It's Not the Capability: Harness Sensitivity Is Non-Monotone Across LLM Agent Tiers
Abstract: A prevalent assumption in LLM agent deployment holds that more structured harnesses universally improve reliability, and that higher-capability models need proportionally less structural guidance -- together implying a monotone inverse relationship between model capability tier and optimal harness complexity. We test this hypothesis through a controlled 432-run experiment crossing six models across four capability tiers with three harness conditions (light, balanced, strict) on HEAT-24, a 24-task synthetic benchmark with git-based workspace verification. Our results refute the monotone inverse relationship on two fronts. First, for the frontier chat model evaluated (Gemini 2.5 Flash), increased harness verbosity lowers VTSR by 29-38 percentage points -- a harness-complexity paradox. Second, for the frontier reasoning model evaluated (Qwen3.5-122B, extended thinking enabled), strict harness achieves the highest VTSR (91.7%) and the lowest latency, the opposite of the prediction. Within the constrained tier, a 2B model (Gemma4:e2B) matches strong-open-tier stability at 91.7% across all harnesses. Because each tier is represented by a single model in this study, these results should be interpreted as model-specific observations; harness sensitivity appears non-monotone across the models evaluated, and depends critically on model type (chat vs. reasoning). We introduce a six-label failure taxonomy showing that format_violation dominates capable-model failures while wrong_file dominates low-capability failures, and we derive practical tier-aware harness selection guidelines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how “rulebooks” given to AI agents affect how well they do their jobs. These agents are LLMs that can read and edit files, like little digital assistants working inside a folder of code and documents. The authors test a common belief: that giving more detailed, step-by-step instructions always helps, and that “smarter” models need fewer rules. They find that this belief is not true. Instead, how much structure you should give depends on the type of model and the task—there isn’t a simple “more is better” or “smarter needs less” pattern.
What questions did the researchers ask?
They focused on a few easy-to-understand questions:
- If we give AI agents more structured instructions (a stricter rulebook), do they always perform better?
- Do higher‑end models really need fewer rules to do well?
- Do different kinds of models (chatty “assistant” models versus deep “reasoning” models) react differently to the amount of structure?
- What kinds of mistakes do models make when the instructions are too simple or too complicated?
How did they run the study?
Think of this like a class of students taking the same test under different classroom rules.
The “rulebooks” (harnesses)
A “harness” is the system prompt or rulebook that tells the model what it’s allowed to do, how to answer, and how the answer will be checked. They tried three versions:
- Light: very short, simple instructions.
- Balanced: some structure (a 4‑step plan), plus a list of which files are allowed.
- Strict: very detailed, with six stages, allowed files, exact success rules, and how checking will work.
The “students” (models)
They tested six LLMs across four “tiers” (from very capable to small). Some are chat‑oriented (good at talking like an assistant), others are reasoning‑oriented (good at long, careful thinking). Important examples:
- A top chat model (Gemini 2.5 Flash).
- A top reasoning model with extended thinking turned on (Qwen3.5‑122B).
- A strong open model (GPT‑OSS‑120B).
- Three small “constrained” models, including Gemma4:e2B (a 2B‑parameter model).
Note: “Parameter count” loosely measures size; bigger usually means stronger, but the paper shows that size isn’t everything.
The “tests” (tasks and scoring)
They built HEAT‑24, a set of 24 small, synthetic tasks inside a fake workspace (12 files like code, JSON, docs, etc.). Each task has a clear right or wrong answer, and a checker evaluates it automatically—like a grader with an answer key.
- Tasks included: reading files and returning JSON, fixing code to pass tests, editing one file, coordinating multiple files, repairing broken formats, and producing strictly formatted JSON.
- Success was counted as a pass/fail percentage. The paper calls this VTSR (Verified Task Success Rate), which here is simply “percent of tasks passed.”
- They also labeled mistakes (failures) into six types, such as:
- format_violation: didn’t follow the required output format (for example, not returning proper JSON).
