- The paper presents a hybrid top-down/bottom-up framework that disentangles semantic rules from statistical models to ensure logical consistency and robust data synthesis.
- It employs ensemble methods like RandomForest and XGBoost in the bottom-up path to capture complex local dependencies, achieving competitive performance versus neural methods.
- The framework integrates a feedback loop using metrics such as AUROC, F1, and XModal to dynamically adjust synthesis, enhancing utility in multimodal datasets.
Hierarchical Synthetic Tabular Data Generation via a Hybrid Top-Down/Bottom-Up Framework
Motivation and Problem Setting
Synthetic tabular data generation underpins a wide spectrum of applications in finance, healthcare, and privacy-sensitive machine learning. Traditional purely generative approaches—ranging from GANs (CTGAN, TVAE) and DPMs (TabDDPM, STaSy) to autoregressive LLM-based generators (GReaT, REaLTabFormer)—are challenged by heterogeneous attribute types, limited logical consistency, insufficient rare-event synthesis, and weak robustness in low-data regimes. These deficiencies are pronounced in enterprise-scale, multi-source tabular domains where rare combinatorial and logical edge-cases must be captured while enforcing cross-modal integrity. Prior neural and LLM-based techniques frequently suffer from distributional collapse, semantic incoherence, and expensive compute requirements for runtime controllability. The discussed paper proposes a hybrid top-down/bottom-up (H-TDBU) synthesis paradigm that disentangles semantic structure from statistical texture, consolidating them through an iterative rule-constrained generation mechanism.
The H-TDBU Framework
