- The paper introduces a five-level autonomy spectrum that maps the shift from human-led to AI-led research workflows.
- It provides a systematic survey of techniques across literature grounding, hypothesis planning, experimentation, validation, and reporting.
- The study highlights technical challenges, reproducibility gaps, and ethical implications for achieving autonomous scientific discovery.
AutoResearch AI: Conceptual and Technical Foundations for Scientific Workflow Automation
Introduction and Framing
"AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery" (2605.23204) presents a comprehensive survey and analytical framework for the emerging discipline of AI-powered research workflow automation. The authors redefine the evolution from task-level assistance (such as information retrieval or coding support) to the automation of entire scientific processes, including literature grounding, hypothesis generation, experimentation, validation, and reporting. The paper rigorously distinguishes between various autonomy regimes within research workflows, critically dissecting both technical advances and the persistent epistemic, reproducibility, and accountability gaps.
AutoResearch is formalized as a developmental spectrum, from human-only research (L0) through bounded AI assistance (L1), human-verified AI execution (L2), AI-led workflow coordination (L3), to the hypothetically fully autonomous scientific closure (L4). The analysis foregrounds that pipeline automation is not equivalent to scientific autonomy—robust closure depends on rigorous evidence propagation, reproducibility, accountable rejection, and provenance preservation.
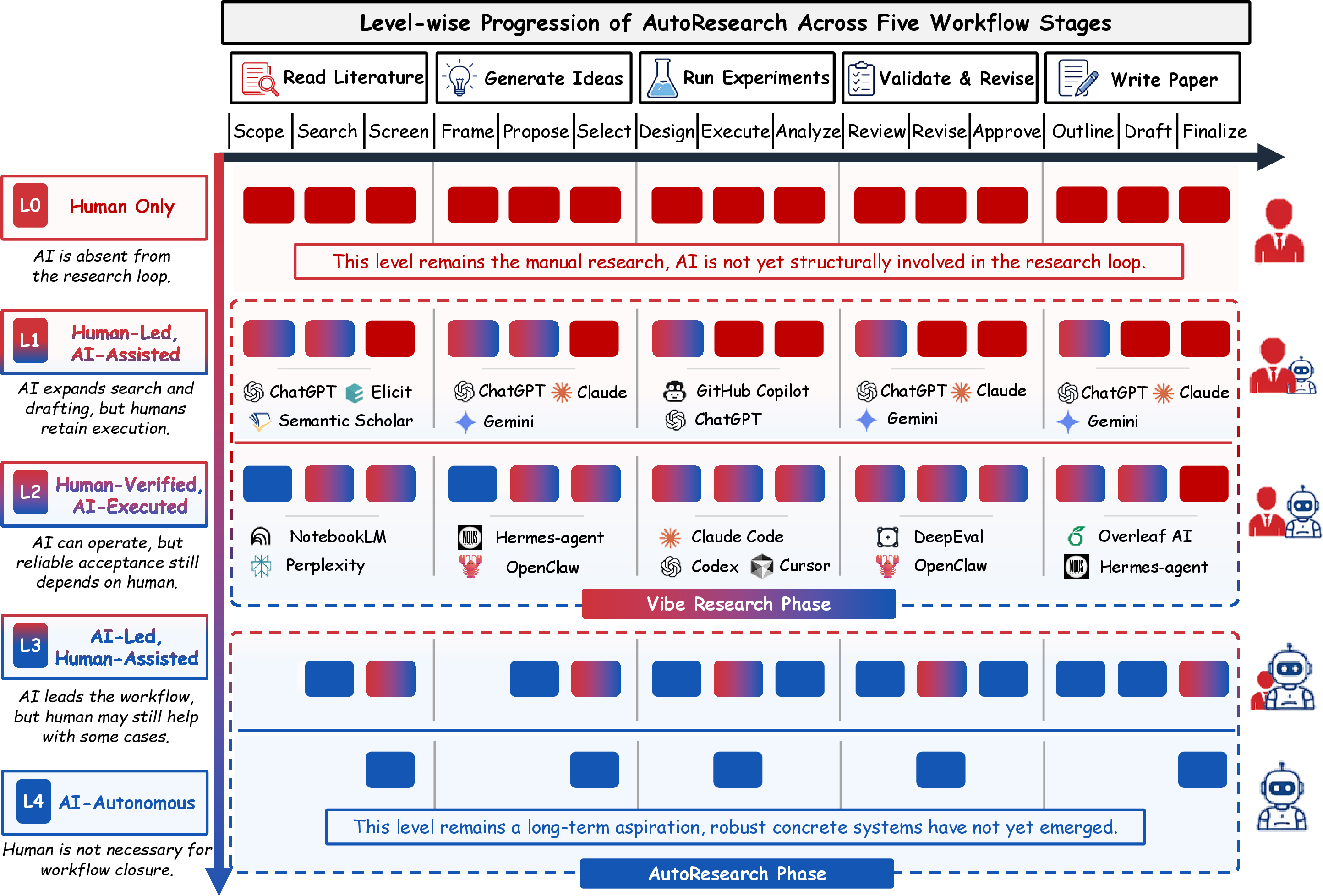
Figure 1: Level-wise decomposition of AutoResearch, illustrating the shift of human–AI responsibility across scientific workflow stages and autonomy spectrum (L0–L4).