- wrong_file: edited the wrong file.
- wrong_answer: format was fine, but the content was incorrect.
- and a few others.
In total, they ran 432 trials (6 models × 3 harnesses × 24 tasks).
What did they find?
Here are the main results, explained simply:
- More rules helped some models but hurt others.
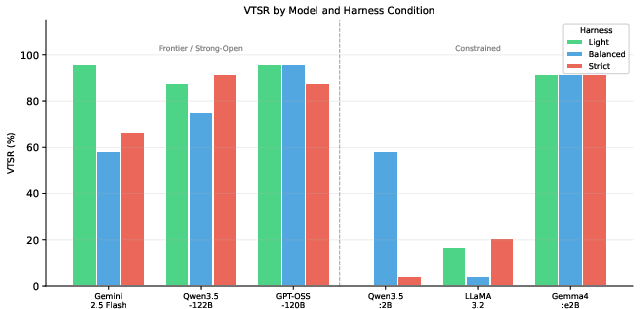
- Frontier chat model (Gemini 2.5 Flash): Did best with the Light rulebook. With Light, it passed about 96% of tasks. With Balanced or Strict, performance fell a lot (down by around 29–38 percentage points). Why? It often broke the required format (especially on JSON outputs)—it started “explaining” instead of just giving clean JSON.
- Frontier reasoning model (Qwen3.5‑122B, extended thinking on): Did best with the Strict rulebook. Strict improved accuracy to about 92%, better than Light (~88%) and clearly better than Balanced (~75%). It also answered faster under Strict, likely because the clear rules shortened its “thinking out loud.”
- Strong‑open model (GPT‑OSS‑120B): Very stable with Light and Balanced (~96%). Strict caused a small drop (~88%) but not awful.
- Smaller models were not all the same.
- Qwen3.5:2B: Best with Balanced (~58%), almost zero with Light and Strict. So, medium structure helped most; too little or too much was harmful.
- LLaMA 3.2: Low across all rulebooks (no reliable pattern).
- Gemma4:e2B (2B): Surprisingly strong and steady (~92%) under all rulebooks, similar to much larger models. This shows that good instruction‑tuning can matter more than size.
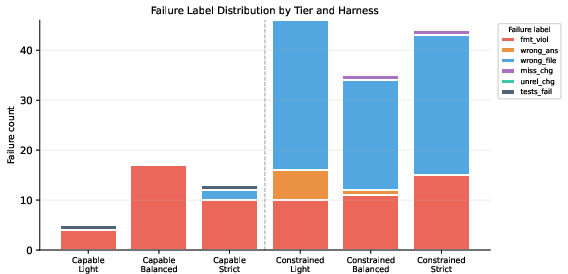
- The most common mistake depended on model strength.
- Stronger models mostly failed by format_violation (not following strict output format, like bad JSON).
- Weaker models often failed by wrong_file (editing the wrong file when the rulebook didn’t clearly limit them).
- Not a simple “more capable = fewer rules” story.
- The pattern is non‑monotone, which means it isn’t a straight line up or down. For example, the strict rulebook helped the reasoning model but hurt the chat model—opposite directions.
Why this matters:
- It breaks the myth that one rulebook fits all.
- It shows that the model’s type (chat vs reasoning) and its training for instructions and formatting are key.
What might this change in practice?
Here are simple, practical takeaways:
- Match the rulebook to the model type and task:
- Chat‑oriented frontier models: Prefer Light prompts for tasks that need clean JSON or strict formats; use Strict for file‑editing tasks where free‑form text is less risky.
- Reasoning‑oriented frontier models (with extended thinking): Prefer Strict rulebooks; clear steps and success criteria improve both accuracy and speed.
- Strong open models: Light or Balanced both work well; Strict may cause a small dip.
- Smaller, moderately capable models: Balanced is often the sweet spot—enough guidance without overload.
- Very small/weak models: Structure might not help much yet; they may need better training.
