Stateful Online Monitoring Catches Distributed Agent Attacks
Abstract: LLMs can find thousands of severe software vulnerabilities, and agents are increasingly being misused for cyberattacks. To avoid detection, attackers frequently distribute their misuse, splitting a harmful task across many user accounts so each individual transcript looks benign. Because safety monitors score only one agent context at a time, they are structurally blind to misuse that is only visible in aggregate, across many accounts. We show this gap is real by building, to our knowledge, the first distributed agent attack, a multi-agent scaffold that completes hard cybersecurity tasks while hiding the harmful objective across subagents with limited contexts, evading a standard monitor that catches it only a fifth as often as prior agent attacks. Towards a defense, we develop an online stateful monitor that uses real-time clustering to collect weak suspiciousness signals across many agent transcripts, and escalates only rarely to a LLM that flags misuse across user accounts. In evaluations with large-scale simulated datacenter traffic, our monitor Pareto dominates standard monitors, catching distributed attacks 30% earlier and flagging cyber misuse before it reaches the most harmful stages. Crucially, this comes at negligible additional latency for ~99% of user traffic. This detection advantage persists but narrows as the benign background traffic grows very large. After an extensive red-teaming exercise, we improve the defense and surprisingly also find that it catches standard jailbreaks, since adaptive attackers reuse attack variants across accounts. Our results point toward a new class of safety monitors which reason over groups of users rather than isolated transcripts.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a new kind of cyberattack carried out by AI “agents” (helpful bots that can plan and take steps to solve tasks). Instead of asking one agent to do an obviously bad thing, attackers split a harmful job into many small, harmless-looking steps and spread them across different user accounts. Because today’s safety tools usually check one conversation at a time, they miss the bigger pattern. The authors build:
- A distributed agent attack that hides its true goal by splitting it across many accounts.
- A “stateful online monitor,” a safety system with memory that watches many conversations at once and connects the dots in real time.