The central contribution is a hierarchical architecture consisting of explicitly decoupled pathways: a top-down semantic controller and a bottom-up statistical model. The top-down path constructs a logical program or schema S based on domain rules, functional dependencies, or LLM-generated templates. The bottom-up path fits an efficient generative model (G), typically a tree-ensemble (RandomForest, XGBoost) or traditional copula, to observed data, extracting latent stochastic codes z∈Z that embed complex local dependencies.
These two pathways merge in a conditional synthesis engine G(z∣S), which generates samples that are both semantically aligned and statistically realistic. A feedback validation loop integrates TSTR performance and cross-modal alignment (XModal) metrics; failures either trigger top-down rule adjustment or retract bottom-up model fitting. This dynamic synthesis/validation loop addresses both logical integrity and distributional coverage.
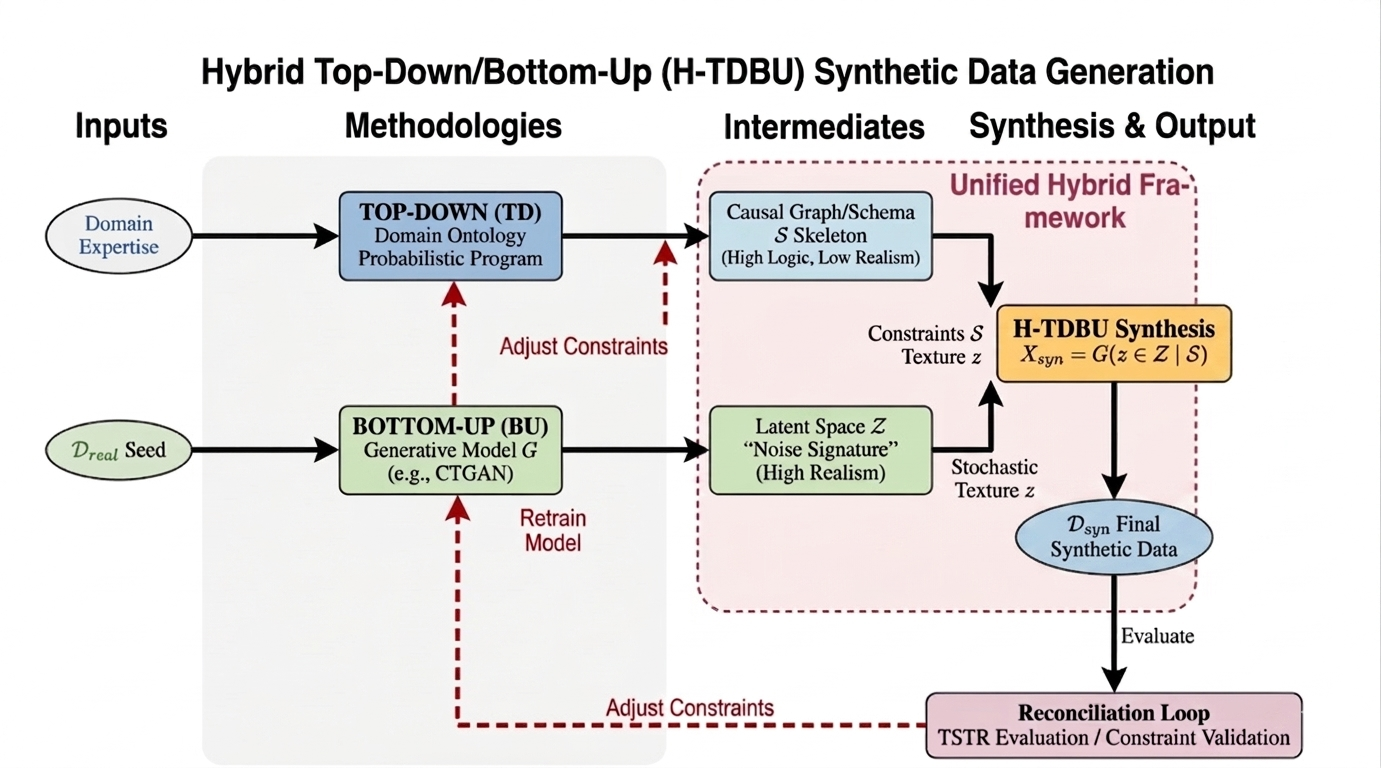
Figure 1: Unified Hybrid Top-Down/Bottom-Up (H-TDBU) framework, illustrating composite logical constraints (S) and latent stochastic generation (z), consolidated via a reconciliation feedback loop.
Empirical Evaluation and Results
Evaluation spans four canonical benchmarks: two weakly-aligned multimodal (Bank Marketing + FinancialPhraseBank) datasets—one with hand-crafted JSON rules and one with Gemini-3.1-generated rules—and the canonical Adult Income and German Credit UCI/Kaggle datasets. For the weak multimodal benchmarks, financial sentiment text is attached to tabular rows according to rule-provider alignment, and synthetic samples are evaluated by how well they preserve cross-modal structure and predictive utility.
Downstream utility is assessed using train-synthetic-test-real (TSTR) AUROC, F1, and accuracy. Fidelity metrics cover numeric mean/std deviation, total variation for categorical columns, and XModal (cross-modal discrepancy).
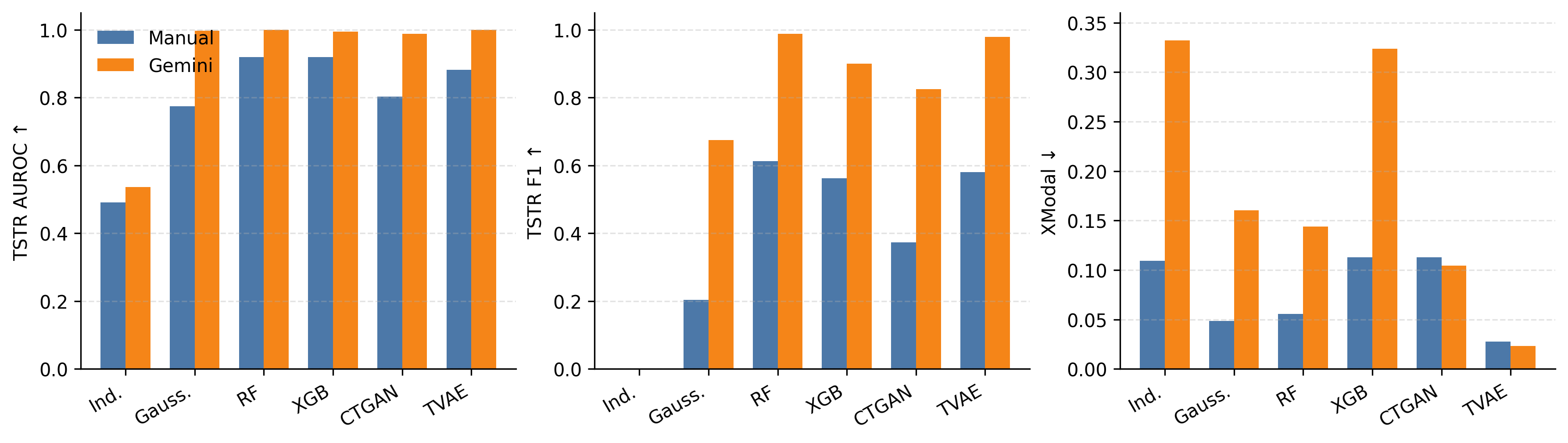
Figure 2: Weak multimodal comparison across synthesis methods, displaying TSTR AUROC, F1, and XModal. Higher AUROC and F1, and lower XModal, are preferable.
