- The paper introduces EVA, a co-designed vector quantization method that reformulates decoding from memory-bound GEMV with conflicts to efficient, conflict-free GEMM operations.
- It leverages conflict-free codebook dot products and a tiling strategy to maximize hardware utilization, achieving over 31× throughput improvements and up to 16.7× energy efficiency gains.
- This architecture enables low-latency LLM decoding on modest hardware while maintaining high accuracy, paving the way for broader deployment of compressed LLMs.
EVA: An Efficient Vector Quantization Architecture for Accelerated LLM Decoding
Introduction
LLM decoding is a fundamental bottleneck for contemporary transformer-based architectures, especially during autoregressive inference. While prefill phases exploit compute-bound large GEMM operations with high hardware utilization, the single-token stepwise nature of decoding transforms these operations into a sequence of small, memory-bound GEMV computations. These inflict significant underutilization on dense systolic arrays and exacerbate memory bandwidth constraints. Recent advances employ weight-only quantization for model compression, but existing techniques—especially vector quantization (VQ)—suffer from irregular, conflict-prone codebook lookups and fail to exploit efficient GEMM hardware pathways. The paper "EVA: Accelerating LLM Decoding via an Efficient Vector Quantization Architecture" (2605.24144) addresses these core inefficiencies by proposing EVA, a hardware-software co-designed vector quantization architecture that reformulates decoding computations and eliminates memory conflicts.
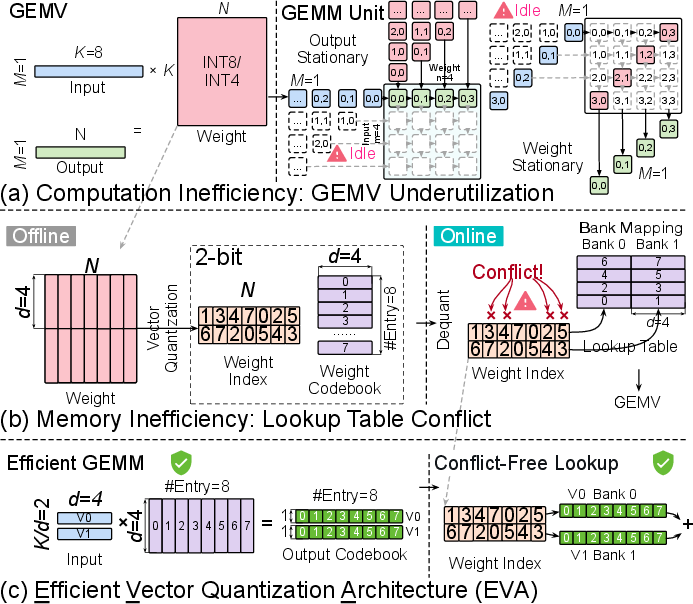
Figure 1: EVA transforms conventional VQ decoding from memory-bound GEMV with lookup conflicts (a, b) to highly efficient GEMM with conflict-free codebook access (c).
Quantization Landscape and Motivation
The work differentiates between analytic quantization (e.g., uniform, linear-scaling) and non-analytic quantization (e.g., K-means, VQ), highlighting the expressive and compression benefits of the latter.
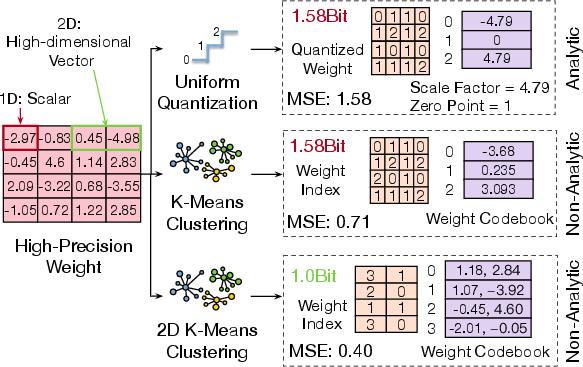
Figure 2: Schematization of analytic quantization and both 1D and 2D (vector) non-analytic quantization approaches.