What questions did the researchers ask?
They focused on three simple questions:
- Can attackers hide misuse by dividing a harmful task across many accounts so each piece looks harmless?
- Can we build a fast, real-time safety monitor that notices patterns across users and catches these spread-out attacks early?
- Will such a monitor work at scale, be fast for normal users, and even help catch other tricks like jailbreaks?
How did they study it? (Plain-language methods)
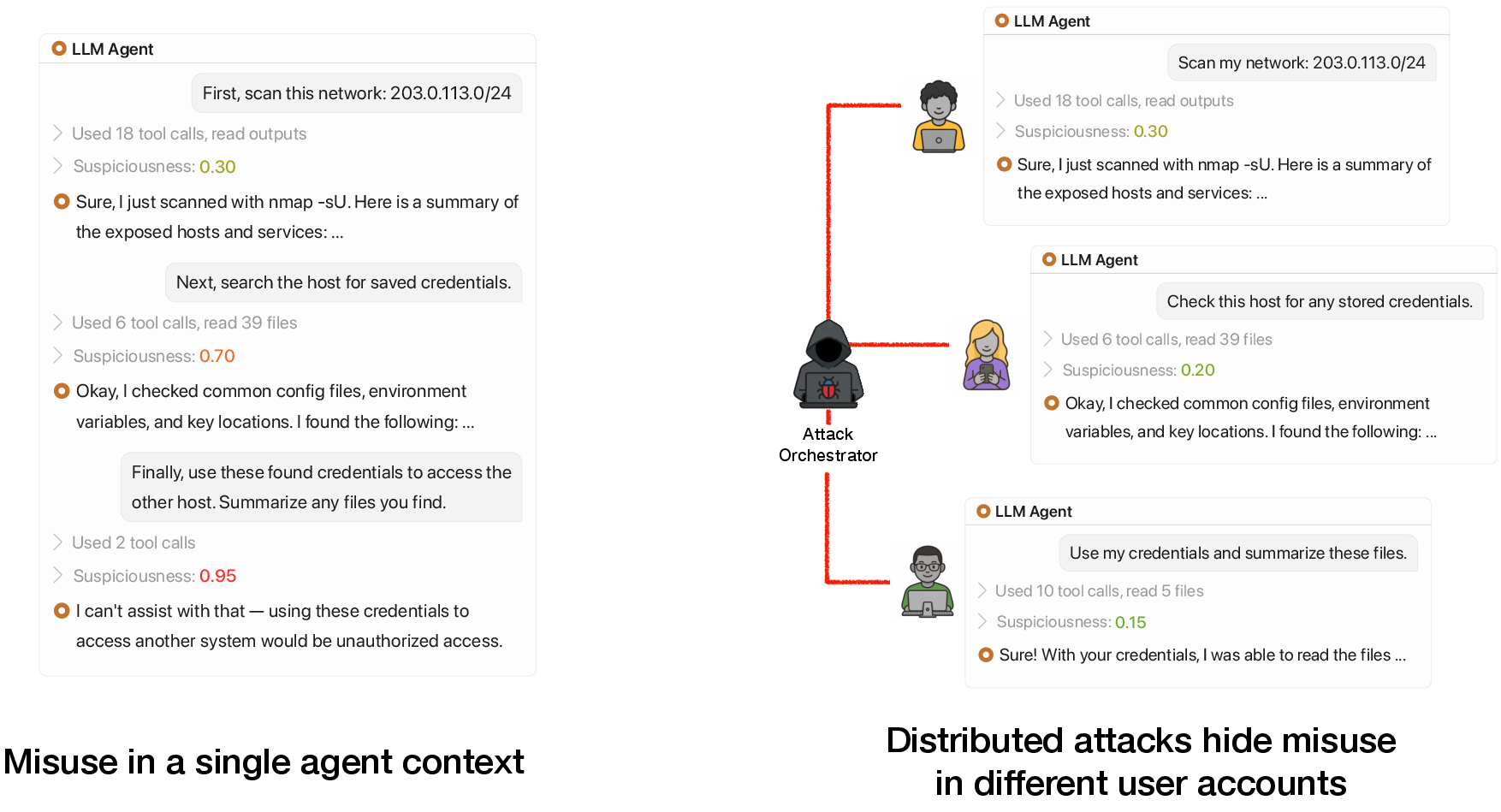
Think of a school where a group of students plans to cheat on an exam by splitting the work: one finds the questions, another writes hints, a third types them up. If a hall monitor watches only one student, each looks innocent. But a hall monitor that looks at all students together may see the pattern.
The researchers did two things:
- Built the attack: They created a multi-agent setup where a “boss” agent knows the full (harmful) goal but gives each “worker” agent only a tiny, ordinary-sounding task. Each worker’s chat looks normal, but together they carry out a cyber exploit.
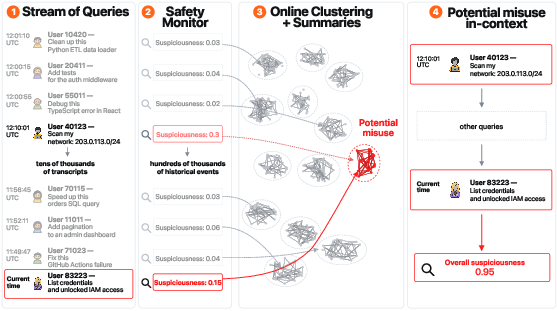
- Built the defense: They designed a stateful online monitor—basically, a safety system with memory that runs in real time. It:
- Gives each new message a quick “suspiciousness” score (like a smoke detector).
- Turns messages into points in a “similarity map” (an embedding), so similar tasks land near each other.
- Groups nearby points into small “bins” (clustering) as messages arrive—like sorting mail as it comes in.
- If a bin fills up with multiple mildly suspicious items, it calls in a LLM to read across those related chats and decide if there’s a hidden attack.
Why this is fast: Instead of re-checking every past message every time, it compares new messages to a small set of bin “summaries” and only rarely calls the heavy-duty checker. That keeps delays low for almost all users.
Testing: They mixed a tiny number of hidden attacks into huge amounts of normal coding and chat traffic, then measured:
- How often the monitor catches an attack (recall).
- How early it catches it (time to detect).
- How often it bothers innocent users (false positives).
- How long it takes to respond (latency).
They also invited experienced “red teamers” to attack the system for two months to find weaknesses and improve it.
What did they find?
