Unlocking the Working Memory of Large Language Models for Latent Reasoning
Abstract: To improve the reasoning capabilities of LLMs, test-time compute is typically scaled by generating intermediate tokens before the final answer. However, this couples reasoning to autoregressive generation and thereby conflates internal computation with external communication. In contrast, human cognition can use working memory to hold and manipulate information internally without the need to externalize intermediate thoughts. Drawing on this principle, we introduce Reasoning in Memory (RiM), a latent reasoning method that replaces the autoregressive generation of reasoning steps with memory blocks. These memory blocks are fixed sequences of special tokens that unlock the working-memory capacity of LLMs. Since they are fixed rather than generated, they can be processed in a single forward pass, enabling compute-efficient latent reasoning. To operationalize these memory blocks, we employ a two-stage curriculum. First, we ground them by predicting explicit reasoning steps after each memory block. Second, we discard this step-level supervision and iteratively refine the final answer after each memory block. Our experiments on reasoning benchmarks show that, across LLMs of different families and sizes, RiM matches or exceeds existing latent reasoning methods while avoiding the autoregressive generation of thoughts. These results demonstrate that LLMs can be trained to use working memory as an effective mechanism for latent reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Can a LLM “think in its head” instead of having to write out every step of its reasoning? The authors propose a new method called Reasoning in Memory (RiM) that gives the model a kind of working memory—like mental scratch paper—so it can plan and solve problems internally without typing out long chains of thought. This makes the model faster and more efficient while keeping or improving its accuracy on math word problems.
The big goals and questions
- Can we teach a LLM to do most of its reasoning internally, instead of “thinking out loud” step by step?
- How do we give the model a safe, structured place to store and manipulate ideas while it’s thinking?
- Does this internal-thinking method match or beat other popular methods in accuracy?
- Is it faster, and does it still work well across different model sizes and problem sets?
How the method works (in everyday language)
First, a few simple ideas:
- Tokens: Think of these as the smallest pieces of text a model reads or writes—like word pieces.
- Autoregressive generation: That’s when a model writes one token at a time, in order, like typing a sentence letter by letter. This is slow if the model must write many intermediate steps.
- Working memory: Humans often solve problems by holding and juggling pieces of information in their heads before speaking. The paper tries to give the model something similar.
Here’s the RiM idea:
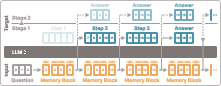
- Memory blocks: The authors insert special “blank” tokens into the model’s input. These tokens don’t mean anything by themselves. Instead, they act like empty sticky notes the model can use to store and transform information while it thinks.
- Single pass, not step-by-step: Because these memory blocks are fixed (they aren’t generated one by one), the model can process everything in one go, instead of slowly writing its thoughts token by token. This is much faster.
To teach the model how to use these memory blocks, the authors use a two-stage training plan:
- Stage 1: Grounding the memory
- Analogy: You give a student a notebook and teach them what kinds of notes to write at each page so they can solve problems better.
- In practice: After each memory block, the model is asked to predict the next reasoning step (like the next line of a solution). Crucially, the model is only allowed to “look” at the question and the memory blocks it has filled so far—not future steps. This forces the model to put useful information inside the memory blocks.
- Attention mask (simple view): Think of it like a classroom rule: “You can only look at your past notes and the question; no peeking at the answer sheet.” This rule ensures the model must truly use the memory blocks rather than cheating.
- Stage 2: Refining the final answer
- Analogy: Now that the student knows how to take good notes, we stop checking every intermediate step. Instead, after each memory block, we ask them to give their best final answer, improving it as they use more memory.
- In practice: The model predicts the final answer after each memory block. This trains it to steadily refine the answer as it “thinks” more internally, using the memory it has built up.
Because everything is processed together (not token-by-token generation), the model’s internal “thinking” becomes parallel and fast.