Autonomy Spectrum and Survey Framework
A key contribution is the systematization of the workflow-centered autonomy spectrum:
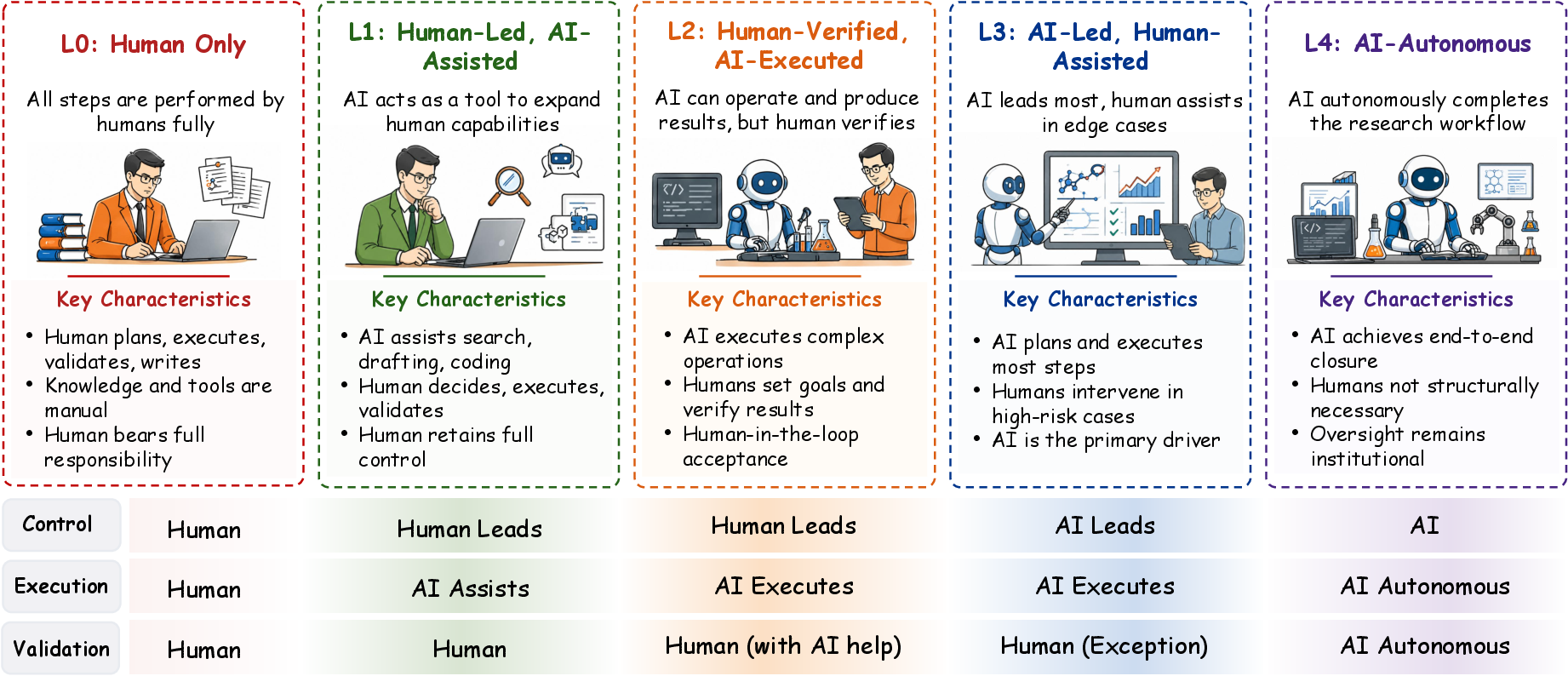
Figure 2: The five-level AutoResearch autonomy spectrum, summarized along axes of workflow control, task execution, validation authority, and scientific responsibility.
L0 denotes fully human-led inquiry; L1 introduces bounded AI assistance; L2 allows substantive AI execution but retains human validation; L3 marks AI-led workflow coordination with human assistance; L4 targets full AI autonomous research, which remains an analytical horizon. The framework underpins the survey, reframing the comparison of prior work by responsibility allocation across scientific workflows rather than by model or benchmark alone.
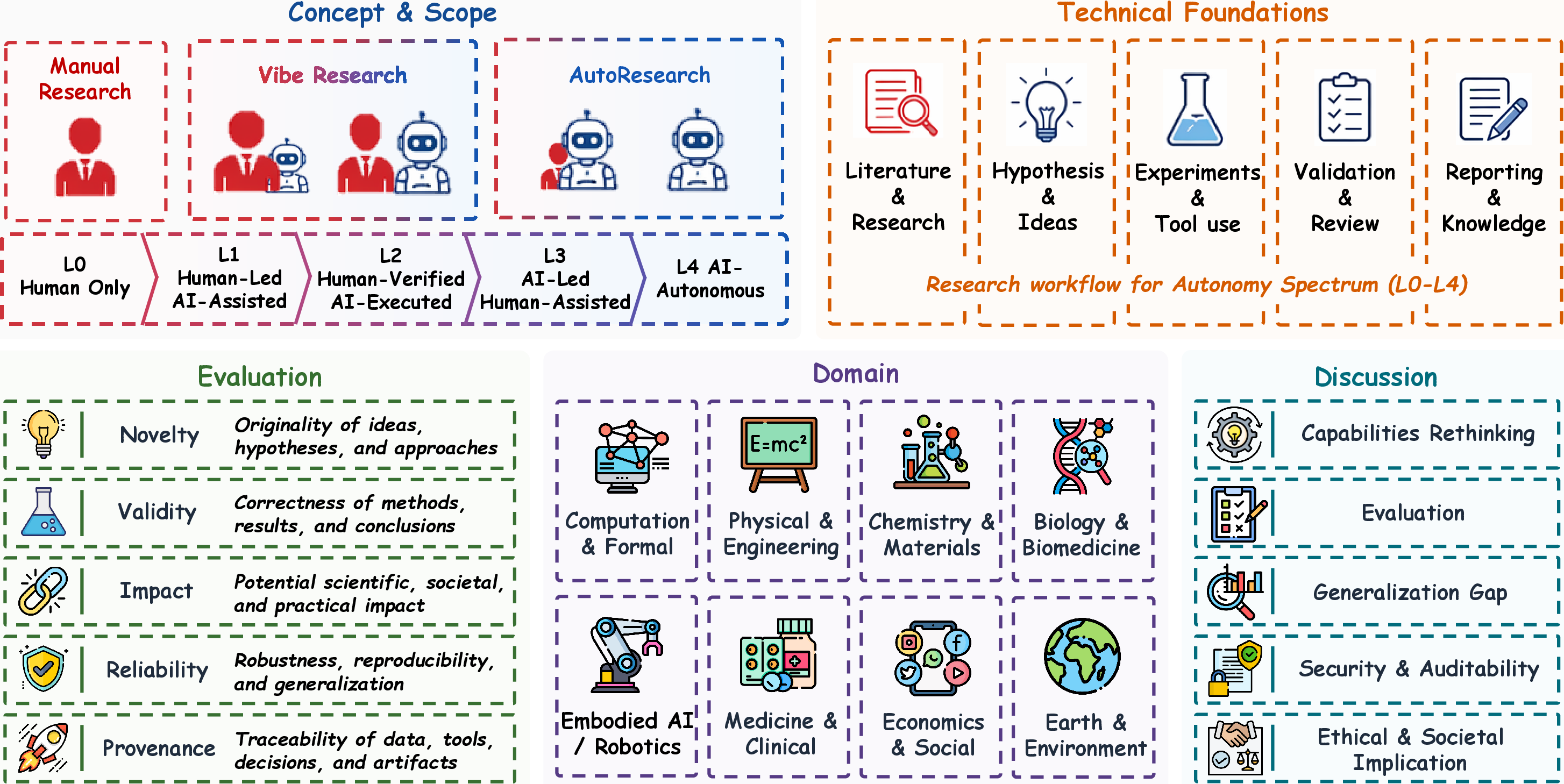
Figure 3: The AutoResearch survey framework, organizing the review around five interconnected components—concept/scope, technical foundations, evaluation, domain-specific realizations, and discussion.