Results indicate that simple independent column samplers perform poorly across all metrics, confirming the necessity for conditional synthesis. Conditional ensemble generators (RandomForest, XGBoost) achieve competitive or superior downstream utility compared to compute-heavy neural baselines under both manual and LLM-generated rule regimes. For example, on the Gemini LLM-aligned multimodal benchmark, RandomForest achieves 0.9971 accuracy, 0.9878 F1, and 0.9998 AUROC; XGBoost achieves 0.9746/0.9003/0.9948, while TVAE attains 0.9885 AUROC and 0.9476 F1. In all cases, higher computational baseline methods (CTGAN, TVAE) are not strictly dominant and often lag in F1, especially in class-imbalanced regimes.
Further, in the strict Gemini alignment, tree-based methods display superior AUROC/F1 while neural generators (notably TVAE) sometimes achieve marginally better XModal fidelity, suggesting a nuanced trade-off between label-aligned utility and joint distributional preservation.
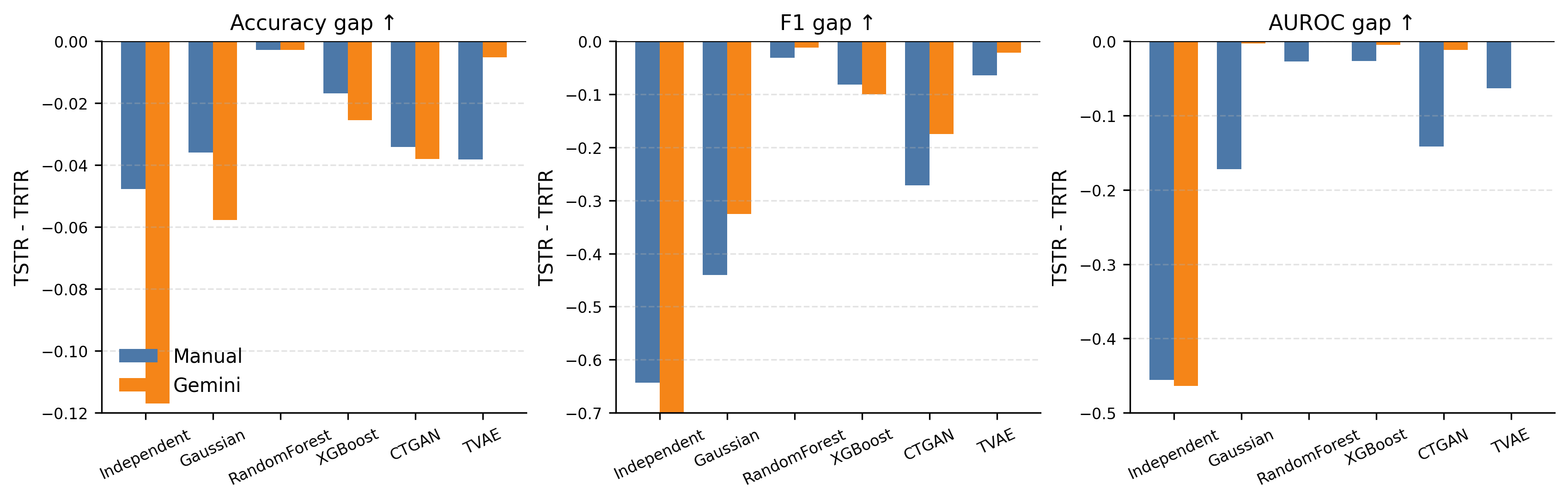
Figure 3: Weak multimodal utility gaps, indicating that smaller bars (closer to zero) signify less synthetic-to-real performance degradation by method.