What they found and why it matters
Main results (in simple terms):
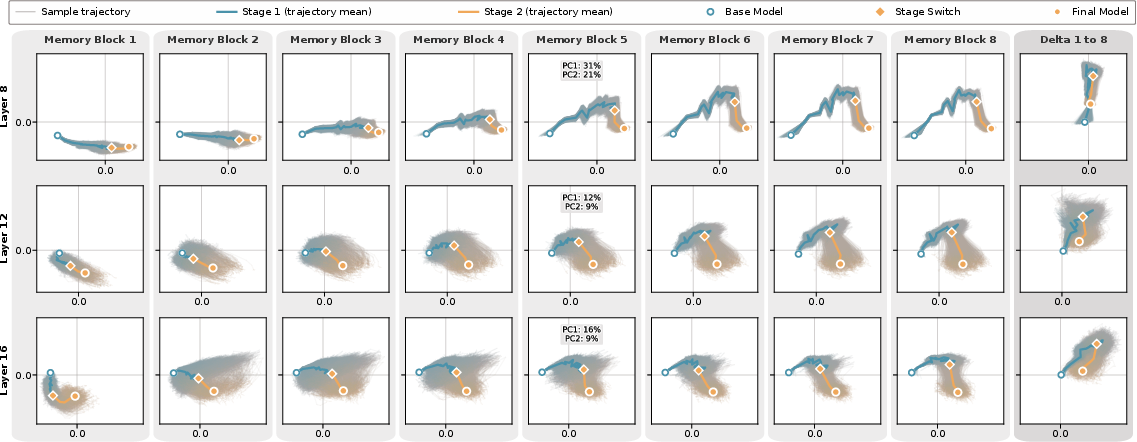
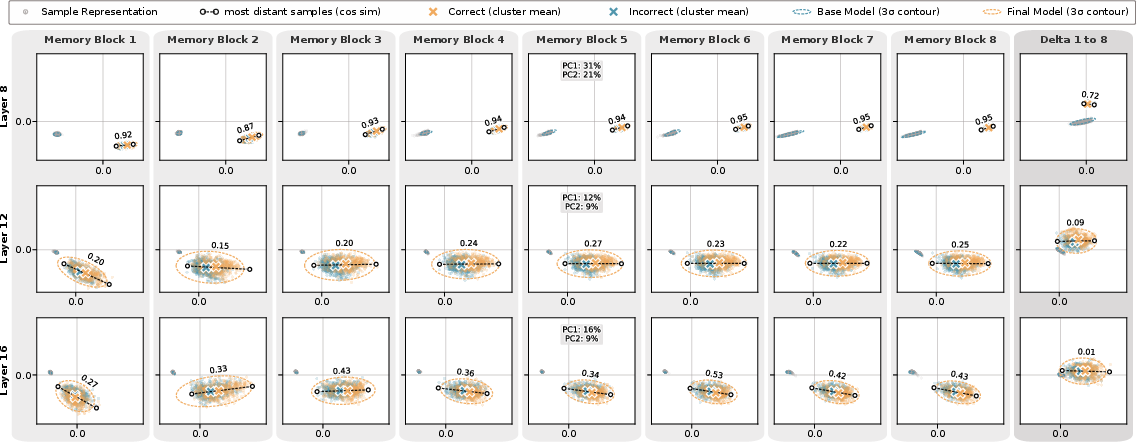
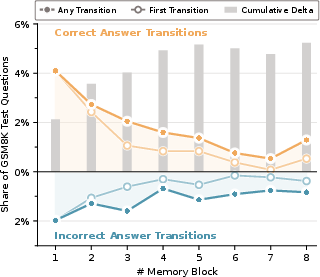
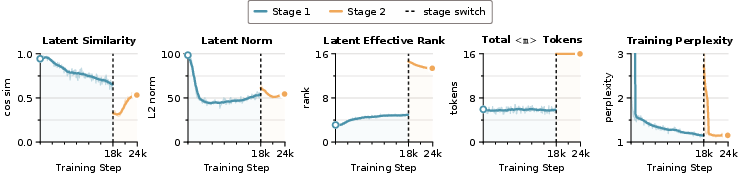
- The model actually uses the memory: The internal representations stored in the memory blocks change meaningfully with the question. In other words, those “blank sticky notes” are not ignored—they hold problem-specific information and evolve as the model learns.