- Don’t rely on size alone. A small but well‑tuned model (Gemma4:e2B) can be as stable as a much larger one.
- Prevent format mistakes:
- Keep output‑format instructions simple and near the end of the prompt.
- Consider extracting answers with tools (like a JSON validator) if the model tends to explain too much.
- Test before deploying:
- Try a small “probe” set of tasks to see how your model reacts to Light, Balanced, and Strict prompts, especially on JSON‑heavy tasks.
Limitations to keep in mind
- Each “tier” had only one representative model. So, results are about these specific models, not every model in that tier.
- The workspace was synthetic and small; real projects are bigger and messier.
- Each setup was run once per condition; more repetitions would give tighter statistics.
- The reasoning model had extended thinking turned on; results might differ if that mode is off.
The big takeaway
There isn’t a one‑size‑fits‑all rulebook for AI agents. More structure isn’t always better, and “smarter” models don’t always need fewer rules. Instead, choose your prompt style based on the model’s type and how well it follows instructions and formats. Test a little, then pick Light, Balanced, or Strict to fit your model and task.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The following points summarize what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow‑up research.
Study design and statistical reliability
- Single repeat per condition () with small cell sizes () and wide Wilson CIs; no hypothesis tests or power analysis. Repeat runs with seeded randomness and are needed for stability estimates and significance testing.
- Each “tier” is represented by one model; tier-level conclusions are confounded by model idiosyncrasies. Replicate with multiple models per tier and multiple versions per family to assess generality.
- Run-order randomization and potential carryover effects (e.g., task/harness sequencing) are not reported. Randomize and counterbalance task and harness orders to eliminate sequence artifacts.
- Provider “default” sampling settings (temperature, top‑p, etc.) were used and are not standardized across models; seeds are unspecified. Control or sweep sampling parameters to quantify variance due to decoding stochasticity.
Model configuration and comparability
- Extended thinking is enabled only for the frontier reasoning model (Qwen3.5‑122B) and explicitly disabled for Ollama models (think=False), creating an unequal comparison. Ablate thinking mode (on/off) and budget across all models to isolate thinking‑mode × harness interactions.
- Local (Ollama) models are constrained to a 4096‑token context while all 12 files are injected; potential truncation risk is unmeasured. Log prompt and input token counts per model, detect truncation, and equalize context budgets where possible.
- GPT‑OSS‑120B strict runs were affected by an API rate limit and re‑run with a different key; residual contamination and variance are possible. Re‑run all cells cleanly and multiple times to remove provider‑induced confounds.
- The paper infers the importance of instruction‑tuning quality but provides no direct measure. Develop and report an instruction‑following compliance score (e.g., schema adherence probes) to quantify this latent variable and correlate with harness sensitivity.
Benchmark and harness design
- Synthetic 12‑file workspace and deterministic binary verifiers may not reflect real repositories’ scale, noise, and dependency structure. Validate on larger, real‑world benchmarks (e.g., SWE‑bench, multi‑file projects) and measure performance under retrieval/tool constraints.
- Tasks are single‑turn; “structured harnesses” are prompt templates rather than interactive scaffolds (ReAct/Reflexion loops). Evaluate multi‑turn agent settings to see whether interaction mitigates format violations and wrong‑file errors.
- Only three harness levels are tested; components vary jointly (process stages, allowed‑file list, success criteria, verification spec). Perform factorial ablations to isolate which harness subcomponents cause/help failures (e.g., stages vs. file list vs. success criteria vs. schema reminder placement).
- The study does not test mitigation techniques known to improve structured outputs (e.g., JSON‑mode/structured decoding, function‑calling/Tools, constrained grammars, or post‑hoc extraction). Benchmark whether such mechanisms eliminate the format_violation spike under complex harnesses.
- Harness wording/formatting is fixed; prompt sensitivity to small formatting changes is not explored despite being known to be large. Conduct multi‑prompt evaluations within each harness level (paraphrases, ordering, verbosity) to estimate variance due to harness phrasing.
