Deep Learning as Neural Low-Degree Filtering: A Spectral Theory of Hierarchical Feature Learning
Abstract: Understanding how deep neural networks learn useful internal representations from data remains a central open problem in the theory of deep learning. We introduce Neural Low-Degree Filtering (Neural LoFi), a stylized limit of gradient-based training in which hierarchical feature learning becomes an explicit iterative spectral procedure. In this limit, the dynamics at each layer decouple: given the current representation, the next layer selects directions with maximal accessible low-degree correlation to the label. This yields a tractable surrogate mechanism for deep learning, together with a natural kernel-space interpretation. Neural LoFi provides a mathematically explicit framework for studying multi-layer feature learning beyond the lazy regime. It predicts how representations are selected layer by layer, explains how emergence of concepts arises with given sample complexity,and gives a concrete mechanism by which depth progressively constructs new features from old ones through low-degree compositionality. We complement the theory with mechanistic experiments on fully connected and convolutional architectures, showing that Neural LoFi improves over lazy random-feature baselines, recovers meaningful structured filters, and predicts representations aligned with early gradient-descent feature discovery with real datasets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deep Learning as “Neural Low‑Degree Filtering” — A Simple Explanation
Overview: What is this paper about?
This paper offers a new, easy-to-analyze way to understand how deep neural networks learn. The authors introduce “Neural Low‑Degree Filtering” (Neural LoFi), which views each layer of a deep network as a simple two-step process:
- find the most useful, easy-to-spot patterns related to the labels (the answers), and
- turn those patterns into a new set of features for the next layer to build on.
Think of it like using a smart sieve: each layer filters out the most helpful grains of information, then reshuffles them so the next layer can find slightly more complex patterns. Over many layers, the network builds up powerful representations from simple pieces.
Objectives: What questions are they trying to answer?
The paper focuses on four big questions, phrased in everyday terms:
- Which features (patterns) does a deep network discover as it trains?
- In what order do those features appear?
- How much data do you need before a new, meaningful feature “pops out” from the noise?
- Why does having many layers (depth) help learn complicated tasks more efficiently than a single layer?
Approach: How does Neural LoFi work?
Neural LoFi is a stylized, math-friendly stand-in for how real deep nets learn early in training. Each layer runs two steps:
- Filter (find useful directions):
- The method builds a special “label-weighted” matrix from the current features and the labels (answers).
- It then finds the top “eigenvectors” of that matrix. In plain terms, these are the directions in feature space that line up best with the task — the strongest, most informative patterns you can detect with simple relationships (like linear or quadratic).
- You can think of this like a music equalizer that boosts the most important frequencies: the filter step boosts the most label-relevant directions.
- Lift (make new features to search again):
- After picking those useful directions, the method runs them through a random nonlinearity to create a fresh, richer feature set.
- This gives the next layer new coordinates where different simple signals may become visible.
Why “low-degree”?
- “Low-degree” means simple relationships with the labels — like linear (degree 1) or quadratic (degree 2) patterns — not complicated tangled ones. Neural LoFi specifically looks for these simple correlations because they are easiest to detect with limited data and early in training.
What is the “kernel” viewpoint (in simple words)?
- A “kernel” is just a way to measure similarity between examples. Neural LoFi constructs a new, task-adapted similarity at each layer based on the features it finds. So instead of using one fixed similarity measure, the network keeps updating it, layer by layer, to better match the task.
How does it relate to real training?
- The authors argue that very early in training (with small initial weights), gradient descent behaves a lot like this filtering process: directions with the strongest label-linked signals grow fastest. Neural LoFi captures that with a clear, step-by-step procedure.
Key terms in plain language:
- Eigenvectors/eigenvalues: The main “directions” and their “strengths” inside a matrix; think of them as the most revealing viewpoints for seeing structure in your data.
- Spectral: Working with those directions and strengths (like using a prism to separate light into its most important colors).
- Effective dimension: How many directions still matter after you’ve already picked some; it’s a way to measure how much useful variation is left to find.