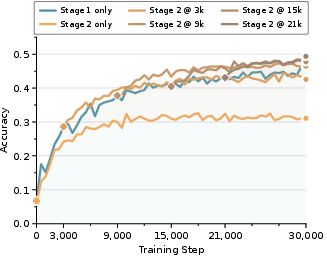
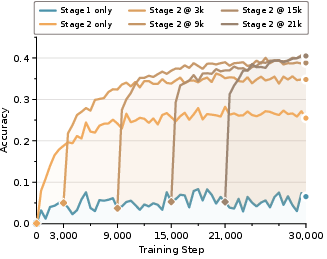
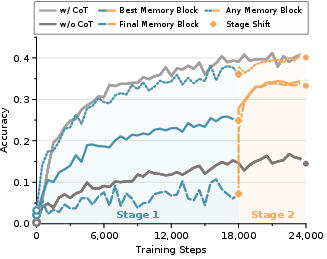
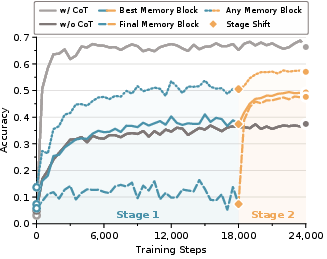
- Higher accuracy with less waiting: RiM matched or beat strong baselines on math word-problem benchmarks (like GSM8K and GSM-Hard).
- Compared to direct-answer training (no chain-of-thought), RiM improved accuracy by a noticeable margin.
- Compared to a popular latent method called Coconut (which still generates internal representations step by step), RiM performed better while being much faster.
- Compared to chain-of-thought (writing out steps), RiM often approached or even exceeded it—but with far less delay, because it doesn’t have to write long explanations.
- Much faster time-to-first-answer: Because RiM processes its memory blocks in one pass, it’s about as fast as giving a direct answer without showing work. In the paper’s tests, methods that generate intermediate steps were roughly 7x to 27x slower than RiM.
- Works across different models and settings: RiM was tested on GPT-2 and Llama-3.2 models of different sizes, and it held up on both in-distribution and harder out-of-distribution math problems.
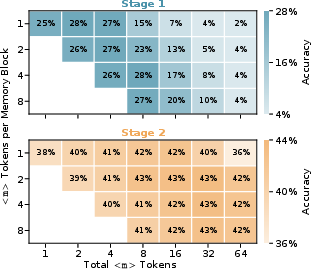
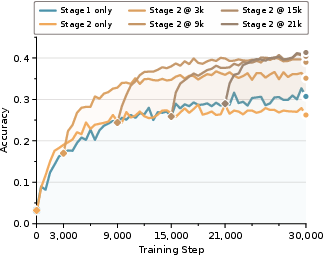
- Robust to different “memory budgets”: Whether the model was given more or fewer memory blocks, its performance stayed strong after training. As more memory blocks were added, the model often refined its answer, improving results rather than getting confused.
Why this matters:
- It shows that LLMs don’t have to “think out loud” to reason well. They can use an internal workspace like we do.
- It saves time and computing power because the model doesn’t need to write long chains of intermediate text or generate hidden steps one-by-one.
- Faster, stronger reasoning can make AI assistants more practical in classrooms, apps, and devices where speed and cost matter.
What this could change in the future
The idea of “separating thinking from speaking” could become a new standard in how we build reasoning AI:
- Cheaper and greener AI: Less computation during problem solving means less energy and cost.
- Better human-like thinking: This pushes AI systems closer to how people use working memory, which might make them more flexible and reliable.
- Easy to combine: RiM could be mixed with other techniques—like occasionally showing steps for very tricky problems or using reinforcement learning to further polish the final answers.
- More general use: Beyond math problems, this internal-memory approach could help with planning, multi-step instructions, and other complex tasks.
In short, the paper shows a promising way to unlock a LLM’s “mental scratch pad,” letting it think quickly and quietly before giving you a clear, final answer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Task and domain generality: Evaluate RiM beyond grade-school math (GSM8K/GSM-Hard) on diverse reasoning types (commonsense, symbolic logic, code generation, multi-hop QA, tool use, retrieval-augmented tasks, long-context reasoning, multi-turn dialogue).
- Cross-lingual applicability: Assess whether memory blocks transfer to non-English settings and tokenization schemes, and whether language-specific tokenization interacts with special tokens.
- Dependence on step-level supervision: Stage 1 requires segmented reasoning steps; study performance when such supervision is noisy, missing, self-generated, weakly labeled, or learned via unsupervised/JEPA objectives or RL from final answers.
- Segmentation strategy sensitivity: Quantify how the quality and granularity of reasoning-step segmentation affect Stage 1 learning and downstream accuracy.