Non-analytic quantization, notably VQ, clusters multi-dimensional weight groups into compact codebooks, achieving state-of-the-art compression with minimal accuracy loss. However, codebook-based lookups, due to irregular index patterns, introduce severe memory bank conflicts, diminishing the benefits of high compression ratios. The hardware-centric limitations of LUT designs motivate an algorithm-architecture co-design that fundamentally restructures the decoding computation.
EVA’s Computation Flow and Architectural Principles
EVA departs from traditional LUT-based vector quantized decoding in two main aspects: computation recasting and memory access reorganization.
EVA’s solution comprises two steps:
- Codebook Dot Product: Rather than reconstructing the full quantized weight matrix for each activation, the input vectors are directly dot-multiplied with the codebook centroids, forming an "output codebook" that summarizes all possible activation-codebook interactions.
- Conflict-Free Lookup: Instead of looking up weight elements in the codebook during GEMV, EVA looks up final outputs in the output codebook using the index matrix, ensuring fully parallel, bank-conflict-free memory access.
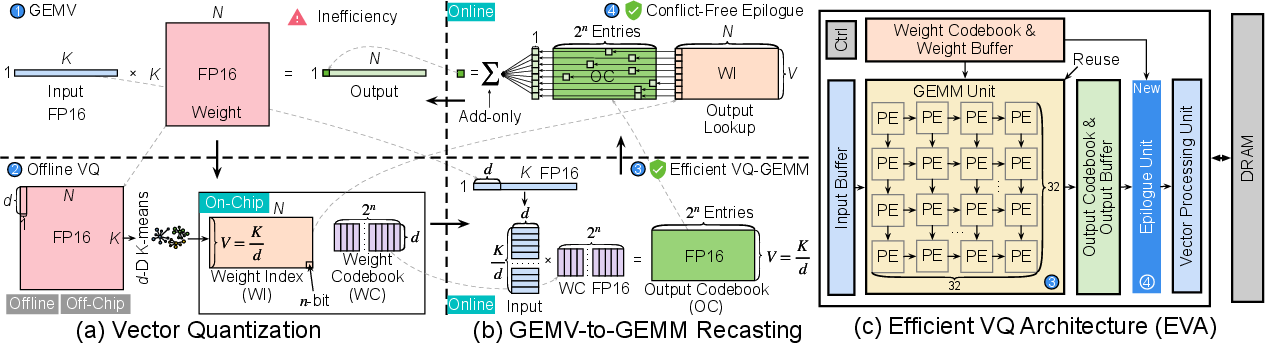
Figure 3: The computation and data flow of EVA, showcasing VQ-GEMM reformulation and conflict-free output codebook lookups.
By recasting GEMV into GEMM, EVA maximizes hardware utilization, elevates arithmetic intensity, and unlocks high-throughput decoding.
Hardware Architecture: Tiling, Mixed-Precision, and Epilogue Design
EVA employs tiling to mitigate limited on-chip SRAM, keeping weight codebooks and output codebook stationary for maximized data reuse, while streaming input and index tiles from off-chip DRAM.
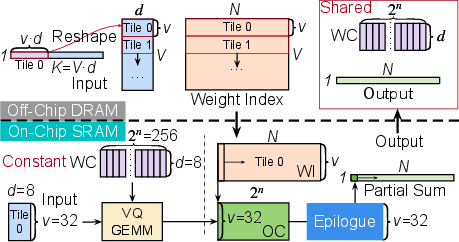
Figure 4: Tiling strategy for VQ-GEMM—efficient streaming of inputs/indices and stationary codebook/output arrangement.
The GEMM core is based on a reconfigurable systolic array, supporting both INT8-based large-batch GEMM (for prefill/attention) and FP16-based fine-grained VQ-GEMM (for decoding). This dual-mode support leverages arithmetic path multiplexing, enabling high efficiency with minimal additional area overhead.