- The strict harness mixes process instructions with output requirements; the hypothesized benefit of “decoupling” is not experimentally verified. Test late‑binding of output‑format instructions (placing schema immediately before generation) versus interleaving to quantify effects.
Measurement and analysis
- TSR/VTSR is a binary metric; partial credit, edit quality, and safety of changes are not assessed. Add granular metrics (e.g., schema‑field compliance rates, diff quality measures, test coverage impacts) and cost/throughput metrics (prompt/output tokens).
- Latency includes model load time for local models and is not normalized by token counts; no cost accounting is provided. Report tokenized prompt/output lengths, tokens/sec, and monetary cost to clarify practicality of harness choices.
- Failure taxonomy is rule‑based with no human validation; label fidelity and edge cases (e.g., near‑valid JSON) are unverified. Sample and adjudicate failures to validate taxonomy precision/recall and refine format_violation into subtypes (e.g., extra prose, missing keys, trailing commas).
- No analysis of output verbosity or chain‑length versus failure is provided; the mechanism behind format_violation remains speculative. Log and correlate reasoning length/verbosity with compliance outcomes to test the hypothesized objective conflict.
- Task‑difficulty calibration is absent; category difficulties may be uneven. Apply item‑response or hierarchical models to separate task difficulty from model × harness effects.
External validity and scope
- Generalization beyond software‑workspace tasks is untested (e.g., document extraction, operations workflows, multilingual settings, multimodal inputs). Evaluate across domains, languages, and modalities to see whether non‑monotonic harness sensitivity persists.
- Safety/guardrail interactions with harness structure (e.g., verbose safety disclaimers triggering format errors) are not examined. Test whether safety filters contribute to format_violation under strict harnesses across providers.
Open questions for future research
- Does the non‑monotone harness–capability relationship replicate across more model families and versions (including other “reasoning” models) and on non‑synthetic tasks?
- Which specific strict‑harness components improve the frontier reasoning model while harming the frontier chat model, and why? Run controlled ablations with thought‑token logging to identify causal mechanisms.
- Can adaptive harness selection be automated (e.g., brief probe tasks to route model × task to light/balanced/strict)? Benchmark regret and stability of such policies.
- Do two‑phase protocols (strict for planning, light for final JSON emission) eliminate format_violation without sacrificing accuracy or latency?
- How do decoding strategies (temperature/top‑p sweeps, deterministic decoding) and structured decoding (JSON mode, constrained grammars) modulate the harness‑complexity paradox?
- What measurable properties of instruction‑tuning (datasets, RLHF objectives, schema‑centric training) predict harness stability better than parameter count?
- How does increasing repository size and context pressure interact with harness complexity—does strict harness help or hurt when context windows are near capacity?
Practical Applications
Immediate Applications
The paper’s findings translate into concrete changes teams can make today in how they build, evaluate, and operate LLM agents.
- Tier- and type-aware harness policies (software/DevOps, enterprise IT, RPA)
- What to do: Replace one-size-fits-all prompts with model-type–specific harnesses.
- Chat/frontier (e.g., Gemini-class): Use light harness for JSON/structured-output and inspection tasks; reserve strict harness for file-editing tasks where format risk is lower.
- Reasoning/frontier (extended thinking enabled, e.g., Qwen-class): Use strict harness with explicit success criteria across task categories to improve both success rate and latency.
- Constrained/moderate (e.g., Qwen 2B): Use balanced harness (plan/execute/check + allowed-file list).
- Constrained/low (e.g., LLaMA 3B): Avoid for workspace-editing agents unless capability improves.
- Dependencies/assumptions: Ability to identify model type and thinking-mode settings; control over agent prompt templates; acceptance of model-specific guidance and the paper’s k=1 preliminary results.
- Category-aware prompt selection (software/DevOps, data engineering)
- What to do: Route by task category as observed in HEAT-24.
