- The paper introduces a hierarchical model with layer-wise spectral recovery that sequentially learns latent features from high-dimensional data.
- It demonstrates that sharp, feature-wise learning transitions combine to produce smooth power-law generalization curves in deep networks.
- The results establish a sample complexity gap where depth-based methods significantly outperform shallow kernel approaches.
Scaling Laws from Sequential Feature Recovery in Hierarchical Feature Learning
Problem Setting and Motivation
The paper "Scaling Laws from Sequential Feature Recovery: A Solvable Hierarchical Model" (2605.14567) develops a mathematically tractable model to investigate the origins of neural scaling laws through the lens of feature learning in multi-layer (hierarchical) architectures. Specifically, it addresses whether observed power-law generalization curves in deep learning can emerge from sequential recovery of latent features, rather than arising purely from fixed spectral bias as seen in kernel methods.
The authors construct a compositional, high-dimensional regression task requiring the recovery of a set of nonlinear latent features, whose associated strengths decay as a power law. They introduce a corresponding layer-wise spectral learning algorithm and rigorously analyze the sample complexity for feature recovery at each layer and direction. This framework yields explicit predictions for the aggregate generalization error, connecting the cascade of sharp feature-wise learning transitions to smooth power-law scaling in the mean-squared error (MSE).
Hierarchical Model Construction and Spectral Algorithm
The target function is a composition of two nonlinear layers. The first layer projects the input onto d1=dε randomly chosen, high-order Hermite features in a D=Θ(dq) dimensional space, where q≥2 controls the degree of nonlinearity, and ε tunes the intermediate representation's dimension. The second layer applies a diagonal, power-law weighted nonlinearity to these intermediate features, with weights λi∝i−γ and a normalization ensuring unit output variance.
The layer-wise spectral recovery algorithm proceeds as follows:
- First Layer: Estimates the teacher subspace through the top-d1 eigenvectors of a centered empirical Hermite moment matrix constructed from the labelled data.
- Second Layer: Fits the weights for the output nonlinearity by regressing on the recovered latent basis.
- Readout: Applies a further (possibly nonlinear) readout on the scalar second-layer representation.
The bottleneck for high-dimensional generalization is the sequential weak recovery of first-layer teacher directions—a process governed by the power-law spectrum of feature strengths.
Theoretical Results: Feature Recovery Transitions and Scaling Laws
The recovery of each latent direction is shown to occur via a sharp spectral transition, with the k-th direction becoming weakly detectable when the sample size n exceeds dqk2γ/Zγ2. This is formalized via a finely-tuned perturbation analysis of empirical eigenvectors that goes beyond classical Davis–Kahan bounds, yielding matching upper and lower sample-complexity thresholds for individual feature discovery.
Strong claims of the paper:
- Sequential feature recovery: Stronger teacher directions are reliably learned at much smaller sample sizes, while weaker directions require more data.
- Sample complexity rate: For anisotropy exponent γ>1/2, the MSE decays as D=Θ(dq)0 for identity readouts; for D=Θ(dq)1 a plateau appears until D=Θ(dq)2 reaches D=Θ(dq)3.[(2605.14567), Defilippis et al. (Defilippis et al., 5 Feb 2026)]
- Separation from shallow-kernel scaling: Depth-exploiting spectral methods achieve \emph{lower} sample complexity than kernel or random-feature baselines, which are limited by the global polynomial degree (D=Θ(dq)4).
Feature-wise dynamics are summarized as follows:
- Let D=Θ(dq)5, then the sample threshold for recovering direction D=Θ(dq)6 is D=Θ(dq)7.
- At finite D=Θ(dq)8, the unrecovered tail dominates the MSE. For summable spectra (D=Θ(dq)9), q≥20.
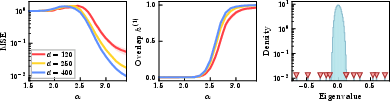
Figure 1: Feature-wise MSE, direction overlap, and spectrum, showing sequential emergence and spectral separation for a power-law q≥21.