Historical Trajectory and Contemporary Landscape
The paper traces the lineage from human-centered practice through niche automation to today's integrated, pipeline-based systems. Early systems emulated knowledge work; later systems demonstrated bounded execution, and the current frontier includes multi-stage pipelines under human verification. The conservative placement rule assigns systems to the lowest autonomy regime consistent with their workflow role, with integrated pipelines typically classified as advanced L2.
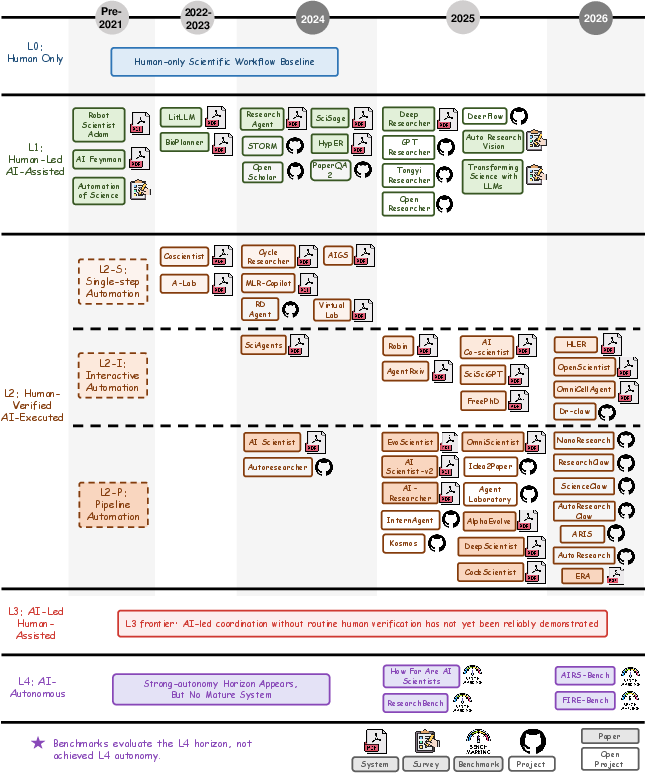
Figure 4: Historical overview mapping systems, benchmarks, and open-source infrastructure onto the L0–L4 spectrum, with L2 further subtyped.
The contemporary landscape is distributed: retrieval/synthesis assistants (L1), execution substrates (L2), co-research frameworks, and pipeline automation. Despite broad coverage, scientifically credible AI-led closure (L3/L4) is rare; current systems excel in speed and breadth of execution, but still depend heavily on human validation and judgment.
Technical Foundations: Workflow Decomposition
AutoResearch is decomposed into five recurring stages:
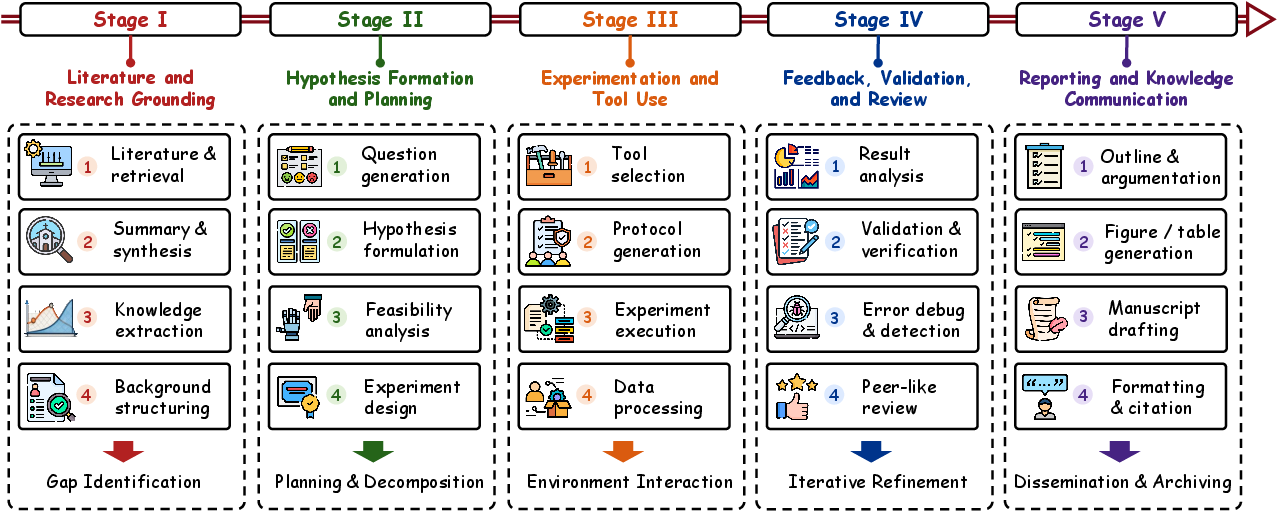
Figure 5: Decomposition of AutoResearch into five technical workflow stages: literature grounding, hypothesis planning, experimentation, validation, and reporting.