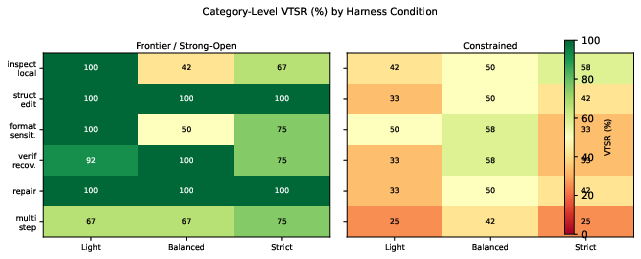
- For format-sensitive and inspect_local tasks: prefer light harness for chat models; strict for reasoning models.
- For multi_step_ops on capable models: consider strict harness.
- For structured_edit and repair on capable models: any harness is fine.
- Dependencies/assumptions: Tasks can be labeled; agent pipeline supports category-based template selection.
- Decouple “process instructions” from “output formatting” (software, data/ETL, enterprise IT)
- What to do: Move output schema specifications immediately before the generation step and keep them concise; keep multi-stage process guidance in a separate segment.
- Tooling: Add schema-constrained decoding (e.g., JSON schema validators), lightweight JSON repairers, or regex extractors.
- Dependencies/assumptions: Access to model wrappers or middleware; availability of schema/validator libraries.
- Allowed-file lists and write markers for workspace edits (software engineering, DevOps)
- What to do: Always include allowed-file lists for lower-capability models; use explicit write markers (e.g., <<<WRITE:path>>> … <<<END>>>).
- Tooling: “GitGuard Runner” that applies edits and verifies diffs via git.
- Dependencies/assumptions: Agents operate on a git-initialized workspace; ability to enforce markers and scope.
- Failure taxonomy–driven observability (all sectors using agents that touch files/data)
- What to do: Log and dashboard failures by the six labels (format_violation, wrong_file, wrong_answer, missing_change, unrelated_change, tests_still_fail) to localize harness issues.
- Impact: Quickly exposes “format_violation” spikes in capable models and “wrong_file” spikes in constrained models.
- Dependencies/assumptions: Centralized logging; minimal rule-based post-processing.
- Lightweight harness probing before deployment (software procurement, MLOps)
- What to do: Add a 4–6 task “HEAT-24 Lite” gate in CI to test a new model across light/balanced/strict harnesses; pick the best policy prior to rollout.
- Tooling: “Harness Probe” CLI/CI job that runs category-representative tasks.
- Dependencies/assumptions: Access to the model with production settings; stable evaluation compute.
- Cost/latency optimization via harness choice (software, platform teams)
- What to do: For chat models on JSON tasks, switch to light harness to cut tokens and latency; for reasoning models, switch to strict to reduce “thinking chain” length and wall time.
- Dependencies/assumptions: Token accounting; latency SLAs; ability to toggle harness based on route.
- Vendor evaluation and procurement criteria (policy, compliance, enterprise IT)
- What to do: Require multi-harness evaluation in RFPs; disallow reporting a single accuracy number without harness spec; request failure-mode breakdowns and format-compliance stats.
- Dependencies/assumptions: Procurement maturity; cooperation from vendors.
- End-user prompt hygiene for structured outputs (daily workflows, data/ops)
- What to do: When asking capable chat-oriented assistants for JSON/YAML:
- Keep instructions brief; place the exact schema last; ask to “respond with JSON only”.
- Dependencies/assumptions: The assistant behaves like the evaluated chat model; users can control prompt brevity.
- Agent routing by harness style (platform/AI ops)
- What to do: Introduce a “Harness Router” microservice that picks light/balanced/strict given model type, task category, and prior failure signals.
- Dependencies/assumptions: Accurate model metadata; feature flags for harnesses; A/B switch infrastructure.
Long-Term Applications
These directions require further research, scaling, or productization beyond minimal integration.