- Emergence threshold: The point at which a real pattern becomes strong enough to stand out from noise, given how much data you have.
Findings: What did they discover and why does it matter?
The authors report five main insights.
- A simple, predictive rule for what gets learned next:
- At each layer, the network picks features that are both simple (not too “complex” in the current geometry) and strongly tied to the labels through low-degree signals. This explains the sequence in which features appear.
- A clear “feature emergence” threshold:
- A new feature becomes learnable when its true signal rises above the noise you expect from a finite dataset. The paper gives a formula (using “effective dimension”) to estimate when that happens. In short: enough data makes the useful signal pop out.
- Why depth helps (low-degree compositionality):
- Deep models don’t solve a complicated problem in one go. Instead, each layer turns a hard problem into several easier ones by making the next piece of the structure visible through a simple (low-degree) statistic. Complex patterns become learnable step by step.
- Adaptive kernels across layers:
- Rather than choosing one fixed way to measure similarity before seeing labels, the method builds a sequence of label-aware similarity measures. This shows deep learning as “adaptive kernels,” updated after each layer to better fit the task.
- Matches early training and finds meaningful features in practice:
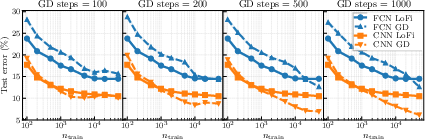
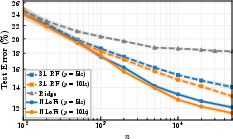
- Experiments on fully connected and convolutional networks (e.g., on CIFAR-10) show Neural LoFi can match or even beat early gradient-descent performance in low-data settings, recover structured filters, and predict early feature discovery seen in real training.
Why is this important?
- It offers a clear, testable theory for how features are learned layer by layer.
- It gives a way to predict how much data you need for certain concepts to appear.
- It explains how depth transforms a complicated task into a series of simpler ones.
Impact: What could this change?
- Better understanding of deep learning: Neural LoFi provides a simple story for hierarchical feature learning — which features appear, in what order, and why.
- Practical tools: Because it’s backpropagation-free and layerwise, it could inspire faster, more interpretable training methods or pretraining steps that discover good features quickly.
- Smarter data use: The emergence threshold can guide how much data is needed to learn specific concepts, helping plan data collection and model size.
- Design and pruning: The method’s “filter then lift” view supports building wide models to discover features, then keeping only the directions data can reliably support (which aligns with effective pruning).
- Bridges theory and practice: It connects kernel methods and deep learning into one picture, and resonates with physics ideas like coarse-graining — keeping only what matters at each scale.
In short, Neural LoFi turns the messy process of deep learning into a clean, layered routine: find simple, label-relevant patterns; re-express them; repeat. That not only helps explain why deep nets work so well, but also suggests practical, efficient ways to build and analyze them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues that emerge from the paper’s theory, algorithm, and experiments. Each point is phrased to facilitate concrete follow-up work.
- Validity of the layerwise decoupling assumption: Precisely delineate initialization scales, step sizes, widths, and time horizons under which the “Neural LoFi regime” (small-initialization, early-time, per-layer/neurons decoupling) accurately approximates gradient descent beyond the informal Proposition and toy settings.
- Beyond early-time dynamics: Characterize how well LoFi-predicted feature directions persist under continued training, larger step sizes, and practical initializations (e.g., He/Xavier), including when weight decay, momentum, and stochasticity (SGD noise) are present.
- Indefinite operator behavior: Analyze the spectral properties and stability of the label-weighted operator when it is indefinite. Specify when selecting by is beneficial vs harmful, how to handle negative eigenvalues, and how sign/centering choices impact learned features in regression vs classification.
- Rank selection per layer: Develop data-driven, theoretically grounded procedures to choose (e.g., thresholds tied to the residual effective dimension or BBP-like gaps), with finite-sample guarantees against overfitting and instability.