Literature Grounding
Evidence-state construction methods are compared: search-centered, evidence-centered, structure-centered, and literature-memory regimes.
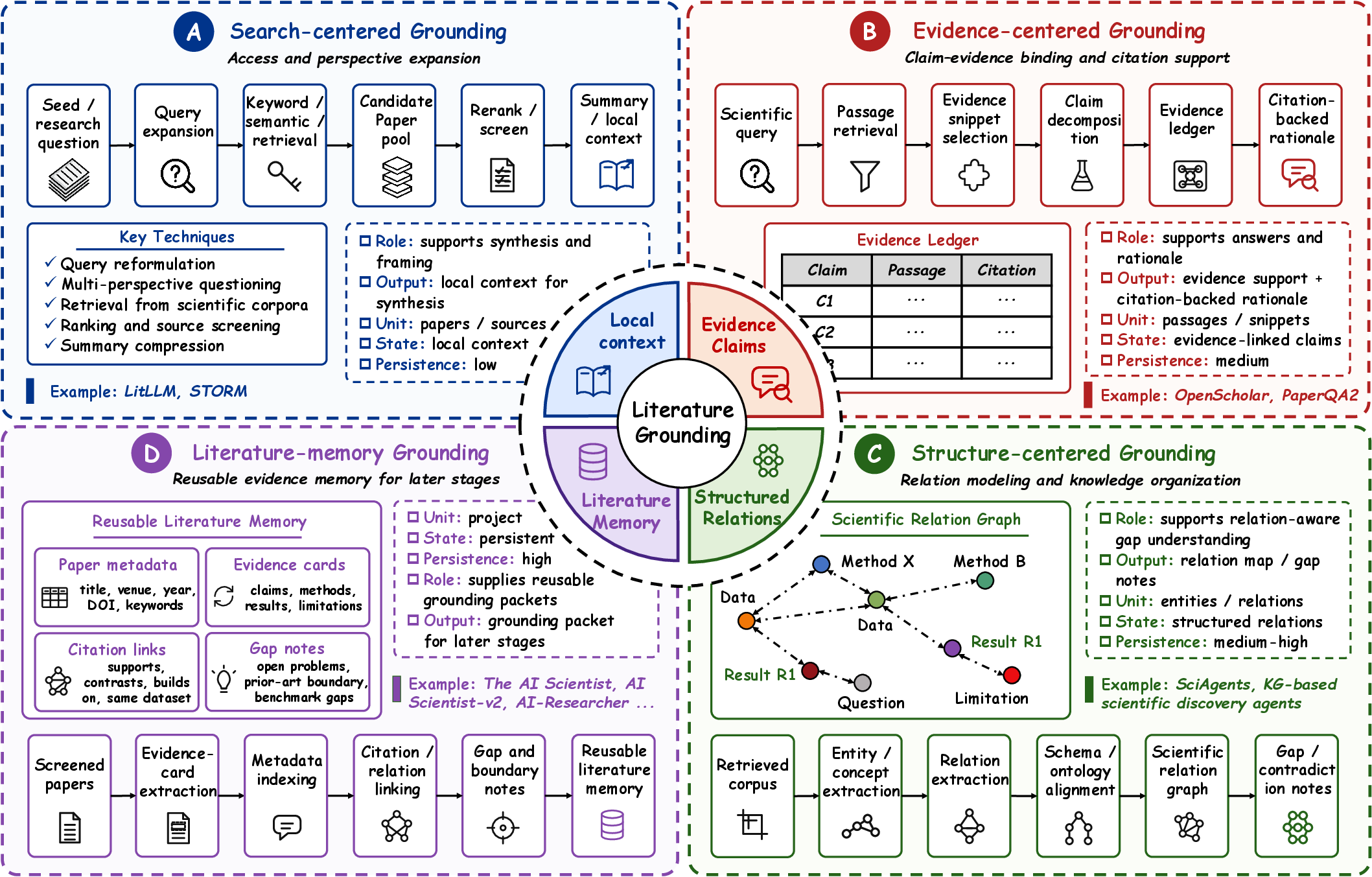
Figure 6: Literature grounding techniques, showing differing evidential persistence and structure.
Persistent challenge lies in robust evidence management and provenance tracing. Downstream scientific validity is bottlenecked by how literature becomes reusable, inspectable, and auditable across stages.
Four regimes—proposal-centered, deliberative multi-agent, structure-guided, and search-based evolutionary planning—are analyzed.