- Scalability to long reasoning chains: Test RiM when problems require many more than 13 steps; characterize how accuracy and compute scale with large , , and .
- Adaptive compute budgeting: Develop and test mechanisms to adaptively choose the number of memory blocks at inference (halting/early-exit policies, confidence-based stopping) to realize the “any-block” performance without oracle selection.
- Final-answer stability and calibration: Analyze monotonicity and oscillations of answers across blocks; improve calibration so additional blocks rarely degrade correct answers, and quantify uncertainty estimates per block.
- Optimal memory design: Systematically explore placement (prepend vs append vs interleaved), density, and spacing of memory blocks; investigate dynamic or learned block sizes, variable per block, and learned delimiters vs fixed
<b>,</b>. - Architectural variants: Test RiM with encoder–decoder models, bidirectional layers, Mixture-of-Experts, state-space models, and recurrent refinement layers to validate the generality of the attention mask and training procedure.
- Attention mask ablations: Quantify the necessity of each masking constraint; measure leakage risks, optimization stability, and whether simpler masks can work without harming learning.
- Parameter freezing choices: The paper freezes existing token embeddings; ablate this design (unfreeze all embeddings, tie special-token embeddings, LoRA/PEFT) to assess trade-offs in interference vs capacity.
- Mechanistic interpretability: Move beyond PCA/probes to causally test what is stored/manipulated in memory blocks (e.g., intervention on block representations, attention flow analyses, circuit-level studies, sparse-probe concepts).
- Larger-scale validation: Evaluate RiM on larger model families (≥7B, ≥70B) to test scaling laws, memory capacity vs model size, and whether benefits persist or grow.
- Comparisons to stronger baselines: Include vertical latent reasoning (HRM/TRM), process reward models, search-based CoT (e.g., Tree-of-Thought, Best-of-N with higher N), verifier-guided decoding, and modern self-consistency regimes to ensure fairness at comparable training/inference budgets.
- Training compute parity: Report and control for total training FLOPs across methods (including DART and Coconut variants) to disambiguate algorithmic gains from extra compute or epochs.
- End-to-end latency and throughput: Report full latency (not just TTFT), throughput, and memory footprint vs and under realistic batching; quantify the input-length overhead and GPU memory usage at deployment scales.
- Robustness and OOD stress tests: Evaluate against adversarially perturbed prompts, distribution shifts beyond GSM-Hard, longer contexts, distractors, and compositional generalization suites.
- Any-block to deployable bridging: Develop practical strategies (confidence scoring, verification heads, lightweight probes) to choose the best block at inference without extra labels, closing the gap between final-block and any-block accuracy in a deployable manner.
- Curriculum sensitivity: Provide ablations on the Stage 1 annealing schedule and Stage 2 weighting; characterize stability to hyperparameters, seeds, and optimizer settings; explore whether direct Stage 2 training (without Stage 1) can succeed with alternative signals.
- Integration with tools: Test whether memory blocks can coordinate with tool use (calculator, code interpreter, retrieval), including how to store tool inputs/outputs within the latent workspace.
- Pretraining vs finetuning: Investigate benefits/risks of introducing memory blocks during pretraining vs only during finetuning, and whether pretraining with special tokens improves downstream performance.
- Failure mode analysis: Characterize systematic errors (e.g., arithmetic carry mistakes, multi-step logical errors) and whether particular blocks encode brittle shortcuts; study how errors propagate across blocks.
- Safety and controllability: Assess whether latent memory introduces new risks (hidden reasoning states, jailbreaking vectors) and how to audit/control internal computation.
- Reproducibility and release: Clarify code/resources, checkpoint selection protocol (using GSM8K for selection), and statistical variability; provide seeds and significance tests to support replicability.
- Hybrid explicit–latent strategies: Explore mixing RiM with sparse explicit CoT (e.g., short external traces plus memory refinement) and RL with final-answer/process rewards, as hinted by the authors, to push beyond current ceilings.
Practical Applications
Immediate Applications
These applications can be deployed with today’s LLMs by fine‑tuning with the two‑stage RiM curriculum and using fixed memory blocks at inference.
- Latency‑sensitive customer support and search assistants (sector: software, customer service)
- What: Replace chain‑of‑thought (CoT) prompting with RiM to keep “thinking” internal and respond in a single forward pass.