- Robust estimation of the emergence threshold: Provide practical, statistically consistent methods to estimate the residual effective dimension and the noise floor from finite samples (including deflation), with confidence intervals and sensitivity analyses.
- Tightness and constants in emergence bounds: Sharpen the local Rademacher–complexity–based emergence criterion by identifying tight constants, dependence on activation, and finite-width corrections; validate BBP-like predictions under non-Gaussian, heavy-tailed, or structured data.
- Choice of spectral weighting vs top‑: Systematically study how different spectral weightings (e.g., soft weights, early-stopped power iterations) relate to actual GD trajectories, and map regimes where each yields the best alignment with trained models.
- Random nonlinear lift design: Specify activation and random-lift distributions that provably preserve and amplify low-degree signal while controlling complexity; quantify how choices of and affect the recursion and generalization.
- Finite-width effects and rates: Establish convergence rates of learned features to infinite-width limits (Theorem conditions assume separation and pseudo-Lipschitz ), and characterize failure modes when eigenvalues are clustered or multiplicities are high.
- Stability of orthogonalization/deflation: Analyze numerical and statistical stability of sequential selection (linear then second-order features) under label noise, class imbalance, and near-degenerate spectra; propose robust deflation schemes.
- Multi-class and multi-label outputs: Extend the operator and variational characterization beyond scalar to vector-valued labels with rigorous derivations, including how to aggregate class-specific operators and preserve task structure.
- Incorporation of common architectural components: Assess how batch normalization, residual/skip connections, layer normalization, and attention mechanisms alter the LoFi operator, the RKHS geometry, and the predicted feature selection.
- Convolutional specifics: Formalize the “read locally” variant for CNNs (patch-wise operators, weight sharing, pooling), including how spatial averaging interacts with the label-weighted spectrum and how to exploit equivariances.
- Applicability to transformers and attention: Determine whether an analogous low-degree spectral operator exists for attention layers and whether LoFi predicts empirically observed spectral “spikes” in trained attention weights.
- Scalability and approximate eigensolvers: Provide streaming/online and distributed algorithms (e.g., Oja/Sanger updates, randomized sketches) to compute top eigendirections at large , with complexity/accuracy trade-offs.
- Higher-order LoFi: Develop practical surrogates for third- and higher-degree feature discovery (beyond ), e.g., tensor sketches/approximations or iterative multi-pass variants, with clear computational and statistical guarantees.
- Multi-pass LoFi and residualization: Formalize a multi-pass version that alternates spectral filtering with label/residual transformations to overcome low-degree limitations; relate its learnability to information/leap/generative exponents.
- Interaction across layers (nonlocal coupling): Quantify the error incurred by ignoring cross-layer interactions during training; identify conditions where such interactions materially change which features emerge and when.
- Generalization guarantees for the full pipeline: Move beyond surrogate interpretations to give end-to-end generalization bounds for the LoFi-trained predictor, accounting for layerwise selection, random lifts, and final readout.
- Robustness to label noise and distribution shift: Analyze the sensitivity of the label-weighted operator to noisy/miscalibrated labels and shifts in or , and propose robustified operators (e.g., reweighting, trimming, calibration).
- Data augmentation and invariances: Study how augmentations affect the empirical operator spectrum and whether LoFi can leverage invariances (or learn them) across layers in a theoretically controlled way.
- Empirical breadth and benchmarks: Expand evaluation beyond binary CIFAR-10 and early training to multi-class vision (e.g., ImageNet), NLP, and speech; quantify alignment with GD across stages, architectures, and datasets.
- Comparison to alternative surrogates: Provide controlled comparisons to AGOP/Recursive Feature Machines and rainbow analyses on the same tasks to determine when each surrogate best predicts learned features.
- Retention vs forgetting across layers: Determine whether the random lift preserves previously discovered low-degree features or induces “catastrophic forgetting”; design lifts that guarantee retention while enabling new feature discovery.
- Centering and first-order terms: Clarify when to include vs drop the linear component ; analyze its contribution across tasks and how centering choices affect second-order feature selection.