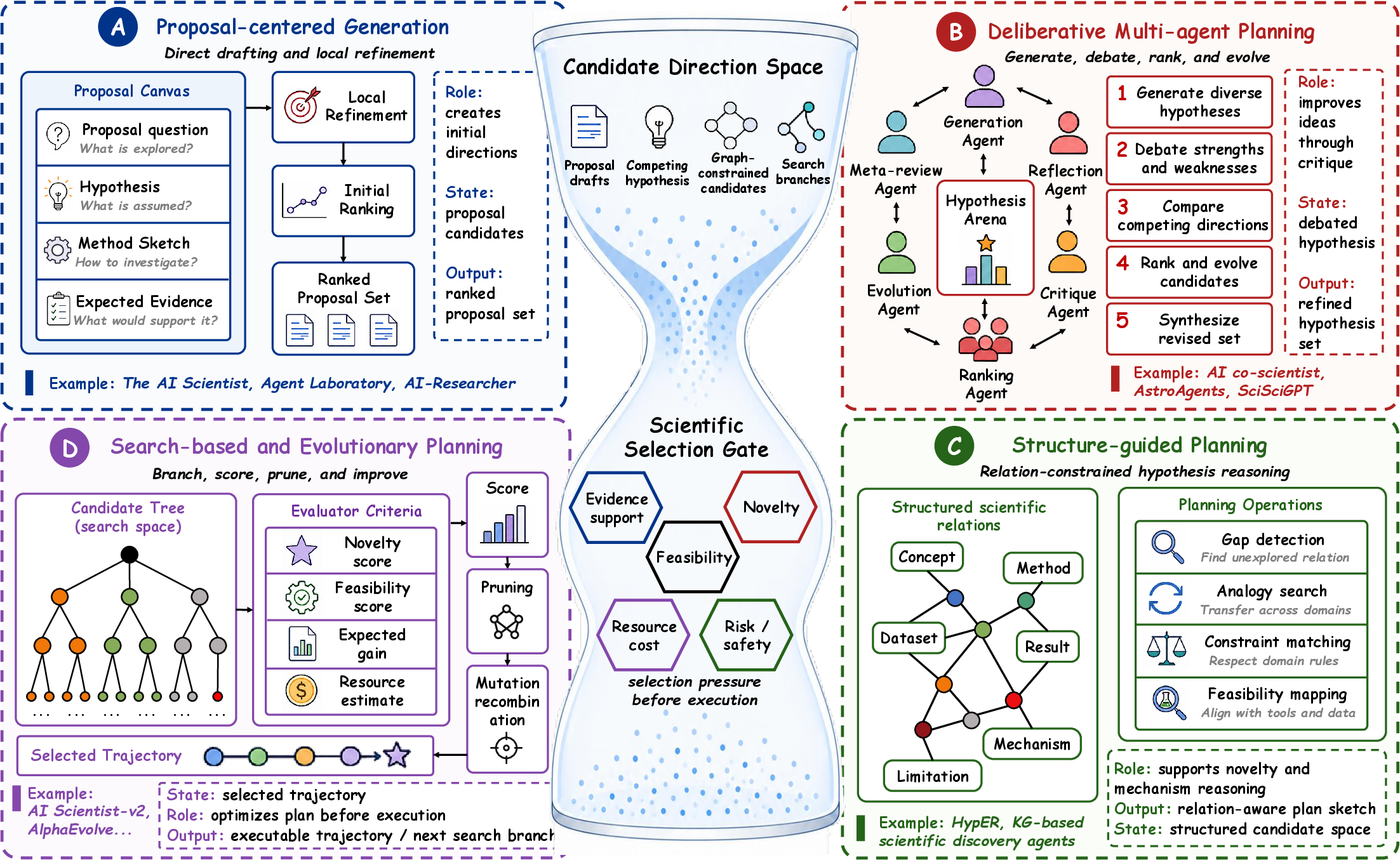
Figure 7: Comparative regimes for hypothesis/planning—single-controller, multi-agent deliberation, structure guidance, and search-based planning.
Current systems are proficient in combining and recombining knowledge, but lack true abductive reasoning or creative expansion of the research search space.
Execution regimes—code-native, tool-orchestrated, laboratory robotic, and human-gated—are mapped.
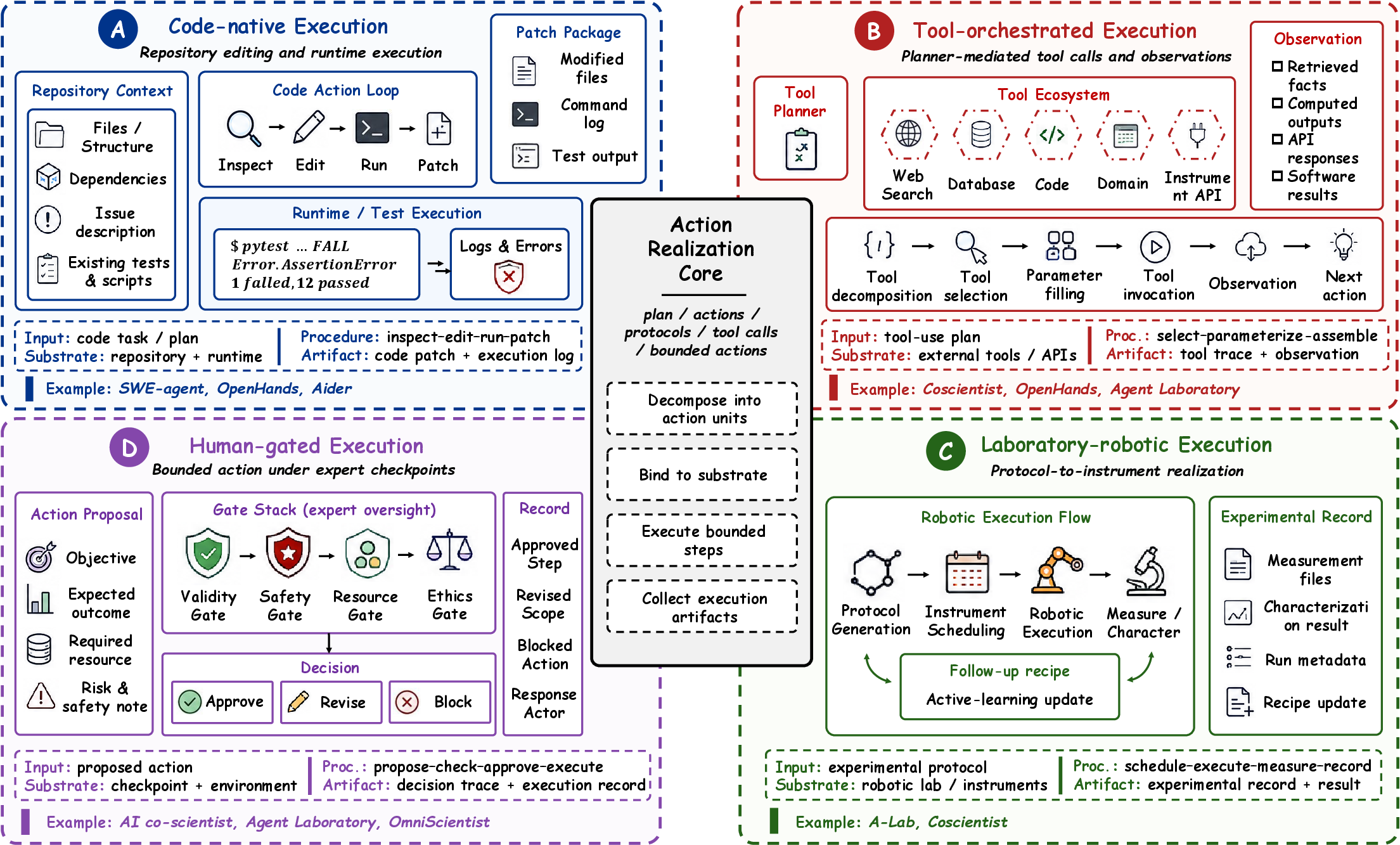
Figure 8: Execution modalities—code, tools, lab robotics, human-gated checkpoints—showing artifact realization for downstream validation.