- Tools/products/workflows: Fine‑tuned RiM adapters (e.g., LoRA) that add special memory tokens and a custom attention mask; inference servers exposing a “memory budget K” knob; fallback to best‑block or final‑block readouts depending on SLA.
- Assumptions/dependencies: Access to open‑weights models; ability to modify attention masks in the serving stack; availability or generation of step‑level supervision for Stage 1 (e.g., auto‑generated CoT traces).
- On‑device/mobile assistants (sector: consumer tech)
- What: Faster, lower‑energy reasoning for keyboards, smart home, and offline assistants by avoiding autoregressive intermediate tokens.
- Tools/products/workflows: Tiny/compact models (≤3B) fine‑tuned with RiM; device‑side “anytime answer” using progressively more memory blocks when the device is idle.
- Assumptions/dependencies: Edge‑deployable models; tailored training data for target tasks; careful memory‑budget tuning per device.
- STEM tutoring and formative feedback (sector: education)
- What: Math/logic tutors that deliver quick feedback without verbose CoT; optionally surface a short explanation only on demand.
- Tools/products/workflows: RiM fine‑tuning on math datasets; “any‑block” probing to detect when a correct answer emerges early; UI that supports fast retries with adjusted memory budget.
- Assumptions/dependencies: Domain‑relevant stepwise datasets or synthetic traces; content safety and pedagogy review.
- Low‑latency coding assistants and CI bots (sector: software engineering)
- What: Internal reasoning for code completion, bug localization, or quick lint/fix suggestions with near direct‑answer latency.
- Tools/products/workflows: IDE plugins that pass fixed memory blocks; CI pipelines that escalate K only on uncertainty; lightweight probes to choose the best intermediate readout.
- Assumptions/dependencies: Code reasoning datasets (e.g., with step decompositions); integration into IDE/server infrastructure; uncertainty estimation or probe calibration.
- Real‑time triage and routing (sector: healthcare operations, emergency response; policy operations)
- What: Fast, structured triage/routing recommendations with constrained compute budgets (call centers, hospital ops).
- Tools/products/workflows: RiM‑fine‑tuned models on rule‑/protocol‑based datasets; “final‑block” deployment to minimize TTFT; audit logs that store inputs and final outputs.
- Assumptions/dependencies: Non‑diagnostic use unless medically validated; domain‑specific training; compliance and human oversight.
- Automated compliance and rule evaluation (sector: finance, legal ops)
- What: Execute compliance checklists and simple risk screens quickly without token‑heavy reasoning chains.
- Tools/products/workflows: RiM models trained on regulatory Q&A + synthetic step traces; rule engines that gate escalating K for complex cases; monitoring for drift.
- Assumptions/dependencies: Curated domain corpora; rigorous validation; human‑in‑the‑loop for high‑risk outputs.
- Retrieval‑Augmented Generation (RAG) with single‑pass integration (sector: enterprise software, knowledge management)
- What: Use memory blocks to fuse retrieved passages and refine the final answer in one pass.
- Tools/products/workflows: RAG pipeline that prepends retrieved snippets before memory blocks; RiM Stage 2 fine‑tuning on RAG‑style tasks; budgeted K per query difficulty/length.
- Assumptions/dependencies: Training data reflecting retrieval contexts; infrastructure that supports custom masks.
- Cloud cost and energy reduction for LLM services (sector: infrastructure/DevOps)
- What: Lower GPU time and token emissions by cutting autoregressive “thought” generation while maintaining or increasing accuracy.
- Tools/products/workflows: Replace CoT paths with RiM variants; autoscaling policies keyed to memory budget rather than generation steps; per‑tenant budget controls.
- Assumptions/dependencies: Fine‑tuning capacity; ops ability to ship custom attention masks; benchmark‑backed SLOs.
- Safety and quality monitoring via latent probes (sector: AI safety, compliance)
- What: Train linear probes on memory‑block states to flag toxic, non‑compliant, or hallucination‑prone trajectories mid‑inference.
- Tools/products/workflows: Probe training with safety labels; gate final‑block readouts on probe scores; logs for red‑team analysis.
- Assumptions/dependencies: Labeled safety datasets; careful calibration to reduce false positives; privacy controls for latent state logging.
- Latency‑aware robotics and automation (sector: robotics, manufacturing)
- What: Planning and instruction following with tight control‑loop budgets using single‑pass reasoning in memory.