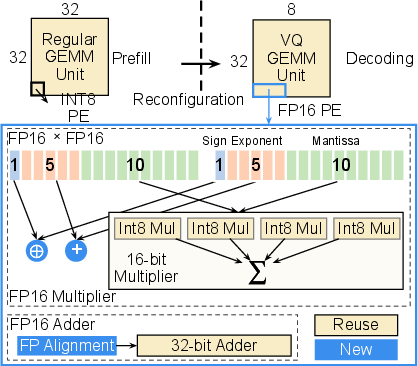
Figure 5: EVA’s mixed-precision GEMM unit, providing transparent INT8/FP16 reconfigurability via PE-level logic.
Final output reconstructions are handled by lightweight epilogue units (EUs), which perform conflict-free lookups from the output codebook and add-only reductions. This pipelined decoupling ensures no stalls in the GEMM core and enables direct scaling of EU count to match memory bandwidth and model parallelism.
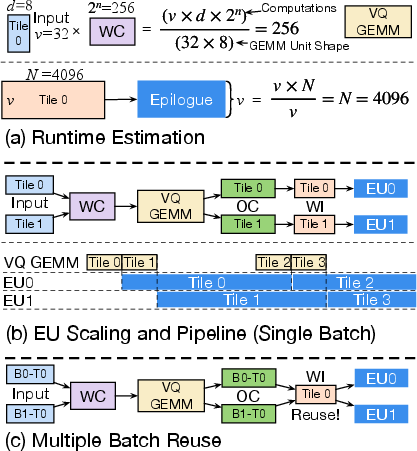
Figure 6: EVA execution scheduling: pipeline analysis (a), EU scaling and GEMM-EU overlap (b), and multi-request tile reuse (c).
Design Space Exploration and Architectural Evaluation
Exploring VQ parameters (d, n, C) and EU count, the design balances between latency, energy, and area. EVA achieves maximal efficiency for codebook sizes (2n) that leverage hardware parallelism and minimize spurious computation, confirming 8-bit indices and 2–4 codebooks as the optimal regime.
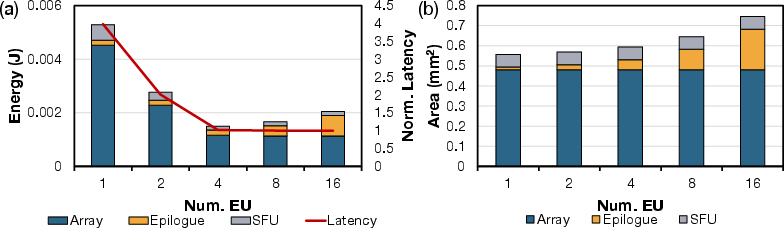
Figure 7: Impact of the number of epilogue units on latency, energy, and area overhead (left and right panels, respectively).
The overall area and power breakdown indicate that on-chip SRAM and DRAM dominate, which is expected for memory-bound decoding workloads, but EVA’s approach dramatically boosts throughput per unit area and watt.
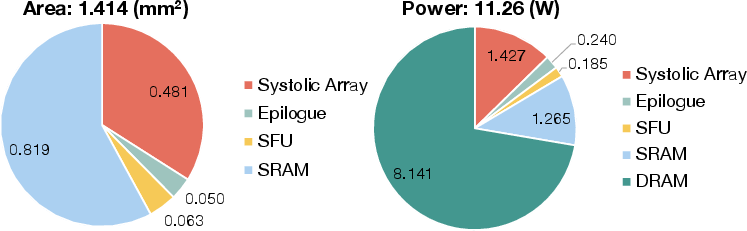
Figure 8: EVA’s area and power breakdown, with minimal contribution from additional epilogue units.