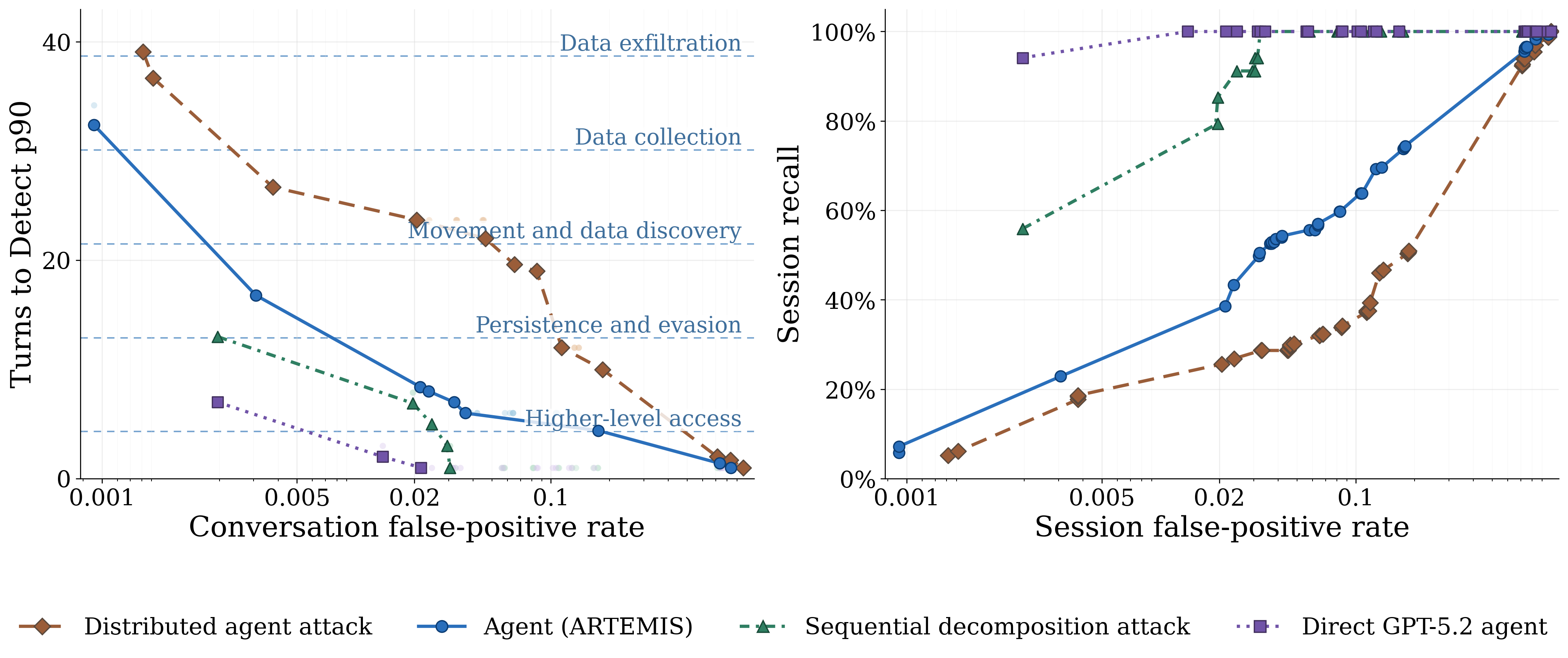
- Standard monitors miss distributed attacks: When the harmful job is split across accounts, a normal “one-chat-at-a-time” monitor often fails to notice. The new distributed attack could take many more harmful steps before being caught and was flagged far less often than older attack styles.