- Adaptive harness controllers (software platforms, AIOps)
- Idea: Use bandits or reinforcement learning to select harness style per task in real time based on streaming failure labels and latency/cost signals.
- Potential product: “HarnessOps” controller with policy learning and guardrails.
- Dependencies/assumptions: Sufficient online traffic for learning; safe exploration policies; rollback mechanisms.
- Standardized harness-sensitivity benchmarks and governance (policy, standards bodies, academia)
- Idea: Extend HEAT-24 to real repositories (e.g., SWE-bench variants), and formalize “harness-sensitivity” metrics for AI procurement and regulatory filings.
- Potential outcome: NIST-like guidance on prompt structure disclosure and multi-prompt evaluation requirements.
- Dependencies/assumptions: Community adoption; open datasets with licensing clarity.
- Instruction-tuning for format compliance (model providers, academia)
- Idea: Train models with multi-objective losses that prioritize schema adherence and teach suppression of explanatory prose when a format is mandated.
- Potential tools: Synthetic JSONSchemaBench-style corpora; constrained decoding training.
- Dependencies/assumptions: Access to training pipelines; vendor buy-in; evaluation suites that penalize format violations.
- Reasoning–format separation in agent frameworks (software/agent infra)
- Idea: Architect two-channel agents: a “thinking/planning” stream and a “format-only emitter” stream with strict decoding, or a two-pass generate-then-format pipeline.
- Potential product: Agent SDKs with pluggable “format emitters” (e.g., structured head or grammar-decoder).
- Dependencies/assumptions: Model support for constrained decoding or toolformer-style interfaces; latency budget for two-pass generation.
- Runtime model/type detection and harness personalization (platforms)
- Idea: Infer whether a model behaves as “chat” or “reasoning” under current settings (e.g., extended thinking on/off) to personalize harnesses dynamically.
- Dependencies/assumptions: Stable behavioral signatures; telemetry from inference stack.
- IDE and CI integrations (developer tools)
- Idea: VS Code/JetBrains extensions that:
- Automatically insert allowed-file lists and write markers for edits.
- Switch harness style per task (e.g., formatting vs. refactoring) and model.
- Dependencies/assumptions: Editor APIs; dev team acceptance.
- Sector-specific guardrails for high-stakes structured data (healthcare, finance, gov)
- Idea: “FormatGuard” gateways that quarantine or auto-repair outputs that violate schemas before they reach EHRs, regulatory filings, or ledgers.
- Dependencies/assumptions: Clear ontologies and schemas; acceptance of auto-repair policies; audit trails.
- Cross-domain harness-design science (academia)
- Idea: Systematic studies of harness complexity across domains (document processing, robotics planning, operations automation) to model non-monotone effects and thinking-mode interactions.
- Dependencies/assumptions: Shared benchmarks; reproducible access to frontier models; preregistered designs.
- Safe thinking-mode alignment (model providers, research)
- Idea: Explore how explicit harness constraints shape chain-of-thought length and quality; develop methods to control “thinking budgets” without degrading format compliance.
- Dependencies/assumptions: Access to models with controllable reasoning modes and telemetry.
- Robust, generalizable verification frameworks (software/DevOps)
- Idea: Production-grade, git-based verifiers and schema checkers that scale beyond synthetic workspaces to real monorepos and multi-service systems.
- Dependencies/assumptions: Repository access; rule authoring at scale; performance engineering.
Cross-cutting assumptions and dependencies
- Model specificity: Findings are model-specific (single model per tier, k=1 runs). Teams should re-validate harness choices when models or inference settings change (e.g., enabling/disabling extended thinking).
- Synthetic-to-real transfer: HEAT-24 uses a 12-file synthetic workspace; outcomes may differ on large, noisy repositories or domains.
- Infrastructure: Many applications assume control over prompts, access to git-based workspaces, and the ability to insert validators and log pipelines.
- Rate limits and context: API quotas and context-length constraints can confound strict harnesses (longer prompts); monitor and budget tokens accordingly.