- Handling class imbalance and scaling of : Provide principled scaling/normalization strategies for in the operator to avoid biasing the spectrum toward dominant classes or large-magnitude labels.
- Task-dependent kernel recursion: Give conditions under which the adaptive kernel sequence strictly improves learnability over any fixed kernel, and quantify depth-dependent sample-complexity gains.
- Theoretical characterization of “low-degree compositionality”: Turn the qualitative principle into precise necessary/sufficient conditions for depth advantages in broad function classes, beyond the solvable polynomial toy model.
- Practical pipelines for RKHS computations: Specify numerically stable, memory-efficient procedures to compute the RKHS-constrained variational problems at scale (e.g., Nyström approximations, inducing points), including error control.
- Inductive biases of the operator: Investigate whether favors high-variance or spurious features and whether whitening or task-conditioned preconditioning improves signal-to-noise.
- Integration with self-supervised and semi-supervised settings: Extend LoFi to cases where labels are scarce or absent; identify analogous operators driven by pseudo-labels, contrastive targets, or teacher signals.
- Fairness and subgroup performance: Assess whether label-weighted spectral filtering amplifies subgroup-specific correlations; propose constraints or multi-objective operators to control disparate impacts.
- Public reproducibility and ablations: Provide comprehensive ablations for choices of , nonlinearity, deflation, centering, and spectral thresholds to guide practitioners in deploying LoFi on new tasks.
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and tooling (e.g., the public implementation linked in the paper and standard ML libraries), often as add-ons to existing pipelines.
- Backpropagation-free, layerwise spectral pretraining for low-data regimes
- Sectors: healthcare (medical imaging with limited labels), geospatial/remote sensing, industrial quality control, cybersecurity (anomaly detection), finance (limited historical labels).
- What it does: Replace early-stage end-to-end training with Neural LoFi’s two-step loop per layer (label-weighted spectral filtering + random nonlinear lift) to extract task-relevant features with fewer labels and less compute, then fit a linear/logistic readout.
- Tools/workflows: A “LoFi pretrainer” module callable per layer; integrate with PyTorch/JAX as a feature extractor; workflow = compute label-weighted moment operator, take top-k eigenvectors, project features, apply random feature nonlinearity, fit readout.
- Assumptions/dependencies: Labels (or weak labels) are available; eigendecomposition on per-layer feature covariance is tractable; feature dimension per layer not too large or handled with randomized SVD/mini-batch approximations; performance strongest where early GD also shines (low-data/early training).
- Adaptive kernel construction for small/medium datasets
- Sectors: classical ML settings across domains (education analytics, marketing analytics, tabular biomedical cohorts, materials discovery).
- What it does: Build a sequence of task-adaptive kernels layer-by-layer using LoFi’s RKHS variational characterization, outperforming fixed kernels in label-efficiency and representation fit.
- Tools/workflows: Use kernel LoFi recursion to create K0 → K1 → … → KL; drop-in for kernel SVM/ridge pipelines; Nystrom/random-feature approximations for scalability.
- Assumptions/dependencies: Kernel computations scale as O(n2) memory/time unless approximated; requires a clear rank-selection rule (e.g., BBP-inspired noise-floor threshold).
- Data-driven “concept emergence” monitoring and early-stopping/pruning
- Sectors: MLOps, safety/compliance, regulated industries (healthcare, finance).
- What it does: Track spectral spikes of the label-weighted operator per layer to detect when a new feature becomes statistically learnable; use residual effective dimension and noise-floor thresholds to choose k per layer, schedule early stopping, and prune.
- Tools/workflows: An “Emergence Monitor” dashboard reporting eigenvalue spikes vs. bulk, residual effective dimension estimates, and predicted sample thresholds; pruning retains only learned directions.
- Assumptions/dependencies: Reliable estimation of noise floor and spectral gaps; stable data distribution; sufficient width so that informative spikes are not lost in bulk.