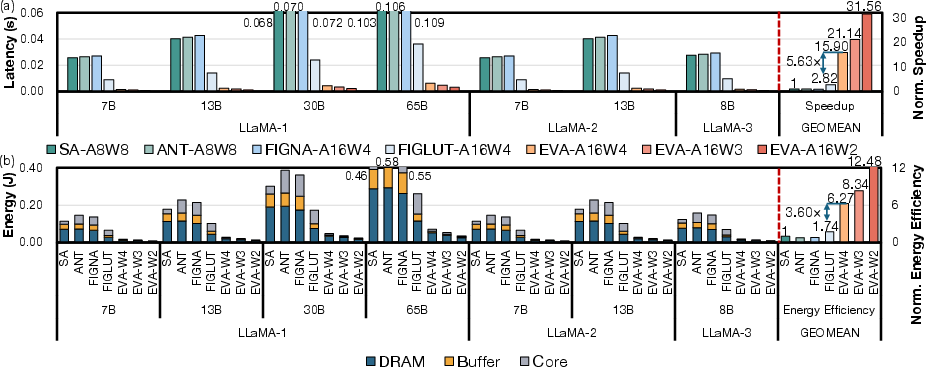
Experimental Results
EVA delivers strong empirical improvements over accelerator baselines (e.g., Systolic Array, FIGNA, ANT, FIGLUT):
Batch scaling analysis shows that while GEMM-based baseline utilization improves with increasing batch size, EVA’s GEMV–GEMM transformation ensures already-high utilization at batch size 1, making it substantially preferable for low-latency, interactive applications.
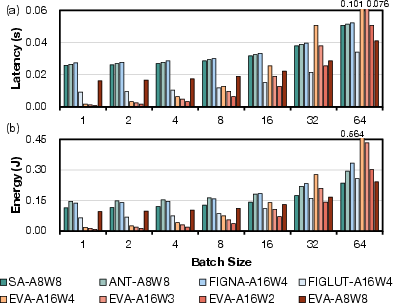
Figure 10: EVA’s latency and energy consumption scalability with increasing batch size in LLaMA-2-7B.
End-to-end scenario evaluations on LLaMA and MoE models (Mixtral, Qwen3) demonstrate 11.2× decoding speedup and 7.2× energy efficiency gain relative to state-of-the-art look-up accelerators, with negligible impact on perplexity or benchmark accuracy (≤0.5% degradation at 4 bits, <5.5% at 2 bits).
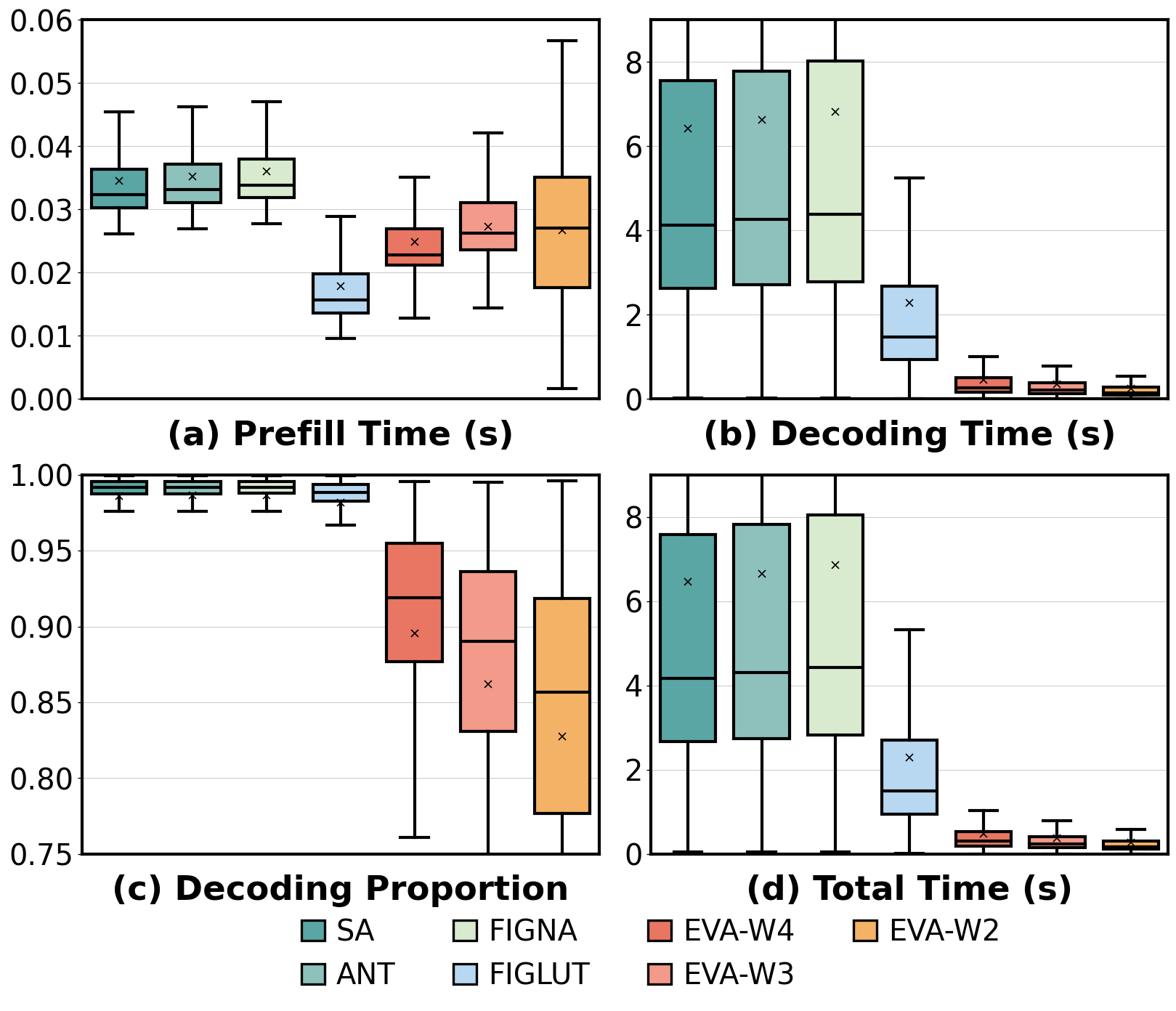
Figure 11: Distribution of EVA’s gains in prefill, decode, and total execution time, emphasizing benefits for decode-bound real-world tasks.
Analysis of Redundancy and Generalization
Theoretical and empirical analysis on codebook utilization demonstrates that, provided n0, the rate of unused (spurious) codebook multiplications is negligible (≤2%), thanks to the inherent entropy maximization of VQ. EVA’s algorithm-agnosticism extends compatibility to diverse VQ methods, such as additive, residual, and lattice-based multi-codebook strategies.
Related Work Context
