap counts be normalized for model/layer size, rank, and spectrum scale, to avoid confounding larger models with more traps simply due to dimension and tighter TW fluctuations?
- Computational practicality: Full SVD per large layer is expensive. What randomized or streaming spectral estimators (e.g., Lanczos, subspace iteration) match detection accuracy at scale, and what is the runtime-overhead vs. accuracy trade-off during training?
- Quantized/pruned/sparse models: How does quantization, pruning, structured sparsity, and low-rank adapters affect trap detection reliability and interpretation?
- Dataset pathologies: Do label noise, class imbalance, domain shifts, or data contamination modulate trap formation, and can trap profiles diagnose specific data issues?
- Memorization and privacy: Are traps correlated with memorization of training data and privacy leakage risks? Can trap diagnostics flag checkpoints with elevated membership inference or extraction vulnerability?
- Anti-grokking taxonomy: Is anti-grokking distinct from catastrophic forgetting, representation drift, or optimization-induced distributional skew? What objective criteria distinguish these phenomena?
- Robustness to rescaling and invariances: Are trap counts invariant under weight rescalings that preserve function (e.g., layernorm, residual scaling, reparameterizations), or can such invariances confound trap detection?
- Conv layers and unrolling: For convolutional layers, does the choice of unrolling (im2col vs. Fourier domain vs. Toeplitz approximation) alter trap detection, and which representation best reflects harmful correlations?
- Statistical theory: Under what precise assumptions does trap appearance imply non-self-averaging generalization error? Can the localization/condensation mechanisms be formalized and tied to test error concentration bounds?
- BBP applicability limits: BBP separation presumes specific noise models; when layer entries are non-i.i.d., structured, or heavy-tailed, what theoretical adjustments are needed for valid outlier claims?
- Thresholding and binning choices: How sensitive are trap counts to ESD binning, smoothing, MP fit objective, and outlier threshold definitions, and can a standardized, robust fitting protocol be established?
- Layerwise attributions: Which layers’ traps most strongly predict test degradation, and can per-layer trap profiles guide targeted regularization or fine-tuning strategies?
- Prospective validation: Can a blinded, pre-registered study show that trap onset predicts future generalization collapse on held-out data across multiple tasks/architectures?
- Real-world LLM behavior: For the gpt-oss-20b/120b screening, do layerwise trap profiles correlate with standardized evaluation drops (reasoning, MMLU, factuality, toxicity) or safety-relevant failure modes?
- Integration with training pipelines: How can trap diagnostics be incorporated into standard training/fine-tuning workflows (frequency of checks, sample of layers, alert thresholds), and what is the operational cost?
- Reproducibility specifics: The main text omits some operational details (precise trap-to-weight ablation procedure, ΔTW estimation, MP fit implementation). Publishing full algorithms, seeds, and ablation code would enable independent replication.
- Extensions beyond weights: Do analogous “activation traps” (e.g., non-self-averaging in activation covariances under random probes or train data) provide stronger or earlier signals than weight-only spectra?
- Data-free vs. data-light regimes: What is the minimal data access (e.g., small unlabeled probe sets) needed to substantially improve harmful-trap discrimination over purely weight-only methods?
- Repair via post-hoc editing: Can trap-aware fine-tuning (e.g., LoRA on non-trap subspaces, trap-downweighting) restore generalization in anti-grokking without harming in-distribution performance?
These gaps outline theory, methodology, scalability, and validation steps needed to establish Correlation Traps as a robust, general-purpose diagnostic and to convert detection into reliable, practical interventions.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can use the paper’s methods now, without needing access to training or test data beyond model weights. Each item notes sector(s), suggested tools/workflows, and key assumptions/dependencies.
Industry
- Weight-only overfitting screening of checkpoints before deployment
- Sectors: software/ML platforms, healthcare (med-imaging, clinical NLP), finance (risk/forecasting), energy (demand/grid forecasting), robotics (control/RL policies), education (LLM tutors)
- What: Run the shuffled-spectrum MP fit and count Correlation Traps per layer to flag anti-grokking/overfitting signatures in candidate checkpoints.