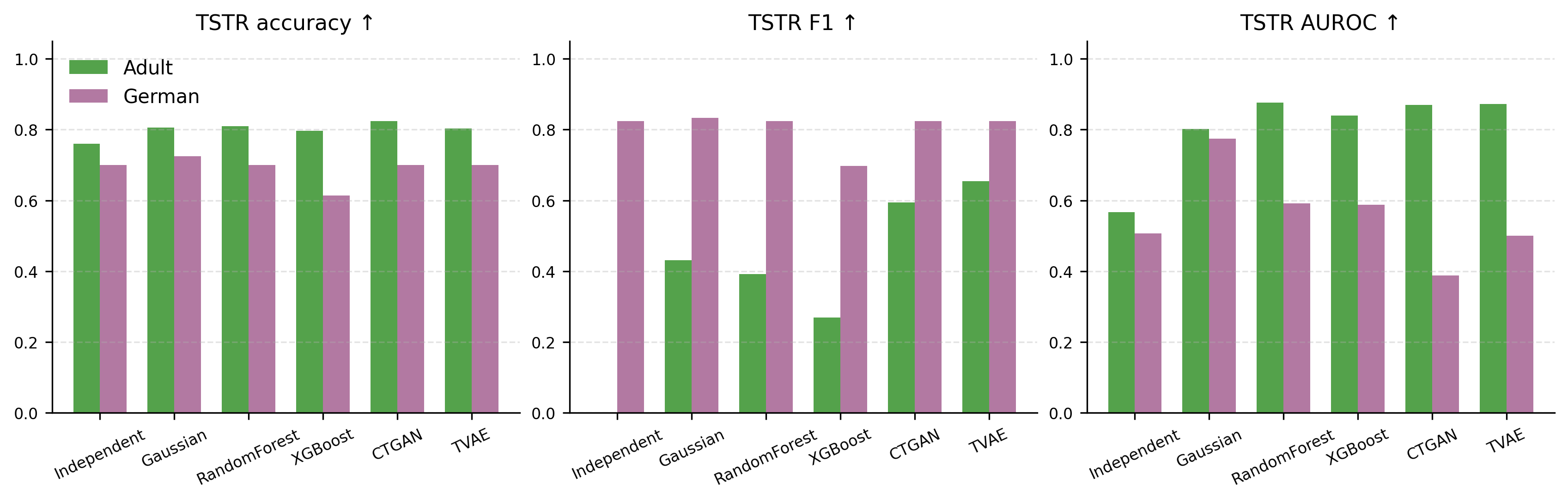
Figure 4: Tabular-only TSTR utility for Adult Income and German Credit. Higher columns indicate better synthetic-data utility preservation in non-multimodal settings.