- Fast, memory-efficient training on edge devices (local/biologically inspired updates)
- Sectors: robotics, IoT, on-device personalization, AR/VR.
- What it does: Replace backprop with layerwise spectral updates approximated by local Hebbian/Oja-style rules modulated by labels; greatly reduces memory traffic and backward-pass complexity.
- Tools/workflows: Implement label-modulated streaming estimates of the moment operator; periodic power iterations for top-k eigenvectors; random-feature lifts.
- Assumptions/dependencies: Requires stable streaming SVD/PCA approximations; label availability on-device or occasional supervised sync; best when low-degree signal is present.
- Spectral initialization to accelerate full deep training
- Sectors: software/AI, computer vision, speech, NLP (binary or multiclass via one-vs-rest).
- What it does: Use LoFi to initialize early layers with task-aligned filters (especially for convnets), then continue with standard backpropagation to refine higher-order features.
- Tools/workflows: “LoFi warm-start” pass before SGD; select top directions and lift; initialize weights via the learned subspaces; proceed with standard training.
- Assumptions/dependencies: Small-initialization derivation motivates the approach, but warm-starting is robust; continued backprop may overwrite some structure if learning rates are high.
- Label-budget planning and active learning heuristics
- Sectors: data-centric AI across industries; R&D planning.
- What it does: Use the emergence criterion ρℓ(k) ≫ τℓk(n) to estimate how many additional labels are needed for the next layer’s feature to emerge; guide active sampling toward regimes where low-degree correlations become detectable.
- Tools/workflows: “Label-Budget Estimator” that tracks residual effective dimension and predicts when to collect more labels; integrates with pool-based active learning.
- Assumptions/dependencies: Relies on accurate uniform deviation bounds or robust proxies; assumes i.i.d.-like sampling and stationarity.
- Detection of spurious correlations and subgroup auditing
- Sectors: fairness and compliance (policy/enterprise.), healthcare triage, credit scoring.
- What it does: Analyze which directions in representation space show label-weighted spikes; audit whether spikes align with sensitive attributes or spurious patterns.
- Tools/workflows: Run LoFi operator within subgroups; compare spectra across groups; flag divergences for review.
- Assumptions/dependencies: Access to subgroup labels or proxies; interpretability requires mapping spectral directions back to input-space patterns.
- Structured, low-rank compression and pruning
- Sectors: model deployment for mobile/edge, cloud cost optimization.
- What it does: Retain top spectral directions per layer; remove bulk; export compact models with minimal performance loss.
- Tools/workflows: “LoFi Pruner” that thresholds eigenvalues by BBP-like criteria; export low-rank factorizations or distilled features.
- Assumptions/dependencies: Clear spectral separation; downstream task still captured by retained directions.
- Teaching and mechanistic interpretability aids
- Sectors: education, research labs.
- What it does: Provide a transparent, analyzable surrogate of hierarchical learning; align with “features-as-directions” paradigm; generate visualizable filters and spectra.
- Tools/workflows: Classroom labs using the public codebase; alignment tracking between LoFi features and early GD.
- Assumptions/dependencies: Classroom-scale datasets or subsets; binary or simple multiclass tasks for clarity.
Long-Term Applications
These applications require further research, engineering, or scaling to be production-ready (e.g., handling tensors, sequence models, multimodal data, or strict regulatory constraints).
- Higher-order LoFi (tensor spectral learning)
- Sectors: advanced scientific ML, genomics, materials discovery, recommendation systems (higher-order interactions).
- What it could do: Move beyond second-order y·φ2 statistics to tensor correlations, uncovering higher-degree structure that current LoFi omits.
- Tools/products: Tensor PCA/Spectral Tensor LoFi modules; specialized randomized/tensor-decomposition libraries.
- Assumptions/dependencies: Computational hardness of tensor PCA; need for robust approximations and regularization; sensitivity to noise.
- Multi-pass LoFi with residuals (boosting-like/iterative refinement)
- Sectors: general AI systems, enterprise ML platforms.