- Tools/workflows: WeightWatcher CLI/API; automated “TrapScan” job in CI/CD; nightly scans on model registries; layer-wise trap heatmaps to prioritize review
- Assumptions/dependencies: Access to full weights; per-layer SVD feasible at model scale; MP/TW thresholding calibrated; conv layers require unfolding or layer-specific handling; trap counts are a diagnostic, not a universal quality score
- Checkpoint triage and selection for fine-tuning
- Sectors: software/ML platforms; foundation-model providers; enterprise ML teams
- What: Rank base models by trap profiles and prefer lower-trap checkpoints as starting points for domain fine-tunes (e.g., healthcare/finance compliance workloads)
- Tools/workflows: “TrapScore” badge in model cards; gating rules in model procurement portals (e.g., Hugging Face space); “Trap-aware” selection in AutoML
- Assumptions/dependencies: Trap counts correlate with reduced overfitting risk but do not replace downstream task evals; some traps can be benign
- Early-stopping and long-horizon training guardrails
- Sectors: all model training pipelines; especially small-data and long-horizon regimes (RL, algorithmic tasks, synthetic reasoning)
- What: Monitor trap counts during training; pause or early-stop when traps emerge or accelerate; cross-check with weight decay schedules (paper shows WD suppresses traps)
- Tools/workflows: Training callback to compute randomized ESD per checkpoint; dashboards plotting test loss (if available) vs. trap counts; “TrapGuard” GitHub Action
- Assumptions/dependencies: Compute overhead for frequent spectral scans; threshold tuning per architecture; still advisable to validate against held-out metrics when available
- Fine-tuning risk assessment and layer-freezing strategy
- Sectors: enterprise LLM adaptation (instruction/RLHF), domain adaptation in healthcare, finance, legal
- What: Use per-layer trap profiles to decide which layers to freeze, re-initialize, or regularize before fine-tuning (freeze trap-prone layers, or apply stronger WD)
- Tools/workflows: Layer-wise trap heatmaps; “trap-prone layer” warnings in tuning dashboards
- Assumptions/dependencies: Requires re-training or fine-tuning hooks; trap localization/condensation patterns can vary across architectures
- Data-free trap classification to prioritize interventions
- Sectors: software/ML; safety/reliability teams
- What: Use the JSD trap ablation test with random probes to distinguish harmful vs. benign traps before investing in heavier evaluations
- Tools/workflows: “JSD check” script that replaces trap-mode vectors and measures output shifts; triage list of suspect traps
- Assumptions/dependencies: Assumes random-token or Gaussian probes approximate model sensitivity; large JSD indicates behavioral impact but is best used comparatively within-model
- Governance and audit artifacts for model cards
- Sectors: all industries using open-weight or third-party models; vendors
- What: Publish trap profiles, MP-fit sanity checks, and JSD summaries in model cards as evidence of generalization posture at the checkpoint level
- Tools/workflows: “TrapCard” section templates in model documentation; CI-generated figures
- Assumptions/dependencies: Transparency norms; does not prove safety but adds independent weight-only evidence
Academia
- Reproducible benchmark add-on for grokking studies
- What: Report trap counts alongside train/test curves to separate pre-grokking from anti-grokking regimes and avoid conflating memorization with overfitting after generalization
- Tools/workflows: Lightweight WeightWatcher scripts integrated with grokking benchmark repos
- Assumptions/dependencies: Standardized thresholds for “trap onset” per dataset/architecture
- Lightweight sanity checks for released checkpoints in papers
- What: Include per-layer trap counts and example randomized ESD fits to help reviewers and readers assess overfitting risks without proprietary data
- Tools/workflows: Artifact evaluation checklists including MP-fit plots
Policy and Compliance
- Weight-only third-party audits for procurement and regulatory filings
- Sectors: public-sector adoption of AI; regulated industries (healthcare, finance); foundation-model vendors
- What: Provide trap profiles and methodology as part of evaluation packages—useful when data access is restricted
- Tools/workflows: “RegAudit-RMT” report: per-layer trap counts, methodology, compute budget, interpretation notes
- Assumptions/dependencies: Access to the full weights; auditors must calibrate thresholds and document limitations (traps ≠ definitive harm)
Daily Life (Practitioners and Small Teams)
- Quick safety/robustness check before using an open-source model
- What: Run a one-time TrapScan on a downloaded checkpoint to choose between alternatives when you have no evaluation data
- Tools/workflows: Command-line WeightWatcher; community dashboards listing trap badges
- Assumptions/dependencies: Compute available for SVD; interpret traps as “risk indicators” and still test on your task if possible
- DIY training hygiene for side projects and courses
- What: During long trainings (e.g., toy grokking tasks), use trap counts to know when you’re sliding into anti-grokking even if your train accuracy stays perfect
- Tools/workflows: Simple logging callback; opt-in early stop
Long-Term Applications
These require additional research, scaling studies, or engineering to make robust, efficient, and standardized.