- Tools/products/workflows: RiM‑trained task planners; controller integrates K escalation only when the robot is quiescent; safety interlocks.
- Assumptions/dependencies: Task‑specific datasets; real‑time constraints; co‑design with planners/controllers.
Long‑Term Applications
These applications will benefit from further research, scaling, domain adaptation, or infrastructure evolution.
- RiM‑native pretraining and tokenizer design (sector: AI research, foundation models)
- What: Integrate memory blocks during pretraining so models internalize working‑memory use across domains.
- Tools/products/workflows: Pretraining corpora that include step‑structured tasks; learned schedules for K and M; evaluation suites for latent reasoning.
- Assumptions/dependencies: Significant pretraining compute; tokenizer and architecture changes; stability across long contexts.
- Stage‑2 reinforcement learning with final‑answer rewards (sector: AI research; cross‑sector applications)
- What: Optimize latent reasoning trajectories using RLHF/RLAIF rewards on correctness, safety, and calibration.
- Tools/products/workflows: Reward models that score final answers and consistency across blocks; curriculum to avoid reward hacking.
- Assumptions/dependencies: High‑quality reward signals; safety oversight; compute budgets.
- Explainability and audit products for implicit reasoning (sector: enterprise compliance, regulated industries)
- What: Tools that visualize memory‑block trajectories, probe concepts, and produce minimal, human‑readable rationales when required.
- Tools/products/workflows: PCA/UMAP dashboards for block representations; causal/probing libraries; selective CoT “distillation” from memory states.
- Assumptions/dependencies: Stable mappings from latent states to interpretable features; acceptance by auditors/regulators.
- Hybrid explicit–implicit reasoning for high‑stakes domains (sector: healthcare, finance, law)
- What: Use RiM for most queries; selectively emit short explicit steps for auditing or training when confidence is low.
- Tools/products/workflows: Confidence gating; sparse “explain on demand” generation aligned with the latent workspace; human review loops.
- Assumptions/dependencies: Reliable uncertainty estimation; methods to avoid exposing sensitive latent content.
- Memory‑budget APIs and dynamic compute markets (sector: AI platforms/SaaS)
- What: Expose “memory budget K” and “block size M” as first‑class knobs to trade accuracy vs. latency/cost per request or tenant.
- Tools/products/workflows: SLA‑aware routers; per‑tenant pricing; telemetry to auto‑tune budgets.
- Assumptions/dependencies: Robust performance across budgets; customer education and guardrails.
- Hardware–software co‑design for single‑pass latent reasoning (sector: semiconductor, cloud)
- What: Accelerators and kernels optimized for custom causal masks and dense readouts across memory blocks.
- Tools/products/workflows: Fused attention/masking primitives; compiler support for multi‑readout heads; caching for repeated block sizes.
- Assumptions/dependencies: Vendor support; standardized RiM‑like patterns.
- Public sector and sustainability policy (sector: policy)
- What: Encourage energy‑efficient AI deployments by favoring single‑pass latent reasoning over token‑heavy CoT for routine services.
- Tools/products/workflows: Procurement guidelines; benchmarks linking latency/energy to accuracy; green AI certifications.
- Assumptions/dependencies: Transparent reporting; standardized test suites across tasks beyond math.
- Privacy‑preserving domain deployments (sector: healthcare, finance, government)
- What: On‑prem/offline RiM models that meet strict data‑residency and energy constraints while offering improved reasoning.
- Tools/products/workflows: Local fine‑tuning with domain‑specific step traces; on‑device confidence gating; logging policies that exclude latent states.
- Assumptions/dependencies: Domain adaptation; regulatory approval; robust monitoring.
- Long‑document synthesis with compressed latent workspaces (sector: media, legal, research)
- What: Use memory blocks to iteratively integrate long‑context evidence without expanding token generation steps.
- Tools/products/workflows: RAG + RiM with segment‑wise integration into blocks; hierarchical memory schedules; verification passes.
- Assumptions/dependencies: Training on long‑context tasks; methods to prevent information bottlenecks.
- Cognitive science and neuro‑symbolic research (sector: academia)
- What: Experimental platforms to study working memory in LLMs and compare to human task performance and load manipulation.
- Tools/products/workflows: Behavioral protocols that vary K/M as “working memory load”; analysis of interference and chunking.