- What it could do: Alternate spectral filtering with target/residual transformations to surpass single-pass limits and align with generative-exponent learnability.
- Tools/products: “LoFi-Boost” pipeline that iteratively reweights labels/residuals and refines features over passes.
- Assumptions/dependencies: Stability of iterative procedures; theory to guide stopping criteria and degree progression.
- Automated architecture/rank search via emergence criteria
- Sectors: AutoML, MLOps.
- What it could do: Choose depth and per-layer ranks kℓ on-the-fly using noise-floor thresholds and residual effective dimension; stop adding layers when no new low-degree signal emerges.
- Tools/products: AutoLoFi NAS plugin that monitors spectra and controls depth/rank.
- Assumptions/dependencies: Reliable online estimates of effective dimension; compatible data scales and compute budgets.
- Federated and privacy-preserving LoFi
- Sectors: healthcare, finance, IoT.
- What it could do: Compute label-weighted operators locally and aggregate eigen-directions with privacy guarantees; avoid sharing raw data or full gradients.
- Tools/products: Secure aggregation of moment operators; DP mechanisms for spectral summaries.
- Assumptions/dependencies: Communication-efficient, DP-stable PCA; heterogeneous client distributions and label scarcity.
- LoFi for sequence models and transformers
- Sectors: NLP, code, multimodal AI.
- What it could do: Adapt spectral filtering to token/patch sequences and attention blocks; identify task-adaptive low-degree subspaces before full fine-tuning.
- Tools/products: “LoFi-Transformer” pretraining modules; spectral attention initializers.
- Assumptions/dependencies: Appropriate local operators (e.g., patchwise/segment-wise); scalable blockwise SVD; extension beyond binary labels.
- Regulatory interpretability and fairness dashboards
- Sectors: policy/compliance across industries.
- What it could do: Standardize “concept emergence” reports per layer; document when features become learnable, how many labels were needed, and which subspaces drive decisions.
- Tools/products: Compliance-grade “Emergence & Spectral Audit” dashboard integrated with model cards.
- Assumptions/dependencies: Accepted standards for spectral interpretability; mapping spectral directions to human-interpretable concepts; subgroup labels.
- Neuromorphic/accelerated hardware for LoFi
- Sectors: edge AI hardware, low-power devices.
- What it could do: Implement label-modulated Hebbian/Oja updates and fast eigensolvers/random-feature lifts on-chip; low-power training without backprop.
- Tools/products: LoFi co-processors; analog crossbar PCA updates; on-device random-feature generators.
- Assumptions/dependencies: Hardware maturity; numerical stability; memory constraints for streaming covariance estimates.
- Curriculum and data-design for low-degree compositionality
- Sectors: education tech, robotics learning from demonstration, simulation-to-real.
- What it could do: Design tasks/lesson plans/demonstrations that expose low-degree signals sequentially so each layer can discover the next concept efficiently.
- Tools/products: “Compositional Curriculum Designer” that evaluates degree visibility per stage and recommends interventions.
- Assumptions/dependencies: Reliable estimation of low-degree correlations in evolving representations; domain expertise to craft curricula.
- Streaming drift detection via spectral shifts
- Sectors: MLOps, observability, monitoring.
- What it could do: Track shifts in the label-weighted spectrum and residual effective dimension over time; flag concept drift and performance risks.
- Tools/products: “Spectral Drift Monitor” for production pipelines.
- Assumptions/dependencies: Stable online PCA; noisy/imbalanced labels in streams; alert thresholds tuned to business risk.
- Domain-specific scientific discovery
- Sectors: physics (coarse-graining), neuroscience (feature hierarchies), systems biology (gene-to-phenotype).
- What it could do: Use supervised low-degree filtering to identify interpretable intermediate variables in hierarchical processes.
- Tools/products: LoFi-assisted analysis suites for scientific datasets with limited labels; integration with causal discovery tools.
- Assumptions/dependencies: Availability of clean labels or surrogates; robustness to confounding; alignment between low-degree statistics and scientific mechanisms.