Numerical Experiments
The numerical results robustly confirm the theoretical predictions:
- Sequential spikes: Spectral outliers in the empirical moment matrix emerge in the order of teacher direction strengths, as expected.
- Aggregate scaling: The generalization MSE exhibits smooth decay as predicted by the unlearned spectrum tail.
- Effect of anisotropy: Increasing q≥22 causes a wider spread in feature recovery thresholds, leading to more gradual aggregate MSE decay.
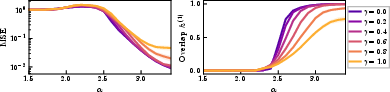
Figure 2: Generalization curves for varying power-law exponent q≥23, confirming the widening of the recovery window and predicted slow-down as q≥24 increases.
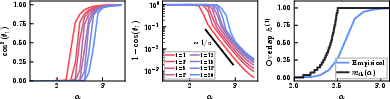
Figure 3: Direction-wise feature overlaps: higher-ranked features are resolved first as q≥25 increases, with the staircase-like activation sequence rounded by finite-size effects.
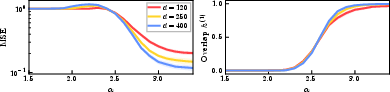
Figure 4: Nonlinear readout (q≥26): MSE and feature overlaps show that the qualitative transition mechanism holds for non-identity output nonlinearities.
The results further delineate the difference between hierarchical adaptive predictors and non-adapted kernel baselines, empirically demonstrating the sample complexity gap driven by compositional structure.
Implications and Theoretical Significance
The analysis provides a rigorous mechanism for the emergence of smooth power-law scaling from a sequence of discontinuous transitions in feature learning. This directly challenges the notion that scaling laws are a legacy of fixed representations, and instead connects their origins to the progressive organization and sequential recovery of features across depth—a dynamic invisible to classic kernel or linearized models [Defilippis et al. (Defilippis et al., 5 Feb 2026); Ren et al. (Ren et al., 28 Apr 2025)].
Practical implications:
- For architectures (or tasks) where hidden features are hierarchically composed and anisotropically distributed, deep or compositional learning methods can sharply outperform shallow approaches in data efficiency.
- Observed power-law scaling curves can be interpreted as the envelope of many sharp, feature-wise learning transitions rather than as gradient descent over a static spectrum.
Methodological significance:
- The resolvent-based perturbation analysis enables sharp recovery thresholds in regimes with diminishing spectral gaps—generally inaccessible via Davis–Kahan techniques.
- The approach may inform provable feature learning limits in broader settings and offer guidance for principled architecture design where compositional hierarchy is present.
Outlook and Future Directions
The framework is limited to settings with:
- Explicitly hierarchical compositional structure,
- Gaussian inputs,
- Spectral (layer-wise) rather than end-to-end optimization.
Extending the mechanism to more generic data, richer nonlinearities, higher information exponents, and full gradient-based training is suggested as a future direction. These results support the hypothesis that observed empirical scaling laws in large-scale models reflect not merely the eigenstructure of fixed feature maps, but the cumulative effect of staged, anisotropic feature learning throughout depth.
Conclusion
This work delivers a solvable model rigorously linking sequential feature recovery to scaling laws in hierarchical learning, thereby providing a concrete mechanism for the emergence of power-law generalization curves from compositional and anisotropic signal structure. The technical advances in sample complexity analysis of high-dimensional spectral methods may spur further advances in understanding learning dynamics well beyond kernel and random-feature regimes.
References:
- "Scaling Laws from Sequential Feature Recovery: A Solvable Hierarchical Model" (2605.14567)
- "Optimal scaling laws in learning hierarchical multi-index models" (Defilippis et al., 5 Feb 2026)
- "Emergence and Scaling Laws in SGD Learning of Shallow Neural Networks" (Ren et al., 28 Apr 2025)