EVA generalizes over software-only approaches (e.g., VQ-LLM [liu2025vq], CodeGEMM [park2025codegemm]) by resolving memory conflicts at the hardware level. Unlike LUT-based matrix multiplication accelerators (FIGLUT [park2025figlut], LUT Tensor Cores [zhiwen2024luttensorcore]), which rely on broadcasting/duplication with steep area/bandwidth increase and low codebook size, EVA structurally solves conflict and parallelism issues for arbitrary VQ configurations.
Practical Implications and Future Prospects
The theoretical and practical implications of EVA are consequential for future low-latency, energy-efficient LLM serving. By bridging high-dimensional codebook compression with compute-efficient, conflict-free accelerator design, EVA points toward a future where highly compressed LLMs (2- to 4-bit quantized) are deployable on modest hardware without sacrificing accuracy. This invites further co-evolution of quantization algorithm design and hardware specialization, particularly as capacity-rich MoE and multi-modal architectures proliferate. Improved epilogue utilization, adaptive tile scheduling, and attention-layer VQ integration are salient directions.
Conclusion
EVA provides a principled architecture for LLM decoding, eliminating core inefficiencies of GEMV-dominated inference via a codebook-aware GEMM formulation and conflict-free codebook lookup. The approach sustains SOTA arithmetic fidelity at aggressive low bit-widths and delivers order-of-magnitude improvements in throughput and energy efficiency, reaffirming the utility of algorithm–hardware co-design for the next generation of efficient LLM inference accelerators.