Notes on common assumptions/dependencies across applications:
- The paper’s theoretical regime assumes small/vanishing initialization and early-time dynamics for the GD surrogate; LoFi works as a practical spectral approximation but may diverge from full GD at late stages.
- Second-order LoFi targets y·φ2; when higher-order structure dominates, performance may hinge on future tensor extensions.
- Rank selection kℓ benefits from spectral gap/noise-floor estimates (e.g., BBP-like thresholds) and can be automated but requires careful calibration.
- For large feature spaces or kernels, randomized SVD, Nyström, or mini-batch approximations are often necessary.
- Convolutional/local architectures require local/patchwise interpretations of the operator and pooling of estimates.
Glossary
- Average gradient outer product (AGOP): A matrix formed by averaging outer products of gradients, used to reveal salient directions for feature learning. "the average gradient outer product (AGOP) as a mechanism for feature learning"
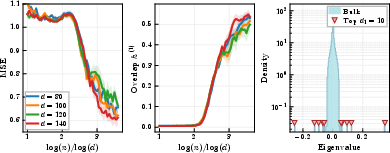
- BBP/EA-type selection mechanisms: Spectral “spike-versus-bulk” phase-transition phenomena (Baik–Ben Arous–Péché/Edwards–Jones) that determine when informative eigenvalues/eigenvectors separate from noise. "and BBP/EA-type selection mechanisms"
- Bulk-plus-spikes picture: A spectral pattern where most eigenvalues form a continuous bulk while a few informative “spike” outliers emerge, often indicating learned structure. "A related bulk-plus-spikes picture was later observed in attention models"
- Coarse-graining: A procedure that compresses high-dimensional data by keeping only task-relevant, lower-dimensional structure across scales. "Neural LoFi implements a supervised coarse-graining procedure"
- Compositional information exponent: A measure of the lowest polynomial degree at which intermediate representations carry detectable information about the target. "the {\it compositional information exponent} introduced for hierarchical Gaussian targets"
- Dynamical mean-field theory: A statistical-physics framework for analyzing large-scale learning dynamics in the infinite-width limit. "dynamical mean-field theory approaches provide a general framework for infinite-width limits"
- Eigenfunctions: Functions that diagonalize an integral operator (e.g., a kernel operator), analogous to eigenvectors for matrices. "be its eigenfunctions ordered by decreasing eigenvalue magnitude"
- Feedback alignment: A backpropagation alternative where fixed random feedback weights guide learning instead of exact gradients. "including feedback alignment and direct feedback alignment"
- Hebbian/Oja-style updates: Local learning rules where synaptic changes depend on correlations of pre- and post-synaptic activity, with Oja’s rule stabilizing Hebbian growth. "label-modulated Hebbian/Oja-style updates"
- Hermite feature vector: A collection of orthonormal polynomial features (Hermite polynomials) of specified degree for Gaussian inputs. "Let denote the degree- Hermite feature vector of the input."
- Hessian-like operator: A second-order label-weighted operator approximating curvature-driven feature-learning dynamics. "a Hessian-like, label-weighted second-order operator."
- Infinite-width limiting kernel: The deterministic kernel that arises as network layer widths go to infinity, capturing averaged feature maps. "Let denote the infinite-width limiting kernel"
- Kernel regression: A nonparametric method that fits functions via kernels, equivalent to linear regression in an implicit feature space. "training is described as kernel regression"
- Label-weighted moment operator: A spectral operator built from feature outer products weighted by labels, used to extract predictive directions. "Form the label-weighted moment operator:"
- Lazy regime: A training regime where parameters move minimally and the network behaves like a fixed kernel method (NTK), with limited feature learning. "beyond the lazy regime."