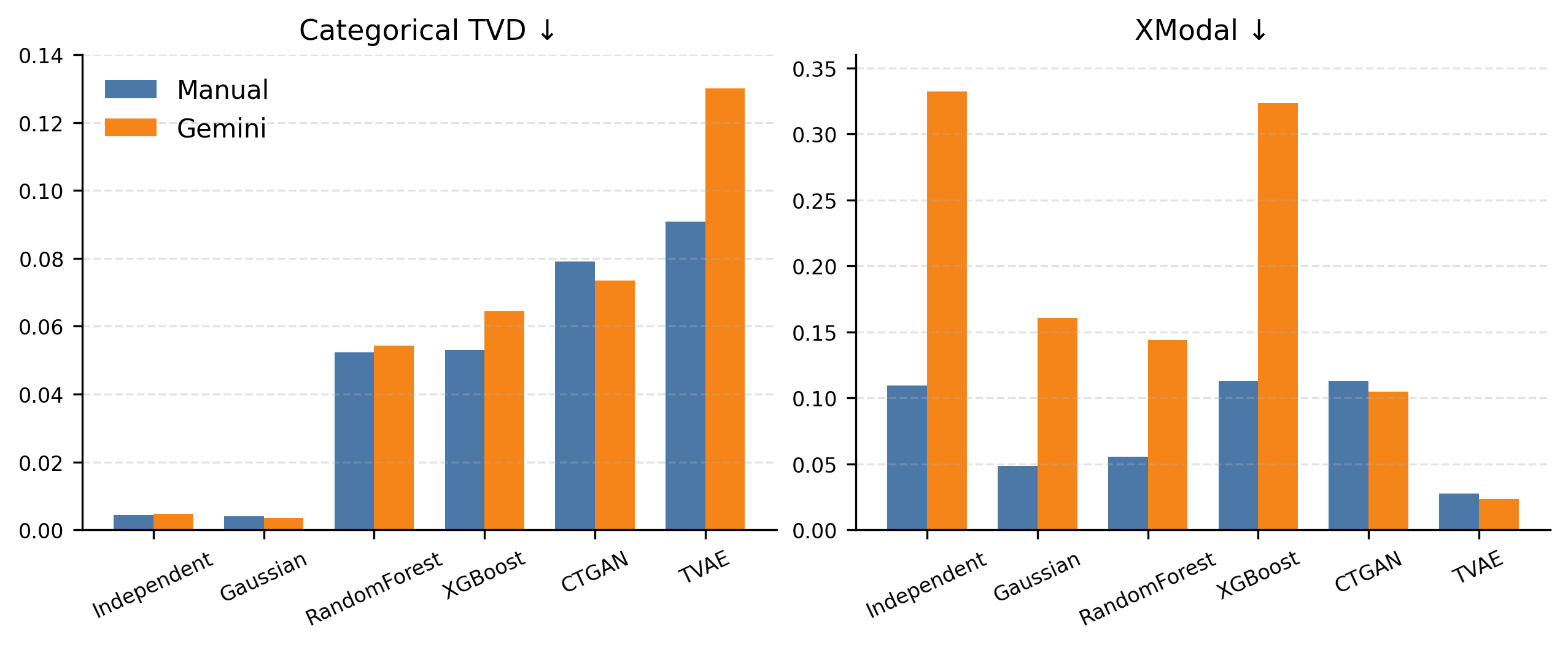
Figure 5: Weak multimodal fidelity metrics; lower categorical TVD and XModal values signal more faithful synthetic generation.
Ablation analysis on XGBoost demonstrates that, depending on rule-provider strictness, optimal conditioning depth varies: rich manual rules benefit from substantial conditioning (12 columns), while strict Gemini-generated alignments favor minimal dependencies (4 columns). This empirically confirms that top-down schema design fundamentally influences the statistical modeling strategy for optimal downstream performance.