Industry
- Trap-aware optimizers and regularizers
- Sectors: software/ML; foundation-model training
- What: Penalize growth of randomized-spectrum outliers during training (e.g., MP-edge penalties, trap-suppressing spectral constraints, dynamic WD/learning-rate schedules when traps increase)
- Potential products: “TrapReg” loss terms; adaptive schedulers responding to trap telemetry
- Dependencies: Efficient approximations to avoid full SVD; theory/empirics to avoid suppressing useful structure; interaction with heavy-tailed regimes
- Surgical mitigation: trap-mode editing
- Sectors: LLM providers; high-stakes deployments (healthcare, finance)
- What: Identify harmful traps via JSD, then damp, rotate, or replace the specific spectral modes; combine with targeted evaluation
- Potential products: “Layer Surgery” toolkit (safe ablation/replacement, rebalancing); evaluation harnesses for regression/sanity checks
- Dependencies: Robust procedures to preserve beneficial modes; rollback and validation pipelines
- Deployment-time defenses
- Sectors: safety/reliability; LLMOps
- What: Inference-time noise or dropout along trap directions; dynamic routing away from trap-heavy layers; gates for high-risk contexts
- Potential products: “TrapShield” runtime; policy rules that trigger safer decoding or fallback models
- Dependencies: Latency/throughput trade-offs; risk of hurting performance if traps are benign
- Model-hub standards and marketplace incentives
- Sectors: model hosting platforms; enterprise marketplaces
- What: Standard “trap profile” metadata; minimum bar for trap scanning; premium curation tiers for low-trap or trap-managed models
- Potential products: Badges, leaderboards, certification programs
- Dependencies: Community consensus on metrics/thresholds; reproducibility across tool versions
Academia
- Theory linking traps to generalization bounds
- What: Formalize non-self-averaging/BBP phase-transition signals into predictors of generalization collapse; connect to PAC-Bayes, implicit bias, and heavy-tailed self-regularization
- Dependencies: Stronger finite-sample guarantees; architecture-specific analyses (attention, MoE, convs)
- Mechanistic interpretability of trap modes
- What: Map trap eigenvectors to circuits/features (e.g., prototype directions in MLPs, heads/MLP neurons in transformers) to understand failure mechanisms
- Dependencies: Cross-model alignment methods; standardized probe suites
- RL and sim-to-real generalization monitors
- Sectors: robotics, operations research
- What: Use trap onset as a sim-overfitting detector in long-horizon RL; guide domain randomization
- Dependencies: Efficient online spectral estimates; relationship to policy performance variance
Policy and Compliance
- Regulatory evaluation protocols based on weight-only diagnostics
- What: Standardize MP-fit/trap-count procedures as part of safety filings where data cannot be disclosed; require “trap trend” telemetry across training
- Potential tools: Reference implementations, calibration datasets, audit templates
- Dependencies: Agreement on acceptable thresholds; documented false-positive/negative rates; sector-specific guidelines
- Insurance and risk underwriting signals
- Sectors: insurers of AI systems, critical infrastructure
- What: Incorporate trap metrics into underwriting models as one input for model robustness risk
- Dependencies: Longitudinal evidence tying trap profiles to incident rates
Daily Life (Practitioners and Small Teams)
- “Trap-aware” educational curricula and kits
- What: Teaching modules and labs on MP fits, TW edges, and trap ablations; hands-on toolkits to visualize anti-grokking
- Dependencies: Simplified, fast approximations for laptops; curated examples spanning MLP/Transformer/conv
- On-device/private scans for consumer AI apps
- What: Local, data-free trap checks to vet plug-in LLMs or edge models without uploading private data
- Dependencies: Mobile/edge-optimized spectral routines; UX for interpreting risk signals
Notes on Assumptions and Dependencies (cross-cutting)
- Access: Methods require read access to full model weights; closed models cannot be scanned.
- Compute: SVD/eigendecomposition per layer can be expensive for very large models; scalable approximations (randomized SVD, sketching) may be needed.
- Calibration: MP/TW edge fitting and trap thresholds require per-architecture calibration; quantization/pruning may affect spectra.