Glossary
- Agent scaffolding: Structured prompting or loop designs that coordinate an agent’s reasoning and actions to improve performance. "Agent scaffolding."
- allowed-file list: An explicit whitelist of files the agent is permitted to modify or read during a task. "an allowed-file list"
- capability tier: A deployment-oriented categorization of models (e.g., by parameter count and infrastructure) used to discuss expected behavior. "model type (chat vs.\ reasoning) is an independent moderating variable that capability tier alone cannot capture."
- chain-of-thought: Explicit intermediate reasoning steps or tokens produced by a model during problem solving. "Ollama-hosted models used think=False to suppress chain-of-thought tokens"
- extended thinking: An inference mode that allocates additional reasoning budget or steps before finalizing outputs. "Qwen3.5-122B's “Frontier-Reasoning” classification reflects extended thinking being enabled as an inference configuration choice across all runs"
- failure taxonomy: A predefined set of labels classifying why tasks fail (e.g., format or file errors). "We introduce a six-label failure taxonomy"
- format_sensitive: A HEAT-24 task category requiring strictly formatted outputs (often JSON). "format_sensitive: emit strict JSON schema;"
- format_violation: Failure label indicating the model’s output could not be parsed as the required schema. "format_violation dominates capable-model failures"
- Frontier-Proprietary: A tier denoting proprietary frontier-scale models accessed via closed APIs. "For Gemini 2.5 Flash (Frontier-Proprietary)"
- Frontier-Reasoning: A tier denoting frontier models configured or optimized for extended reasoning. "Qwen3.5-122B (Frontier-Reasoning, extended thinking enabled)"
- git diff: The version-control operation used to detect and scope file changes in verification. "verification uses git diff to detect and scope file changes."
- git-based workspace verification: Validation of task outcomes by inspecting a git repository’s changes. "HEAT-24, a 24-task synthetic benchmark with git-based workspace verification."
- git-scoped: Constrained or measured with respect to git-tracked file changes. "git-scoped file modifications"
- Google AI Studio: A hosted provider/platform used to access proprietary models via API. "Google AI Studio API"
- Groq Cloud: A hosted inference service used to run large open-weight models at low latency. "Groq Cloud API (Groq, Inc.)"
- harness: The system-level prompt and instructions specifying task scope, allowed operations, output format, and verification. "The quality of the harness—the system-level prompt that specifies task scope, allowed operations, output format, and verification procedure—"
- harness-complexity paradox: The empirical finding that increasing harness structure can reduce success for some capable models. "a harness-complexity paradox."
- harness runner: The component that parses agent outputs and applies declared file edits to the workspace prior to verification. "that the harness runner parses and applies to the workspace before verification."
- HEAT-24: A deterministic 24-task benchmark for evaluating harness effects on LLM agents. "HEAT-24 (Harness Evaluation for Agent Tasks)"
- instruction-tuning: Fine-tuning that improves adherence to instructions and structured-output requirements. "instruction-tuning quality is the true moderating variable."
- inspect_local: A HEAT-24 category focused on reading local files and returning structured outputs. "inspect_local: read files, return JSON;"
- JSON parse validity: Whether a produced JSON string can be parsed without errors. "YAML/JSON parse validity"
- JSON schema: A formal specification that defines the structure and fields required in JSON outputs. "emit strict JSON schema"
- macro-average: An averaging method that gives equal weight to categories when computing overall performance. "reports macro-average VTSR by task category"
- Mixture-of-Experts: A model architecture that routes tokens to specialized expert subnetworks for efficiency and capacity. "Qwen3.5-122B is a Mixture-of-Experts model"
- missing_change: Failure label indicating that no file modification was detected when one was required. "missing_change (no file modification detected)"
- Modelfiles: Configuration files used by Ollama to set model parameters like context length. "via per-model Modelfiles."