Execution quality is fundamentally bounded by substrate properties; executability does not guarantee scientific adequacy or meaningful empirical validation.
Validation and Review
Three regimes—execution-coupled reruns, critique-mediated review, expert-grounded evaluation—capture rejection pressure.
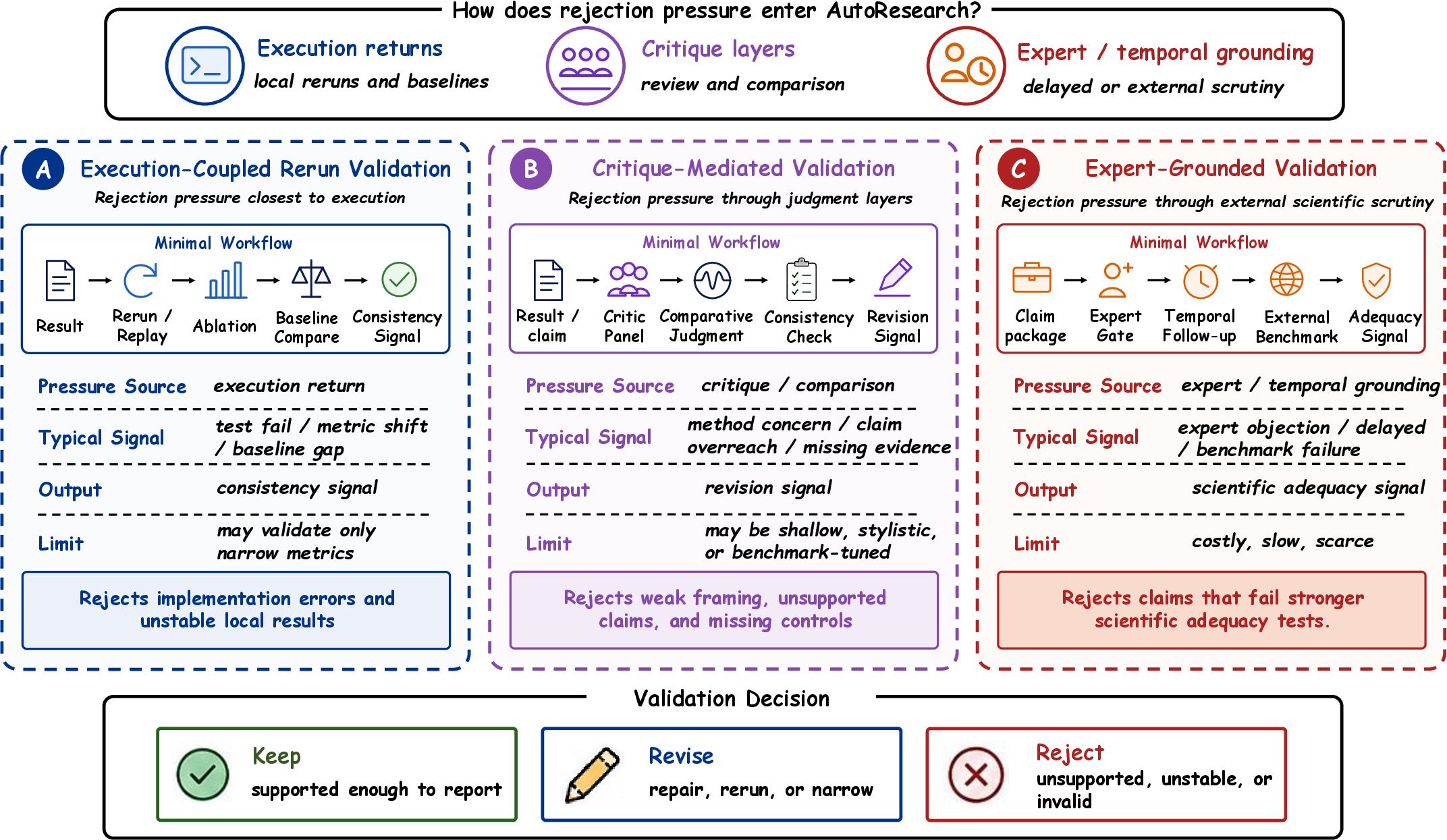
Figure 9: Validation regimes; the central bottleneck is strong, external filtering of weak directions.
Scientific closure is not possible without robust, cross-stage rejection pressure; current automation lacks durable mechanisms for filtering weak, unsupported, or non-reproducible claims.
Reporting and Communication
Reporting is dissected into draft-centered, review-centered, artifact-linked communication.