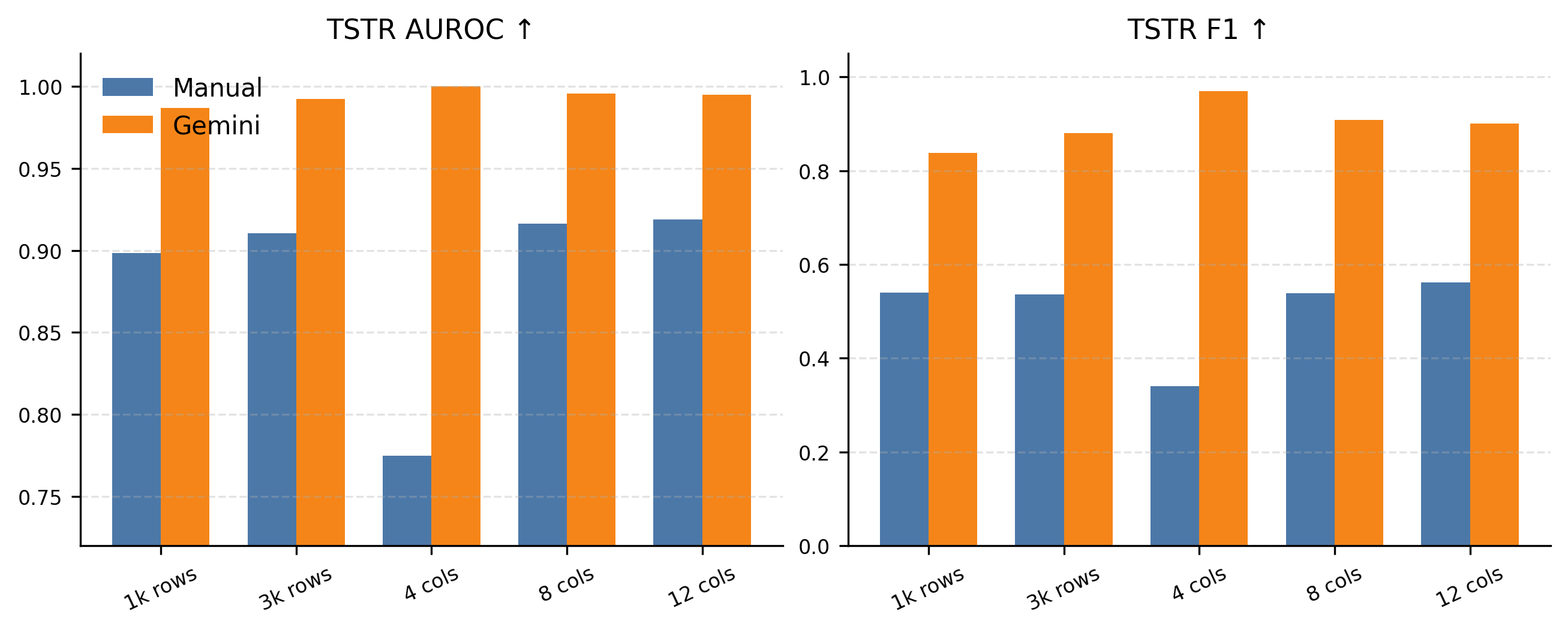
Figure 6: XGBoost ablation: impact of varying real-data sample size and conditioning context on synthetic-data utility.
Theoretical and Practical Implications
By amalgamating top-down semantic rule induction (manual or LLM-mediated) with bottom-up efficient texture modeling, the H-TDBU framework enables controllable, logically-coherent, and distributionally faithful synthetic data synthesis. This addresses several open challenges:
- Semantic Coherence and Rule Compliance: Logical dependencies and rare-event constraints are explicitly encoded, preventing the semantic incoherence common in autoregressive or unconditional neural generation.
- Computational Efficiency: The reliance on ensemble methods in the bottom-up path yields tractable training, particularly beneficial in low-data or bespoke-table settings where data sparsity and privacy constraints are paramount.
- Cross-Modal Integrity: The feedback-driven reconciliation loop ensures fidelity not only within-tabular, but also for attached modalities (e.g., textual attributes in financial records).
- Lineage and Interpretability: The explicit separation between rule schema and generative texture enables auditability and interpretability critical for high-stakes deployments in regulated industries.
Prospects for Future Research
Building on this hierarchical paradigm, future developments may target:
- Extending the schema definition language to richer dependency classes (e.g., relational integrity, causal rules).
- Automating rule extraction and schema construction from domain-specific corpora, lowering manual engineering costs.
- Incorporating more expressive, possibly hybrid, conditional generators in the bottom-up stream while preserving efficiency.
- Systematic exploration of distributional collapse in recursive hybrid synthetic training—feedback-induced errors propagation remains an open challenge.
- Formal benchmarking on privacy leakage, differential privacy guarantees, and rare-event generalization.
Conclusion
The H-TDBU framework substantiates the utility of decomposing synthetic tabular data generation into distinct semantic and statistical paths, harmonized via iterative validation and adjustment. This architecture achieves strong or state-of-the-art synthetic-to-real generalization performance and logical concession even under multimodal, low-sample, and stringent functional dependency settings. These findings highlight the necessity of principled semantic control coupled with robust statistical modeling for the next generation of enterprise synthetic data tools.