- monotone inverse hypothesis: The hypothesis that higher-capability models require less harness structure in a strictly inverse manner. "We ask whether this monotone inverse hypothesis holds empirically"
- multi-prompt evaluation: Assessing models under multiple prompt or harness variants to avoid brittleness. "and call for multi-prompt evaluation"
- multi_step_ops: A HEAT-24 category requiring coordinated edits across multiple files. "multi_step_ops: coordinate multiple files."
- non-monotone: Not following a single increasing or decreasing trend across conditions. "harness sensitivity appears non-monotone across the models evaluated"
- non-monotonic pattern: A pattern where performance improves and worsens across conditions rather than moving in one direction. "a non-monotonic pattern (strict harness helps the frontier reasoning model most)."
- Ollama: A local inference framework for running open-weight models with configurable settings. "Ollama-hosted models used think=False"
- ReAct: An agent prompting method that interleaves reasoning and acting to improve task performance. "ReAct~\citep{yao2022react}"
- Reflexion: An agent method that leverages self-reflection or verbal reinforcement to improve future actions. "Reflexion~\citep{shinn2023reflexion}"
- schema-constrained decoding: Constraining generation to adhere to a specified schema during output. "schema-constrained decoding"
- Strong-Open: A tier denoting strong, openly available models typically run on high-performance inference platforms. "GPT-OSS-120B (Strong-Open, via Groq)"
- structured output generation: Techniques and evaluations focused on producing outputs with strict structure (e.g., JSON). "Work on structured output generation"
- structured_edit: A HEAT-24 category focused on making a targeted change to a single file. "structured_edit: modify one file;"
- success criteria: Explicitly stated conditions that define what counts as a successful solution. "explicit success criteria"
- tests_still_fail: Failure label indicating that tests remain failing after the model’s code change. "tests_still_fail (code change did not fix targeted test failure)"
- think-budget: A configured limit on the amount of extended reasoning a model can perform. "think-budget default"
- think=False: A configuration flag used to disable production of chain-of-thought tokens. "used think=False to suppress chain-of-thought tokens"
- Tier-aware harness selection: Choosing harness complexity based on a model’s tier or type to improve reliability. "tier-aware and type-aware harness selection"
- TPD (tokens-per-day) rate limit: A provider quota that limits the number of tokens processed per day. "200\,k tokens-per-day (TPD) rate limit"
- TSR: Task Success Rate; the pass/fail metric as determined by the verifier. "TSR (Task Success Rate): binary pass/fail as determined by the workspace verifier."
- verification specification: Explicit instructions detailing how outputs will be checked or validated. "a verification specification"
- verification_recovery: A HEAT-24 category involving fixing bugs and running tests to verify success. "verification_recovery: fix bug, run tests;"
- verifier: The automated checker that determines whether task criteria are met. "Verifiers check: JSON key presence and values, git-scoped file modifications, YAML/JSON parse validity, and substring presence."
- VTSR: Verified Task Success Rate; TSR adjusted to exclude verifier/infrastructure errors. "VTSR (Verified Task Success Rate)"
- Wilson CIs: Wilson score confidence intervals used for binomial proportions. "Representative 95\% Wilson CIs (for )"
- workspace artifacts: Files and resources inside the agent’s working repository that tasks operate on. "modify workspace artifacts"
- workspace-level git-based verification: Performing verification at the repository level using git to track and assess changes. "workspace-level git-based verification"
- WRITE:path marker: A special output marker indicating file edits to apply to the workspace. "using the <<<WRITE:path>>> marker."
- wrong_answer: Failure label for outputs that are well-formed but contain incorrect values. "wrong_answer (parseable but incorrect value)"
- wrong_file: Failure label for modifying a file outside the allowed set. "wrong_file (modified a file outside the allowed set)"
- unrelated_change: Failure label for edits to an allowed file that nevertheless change the wrong content. "unrelated_change (modification to a correct file but wrong content)"
Collections
Sign up for free to add this paper to one or more collections.