- Assumptions/dependencies: Interdisciplinary datasets; reproducibility across labs.
Common assumptions and dependencies across applications
- Data: Stage 1 benefits from step‑level supervision; for new domains, explicit reasoning steps may need to be curated or synthesized.
- Models: Access to models that allow fine‑tuning, adding special tokens, and custom causal masks (most modern frameworks support this with minor engineering).
- Generalization: Reported gains are on math benchmarks and small‑to‑mid models; transfer to other domains and larger models should be validated.
- Safety and compliance: Even with internal reasoning, outputs require domain‑specific validation, monitoring, and (where needed) human oversight.
- Infrastructure: Serving stacks must support extra input tokens (memory blocks) and multiple readouts; monitoring should track accuracy–latency trade‑offs.
Glossary
- Answer readout: A decoding head placed after a memory block to generate the final answer tokens. "After each memory block , we attach an answer readout and train it to predict the final answer ."
- Annealing: Gradually decreasing supervision weights over training steps to realize a soft curriculum. "Annealing yields a soft multi-stage reasoning curriculum in which all readouts receive dense supervision early in training, before supervision is gradually removed from earlier reasoning steps first and later reasoning steps last."
- Any-block accuracy: An evaluation metric that counts a sample as correct if any memory-block readout produces the correct answer. "any-block accuracy counts a sample as correct if any memory-block readout produces the correct answer."
- Anytime answer objective: Training objective where each intermediate readout predicts the final answer, enabling valid outputs at any intermediate budget. "Stage~2 uses a fixed number of memory blocks and trains the model with an anytime answer objective, matching the inference-time setting more closely."
- Attention mask: A constraint on token attention that controls which positions can attend to which others during training/inference. "we employ a custom attention mask so each readout can attend to the memory blocks, and optionally to the question, but not to other written reasoning steps (\Cref{fig:rim_attention_mask})."
- Autoregressive generation: Sequentially producing tokens (or states) where each step conditions on previously generated outputs. "However, this couples reasoning to autoregressive generation and thereby conflates internal computation with external communication."
- Autoregressive LLM: A model that predicts each token conditioned on all previous tokens. "denote the parameters of an autoregressive LLM."
- Best-block accuracy: Accuracy of the single memory-block readout that performs best for each example. "best-block accuracy reports the accuracy of the single best memory block"
- Causal mask: An attention mask enforcing causality so each position can only attend to allowed prior context. "We use the same custom causal mask as in Stage~1, so each readout can attend only to the question and the memory blocks available up to that point."
- Chain-of-thought (CoT) prompting: A technique that elicits intermediate textual reasoning steps to improve problem solving. "Chain-of-thought (CoT) prompting \citep{Wei:22,Kojima:22} showed that LLMs solve harder tasks when intermediate computation is externalized as text."
- Checkpoint selection: Choosing which training checkpoint to evaluate/deploy based on a validation criterion. "we reserve 264 held-out GSM8K samples for checkpoint selection"
- Coconut: A latent reasoning method that replaces discrete reasoning tokens with autoregressively fed-back continuous representations. "Coconut \citep{Hao:25} is the closest latent analogue of CoT, as it replaces discrete reasoning tokens with continuous representations that are fed back autoregressively."
- Continuous representations: Vector-valued latent states used instead of discrete tokens to carry intermediate computation. "Recent advances in latent reasoning bypass these natural-language constraints by replacing discrete tokens with continuous representations \citep{Hao:25, Shen:25, Cheng:24}."
- Continuous thoughts (CTs): Coconut’s continuous latent steps that substitute for written reasoning tokens. "While Coconut \citep{Hao:25} uses multiple curriculum stages to train continuous thoughts (CTs),"
- DART: A method showing filler-token reasoning via a two-pathway self-distillation framework with auxiliary modules/losses. "More recently, DART shows that filler tokens can be trained without specific pretraining, but finetuning requires a two-pathway self-distillation framework with an auxiliary “Reasoning Evolvement Module” and multiple auxiliary losses \citep{Deng:24}."
- Dense supervision: Providing many supervised signals per example, often at multiple positions, to strengthen learning. "keeping optimization simple while still providing dense supervision over the latent workspace."