- Local Rademacher complexity: A data-dependent complexity measure controlling uniform deviations in localized function classes. "using local Rademacher-complexity bounds over "
- Low-degree compositionality: The property that each layer of a compositional target reveals a statistically detectable low-degree signal in the current representation. "This leads to a principle of {\it low-degree compositionality}"
- Matrix sensing: Recovering a low-rank matrix from linear measurements, often via convex surrogates, analogous to compressed sensing for matrices. "ERM can be mapped to matrix sensing with nuclear-norm regularization"
- Mean-field analyses: Asymptotic methods that describe learning dynamics by averaged (mean-field) equations in large networks. "Mean-field analyses of two-layer networks capture genuine parameter evolution and representation learning"
- Multi-index settings: Models where the target depends on several low-dimensional projections (indices) of the input. "single-index and multi-index settings"
- Neural Low-Degree Filtering (Neural LoFi): An iterative spectral surrogate for feature learning that selects low-degree, label-correlated directions layer by layer. "We introduce Neural Low-Degree Filtering (Neural LoFi), a stylized limit of gradient-based training in which hierarchical feature learning becomes an explicit iterative spectral procedure."
- Neural Tangent Kernel (NTK) limit: The infinite-width, small-learning-rate limit where training corresponds to kernel regression in a fixed feature space. "or equivalently in the Neural Tangent Kernel (NTK) limit"
- Nuclear-norm regularization: A convex surrogate promoting low-rank solutions by penalizing the sum of singular values. "with nuclear-norm regularization"
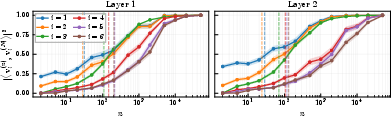
- Power iteration: An iterative method that amplifies top eigen-directions, used here to approximate projection onto leading eigenvectors. "an early-stopped power iteration will approximate hard projection onto the top- eigenvectors"
- Rainbow analysis: A post-training characterization where each layer acts like random features with learned covariances, yielding hierarchical kernels. "The rainbow analysis of \cite{guth2024rainbow} gives a post-training description of deep nets"
- Random feature map: A nonlinearly lifted embedding generated by random projections and an activation, approximating kernel features. "a nonlinear random feature map"
- Reproducing Kernel Hilbert Space (RKHS): A Hilbert space of functions associated with a kernel where evaluation is a continuous linear functional. "be its Reproducing Kernel Hilbert Space (RKHS"
- Representer theorem: A result stating that certain empirical risk minimizers in RKHS admit finite expansions in terms of kernel evaluations on training data. "Through an analogue of the classical representer theorem"
- Renormalization-inspired views: Perspectives borrowing from physics where learning is seen as iterative scale-wise simplification of representations. "renormalization-inspired views of learning across scales"
- Recursive Feature Machines: Iterative algorithms that use gradient-derived statistics (e.g., AGOP) to adaptively learn features and reduce dimensionality. "Recursive Feature Machines, iterative algorithms for adaptive feature learning and dimensionality reduction"
- Scattering transforms: Fixed multiscale cascades of wavelet filters and nonlinearities that build stable, invariant representations. "scattering transforms"
- Single-index settings: Models where the target depends on a single low-dimensional projection (index) of the input. "single-index and multi-index settings"
- Spiked matrix–tensor models: High-dimensional probabilistic models with low-rank planted structure embedded in noisy matrices/tensors, used to study spectral detection. "spiked matrix--tensor models"
- Staircase mechanisms: Multi-stage learning dynamics where successive phases unlock harder signals or reshape the target for later recovery. "through staircase mechanisms"
- Target propagation: A training alternative to backprop that propagates desired layerwise targets rather than gradients. "target propagation"
- Tensor PCA: The problem of recovering a low-rank spike in a noisy tensor; typically harder than matrix PCA. "as tensor PCA can be notably harder than matrix PCA"
- Tensor-program approaches: Analytical tools that track signal propagation in wide networks by treating computations as tensor programs. "tensor-program and dynamical mean-field theory approaches"
- Weighted principal component analysis: A PCA variant where directions are selected according to a label-dependent weighting of covariance structure. "The projection step can be interpreted as a {\it weighted principal component analysis}"
Collections
Sign up for free to add this paper to one or more collections.