- Scope: Trap counts are indicative of potential overfitting (anti-grokking) but are not a universal “model quality” or “safety” score; pair with task evals.
- Classification: JSD ablation uses random probes; best interpreted within-model to prioritize traps; harmful vs. benign determination still benefits from downstream tests.
- Layer types: Convolutions, attention, and MoE require appropriate reshaping and layer-specific handling for meaningful spectra.
- Interventions: Removing traps can hurt performance if they encode useful structure; mitigation should be coupled with evaluation and rollback plans.
These applications translate the paper’s main innovations—weight-only trap detection via shuffled-spectrum MP fits and data-free JSD trap classification—into actionable tools for selecting, training, auditing, and governing modern neural models.
Glossary
- Anderson localization: A physics concept where eigenmodes become spatially localized, used as an analogy for traps concentrated on few coordinates. "This is analogous to Anderson localization: an eigenmode is spatially or coordinate-localized, so the relevant variance is supported on only a few degrees of freedom."
- anti-grokking: A post-generalization training phase where test accuracy degrades while train accuracy remains high. "We call this post-generalization regime anti-grokking."
- Bose–Einstein condensation: A physics analogy for variance concentrating into a single spectral mode. "The corresponding physics analogies are Anderson localization, Bose--Einstein condensation, and the Curie--Weiss mean-field model of magnetization"
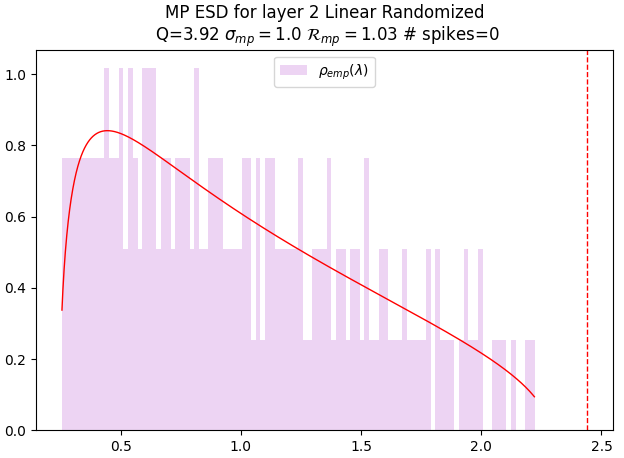
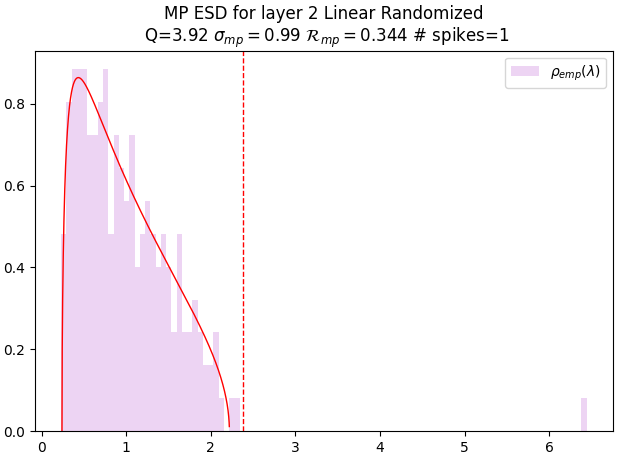
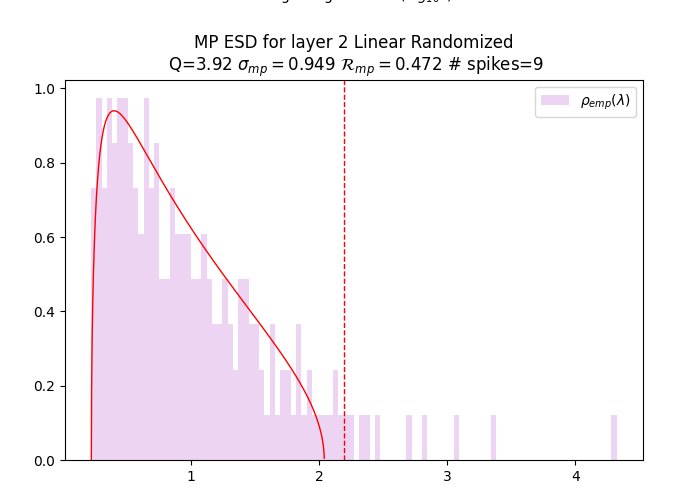
- Correlation Traps: Large right-edge spectral outliers in randomized layer spectra that indicate non-self-averaging structure and potential overfitting. "We call these outliers Correlation Traps."