- Filler tokens: Tokens without predefined semantic content used to allocate latent computation. "Another line of work studies whether intermediate computation can be allocated to tokens without predefined semantic content, which we collectively refer to as filler tokens."
- Final-block accuracy: Accuracy measured from the last (deployable) memory-block readout under a fixed budget. "Final-block accuracy corresponds to the deployable fixed-budget setting used in the main comparison below"
- Greedy accuracy: Accuracy when decoding deterministically without sampling (e.g., argmax at each step). "choosing the checkpoint with the highest greedy accuracy for each model-method combination."
- HRM: An iterative latent reasoning model employing recurrent refinement of activations. "Stage~2 is inspired by iterative latent reasoning models such as HRM \citep{WangHRM:25} and TRM \citep{Martineau:25}"
- In-distribution (ID): Test data drawn from the same distribution as training data. "use GSM8K \citep{Cobbe:21} as the in-distribution (ID) test set"
- Inference-time memory budgets: The number/size of memory blocks allocated at inference to control computational effort. "Finally, we examine whether RiM maintains strong performance across inference-time memory budgets and how final answers evolve as more memory blocks are provided."
- Input embedding: The vector embedding fed into the model at the next step (often constructed from prior hidden states). "The resulting representation is then fed back as the input embedding at the next decoding step."
- JEPA: A predictive representation learning paradigm aligning latent states by predicting missing structure. "Stage~1 is closely aligned with JEPA-style predictive representation learning because fixed memory blocks learn to predict missing reasoning structure, turning them into parallel latent states for working memory \citep{LeCun:22,Assran:23}."
- Latent reasoning: Performing intermediate computation in hidden (often continuous) space rather than explicit text. "Recent advances in latent reasoning bypass these natural-language constraints by replacing discrete tokens with continuous representations \citep{Hao:25, Shen:25, Cheng:24}."
- Latent workspace: A segment of latent positions used to store and manipulate intermediate computations. "serve as a latent workspace for intermediate computation."
- Memory blocks: Fixed sequences of special tokens that function as working memory for internal reasoning. "we introduce Reasoning in Memory (RiM), a latent reasoning method that replaces the autoregressive generation of reasoning steps with memory blocks."
- Next-token prediction: The standard language modeling objective of predicting the next token given context. "Both stages use the same simple objective, standard next-token prediction, but with different targets."
- Out-of-distribution (OOD): Test data deliberately different from training distribution to assess generalization. "GSM-Hard \citep{Gao:23} as an out-of-distribution (OOD) test set"
- Pass@8: The probability of producing a correct answer when sampling 8 completions. "The pass@8 accuracies, obtained by sampling 8 answers with temperature 1, show the same pattern."
- Penultimate-layer representation: The hidden activation from the second-to-last layer, often used for analysis. "we collect the penultimate-layer representation of each memory block per GSM8K test question."
- Process reward models: Models that score and verify intermediate reasoning steps during training or inference. "process reward models that verify intermediate steps \citep{Lightman:24,Snell:24}."
- Readout: A supervised prediction head that decodes a target (step or final answer) from latent states. "we therefore ground the memory blocks by supervising the readout after each block to predict the corresponding next reasoning step."
- Self-distillation: Training a model using signals generated by the model itself (often via auxiliary pathways). "a two-pathway self-distillation framework"
- Sparse-autoencoder concepts: Interpretable latent features extracted via sparse autoencoders for reasoning. "sparse-autoencoder concepts \citep{Tack:25}"
- Supervised fine-tuning (SFT): Finetuning a pretrained model on labeled data to specialize it for a task. "we include supervised fine-tuning (SFT) \citep{Muennighoff:25} in two variants."
- Test-time compute: Computational budget expended at inference, often increased by generating intermediate steps. "test-time compute is typically scaled by generating intermediate tokens before the final answer."
- Time to first token (TTFT): Latency until the first generated token is produced during inference. "we also report the time to first token (TTFT) per sample in milliseconds (ms)"
- TRM: A refinement-style latent reasoning model related to HRM. "Stage~2 is inspired by iterative latent reasoning models such as HRM \citep{WangHRM:25} and TRM \citep{Martineau:25}"
- Working memory: An internal workspace that maintains and manipulates information without externalizing steps. "human cognition can use working memory to hold and manipulate information internally without the need to externalize intermediate thoughts."
Collections
Sign up for free to add this paper to one or more collections.