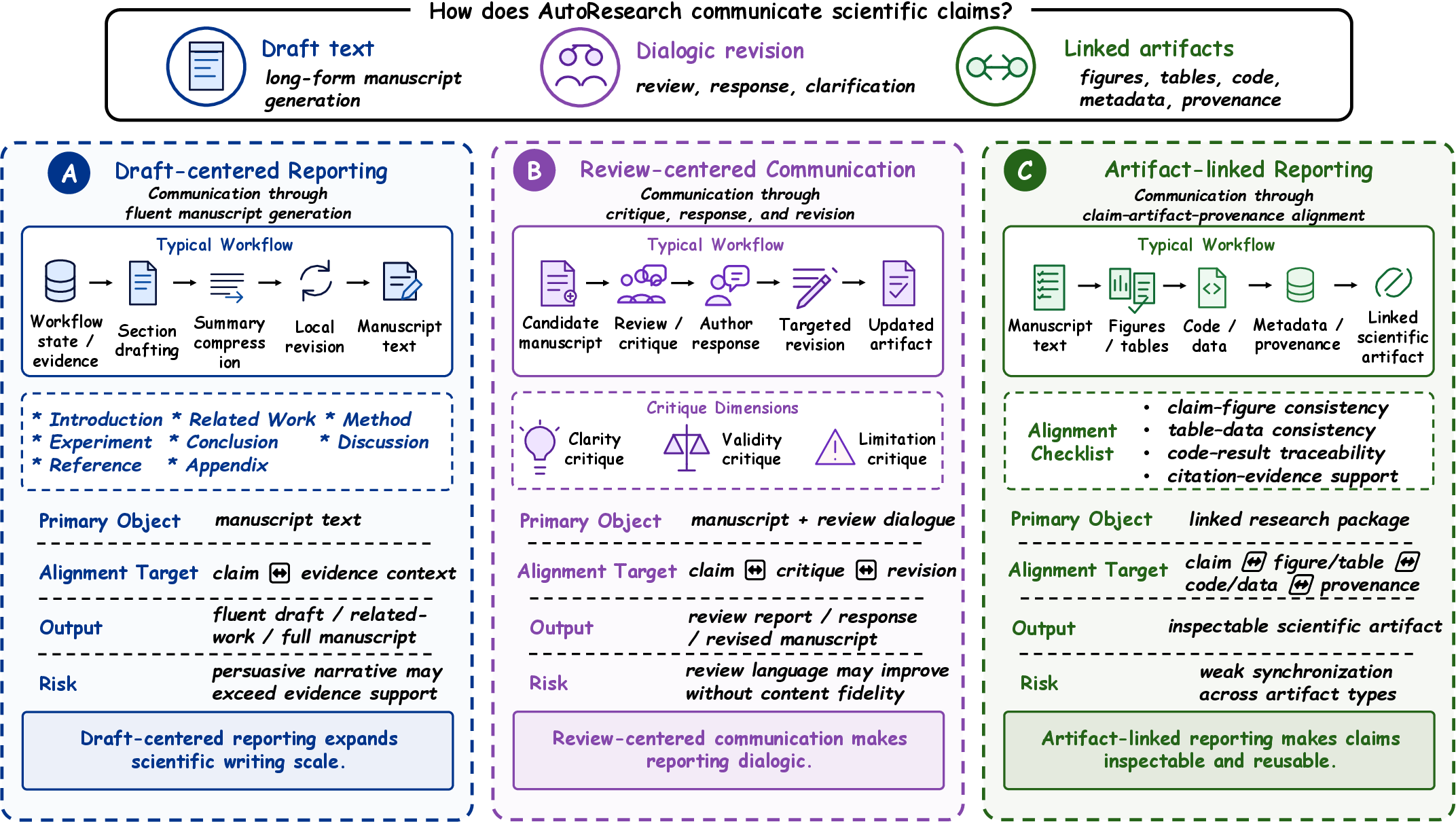
Figure 10: Reporting regimes—showing differing evidential discipline and artifact alignment in output.
Fluency and presentation outpace epistemic discipline; tight alignment between claims and artifacts is essential for downstream trust and reuse.
Evaluation: Scientific Quality and Autonomy Assessment
The survey foregrounds five scientific quality dimensions: novelty, validity, impact, reliability, provenance.
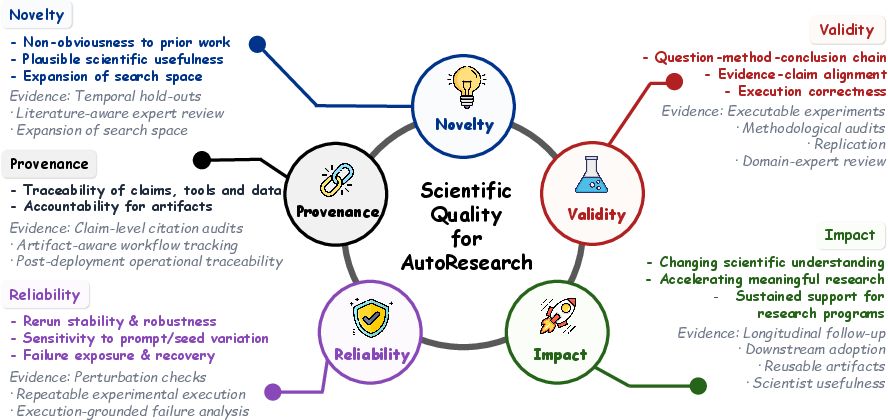
Figure 11: Judgment targets and evidence instruments for workflow-level scientific evaluation.
The evaluative burden escalates as autonomy shifts-in autonomous settings, workflow closure, evidence preservation, and responsibility retention must be demonstrated, not assumed.
Benchmarks remain fragmentary; the field lacks unified protocols for workflow-level scientific verification. Existing resources test discrete capabilities (ideation, execution, reproduction, review), but fail to couple novelty, reliability, and provenance in the same workflow.
Domain Conditioning: Autonomy Ceilings Across Fields
AutoResearch is domain-conditioned: computational and formal sciences yield the highest autonomy due to digital, executable, replayable substrates, while chemistry/materials, biology, medicine, social science, Earth science, and embodied settings impose strict limits stemming from experimental latency, heterogeneity, causal ambiguity, and institutional accountability.