- Curie–Weiss mean-field model: A physics model used as an analogy for spectral condensation (a single dominant eigenmode). "The corresponding physics analogies are Anderson localization, Bose--Einstein condensation, and the Curie--Weiss mean-field model of magnetization"
- Delocalization: The property that eigenvector components are spread out rather than concentrated, expected under the MP baseline. "Also, and importantly, the MP singular and/or eigenvectors are delocalized with randomly distributed components."
- Empirical risk: The average loss over samples, used to discuss self-averaging of generalization error. "For the empirical risk , one defines the variance and covariance:"
- Empirical spectral density (ESD): The distribution of eigenvalues of a matrix (here, layer covariances). "The empirical spectral density (ESD) is"
- Entry-wise shuffling: Randomizing the entries of a weight matrix to form a null model for spectral analysis. "Shuffle the entries elementwise to form $\mathbf{W}^{\mathrm{rand}$."
- Grokking: A phenomenon where generalization appears abruptly long after training accuracy saturates. "In grokking, training accuracy reaches near perfection while test accuracy stays near chance for many optimization steps, before abruptly improving~\citep{power2022grokking}."
- Heavy-tailed: Describing spectra or distributions with substantial mass in the tails, used in prior spectral diagnostics of weights. "Prior spectral diagnostics use heavy-tailed structure of the correlated (unrandomized) layer weight matrices , and related metrics to characterize trained networks."
- Jensen–Shannon divergence (JSD): A symmetric divergence used here to measure output changes after trap ablation without data. "measure the Jensen--Shannon divergence between their output distributions."
- Localization: Concentration of an eigenvector’s mass on a small subset of coordinates, undermining self-averaging. "A trap mode may be localized in coordinates."
- Marchenko–Pastur (MP) law: The limiting spectral density for random covariance matrices, used as the self-averaging baseline. "If the entries of are i.i.d.\ and well behaved, then in the limit , with fixed, $\rho_{\mathrm{emp}(\lambda)$ converges to the Marchenko--Pastur density"
- MP right edge: The upper edge of the MP bulk; outliers beyond it indicate structured deviations. "We define Correlation Traps as outliers to the MP/TW right-edge in shuffled layer spectra."
- Non-self-averaging: When statistics are dominated by a few directions or modes and fail to concentrate. "Large spectral outliers represent non-self-averaging structure: a small number of directions dominate the statistics."
- Porter–Thomas distribution: The expected distribution of components of delocalized eigenvectors under the MP baseline. "The bulk MP vector components will follow a PorterâThomas distribution~\cite{porter1956fluctuations, potters2021first}."
- Random Matrix Theory (RMT): A framework for analyzing spectra of large random matrices, used to detect overfitting signatures. "We present a novel Random Matrix Theory method that detects the onset of overfitting in deep learning models without access to train or test data."
- Self-averaging: The property that fluctuations of observables vanish relative to their mean in large systems. "Self-averaging is the statistical-mechanics analogue of concentration."
- Spectral condensation: A failure mode where variance concentrates into one (or few) very large eigenvalue(s), even with diffuse eigenvectors. "A trap may also be diffuse in coordinates but dominant in spectrum."
- Spin-glass-like phase: A regime from statistical physics invoked to describe overfitting behavior with many metastable states. "In either case, the presence of traps aligns with classic notions of overfitting that occur in the spin-glass-like phase(s) of simple statistical mechanics models of NNs."
- Tracy–Widom (TW) fluctuations: The finite-size fluctuations of the largest eigenvalue around the MP right edge. "At finite , the right edge lives within the scale of the Tracy-Widom (TW) fluctuations."
- Weight decay: An explicit regularization technique that reduces overfitting and suppresses trap growth. "Weight decay does not eliminate the three phases entirely, but it reduces both the number of traps and the extent of the late-stage test degradation"
- WeightWatcher: An open-source tool that implements random-matrix-based analyses for neural-network layers. "The open-source WeightWatcher tool (WeightWatcher) implements several random-matrix-based analyses of neural-network layers"
Collections
Sign up for free to add this paper to one or more collections.