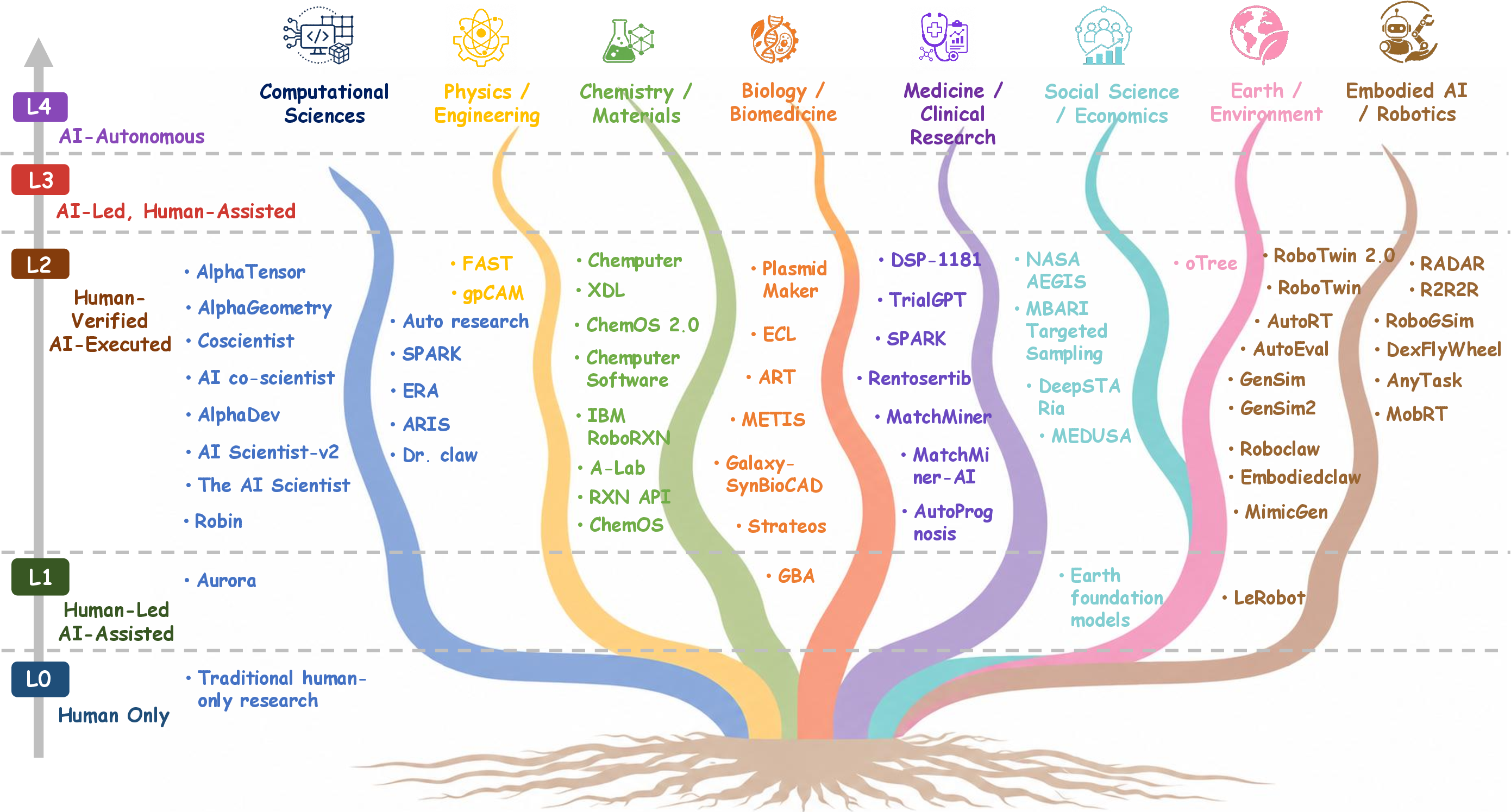
Figure 12: Domain-conditioned autonomy ceilings—code-native domains approach L3/L4, empirical and embodied domains remain in advanced-L2.
Pipeline automation is robust in digital environments; workflow closure and meaningful scientific autonomy require domain-aware evidence loops and validation substrates.
Discussion: Challenges, Boundaries, and Implications
Technical Limits
Strong claim: Current systems achieve procedural autonomy but lack true scientific agency. Hypothesis generation is limited to combinatorics across known concepts; creative, abductive reasoning and search-space construction remain human-held.
Reflexive iteration is underdeveloped: Automated pipelines optimize sequential execution but fail to propagate feedback upstream for substantive revision, reconfiguration, or paradigm shifts.
Evaluation and Impact
Current evaluation measures workflow completion, not scientific value; novelty, impact, provenance lack robust operational definitions. Human and LLM-based judgments are unreliable proxies for longitudinal scientific influence.
Generalization, Reliability, Trust
AutoResearch fails to generalize outside computational domains; validation, control, and reproducibility are bottlenecked by substrate heterogeneity and external constraints. Reliability is undermined by LLM dependence, which enables cross-stage propagation of hallucinations or unsupported claims. Provenance, error localization, and auditability are critical for trustworthy, reproducible automation.
Ethical Implications
AutoResearch risks amplifying disparities—resource-rich institutions gain disproportionate advantage. Paper production optimization may pollute the scientific ecosystem with low-value artifacts. Authorship, ownership, and responsibility are ambiguous as human and AI contributions blend.
Conclusion
AutoResearch AI crystallizes a paradigm shift from fragmented AI task assistance toward multi-stage, workflow-level automation. However, full scientific autonomy is elusive: evidence coupling, rejection pressure, validation, provenance, and domain-aware closure are necessary for trustworthy participation. The paper's taxonomy and analytical framework set conservative boundaries for claims of autonomy and highlight the persistent need for auditable, reproducible, and domain-adapted research infrastructures. Future developments must integrate rigorous evaluation, reflexive iteration, provenance control, and ethical governance to enable AI systems to truly expand the frontiers of scientific discovery.