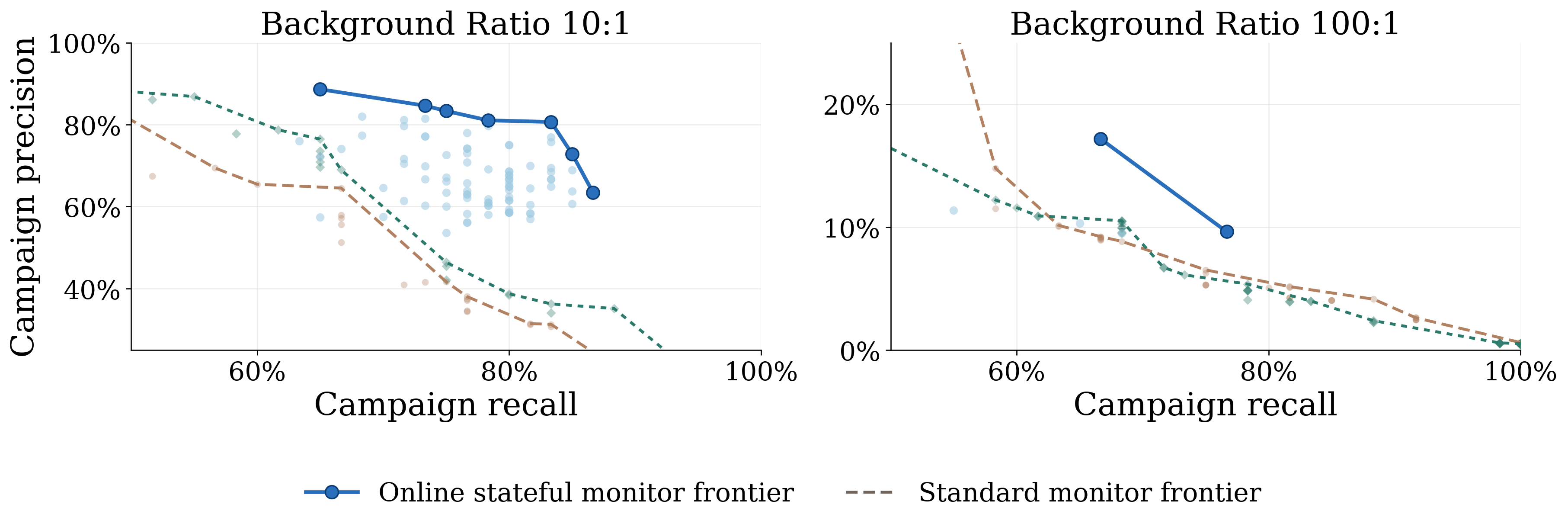
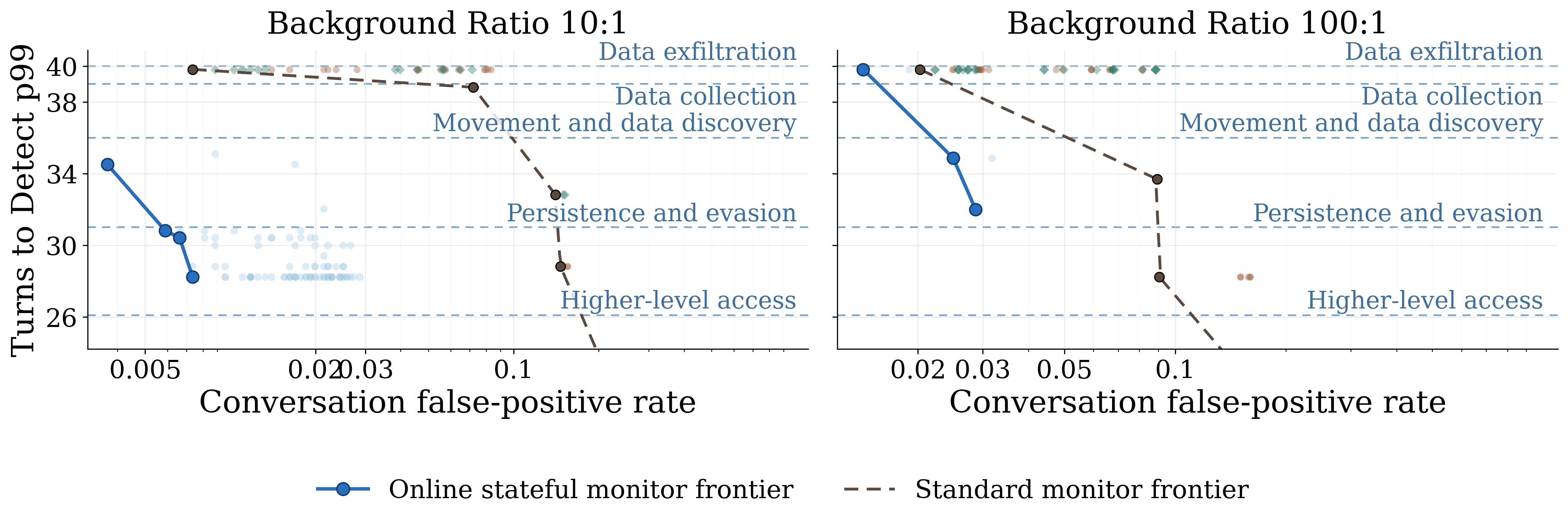
- The stateful monitor catches more, and earlier: By collecting small clues across related conversations, the new monitor caught these attacks about 30% earlier and more frequently than a standard monitor at similar false-positive rates. It often stopped attacks before they reached the most damaging stages.
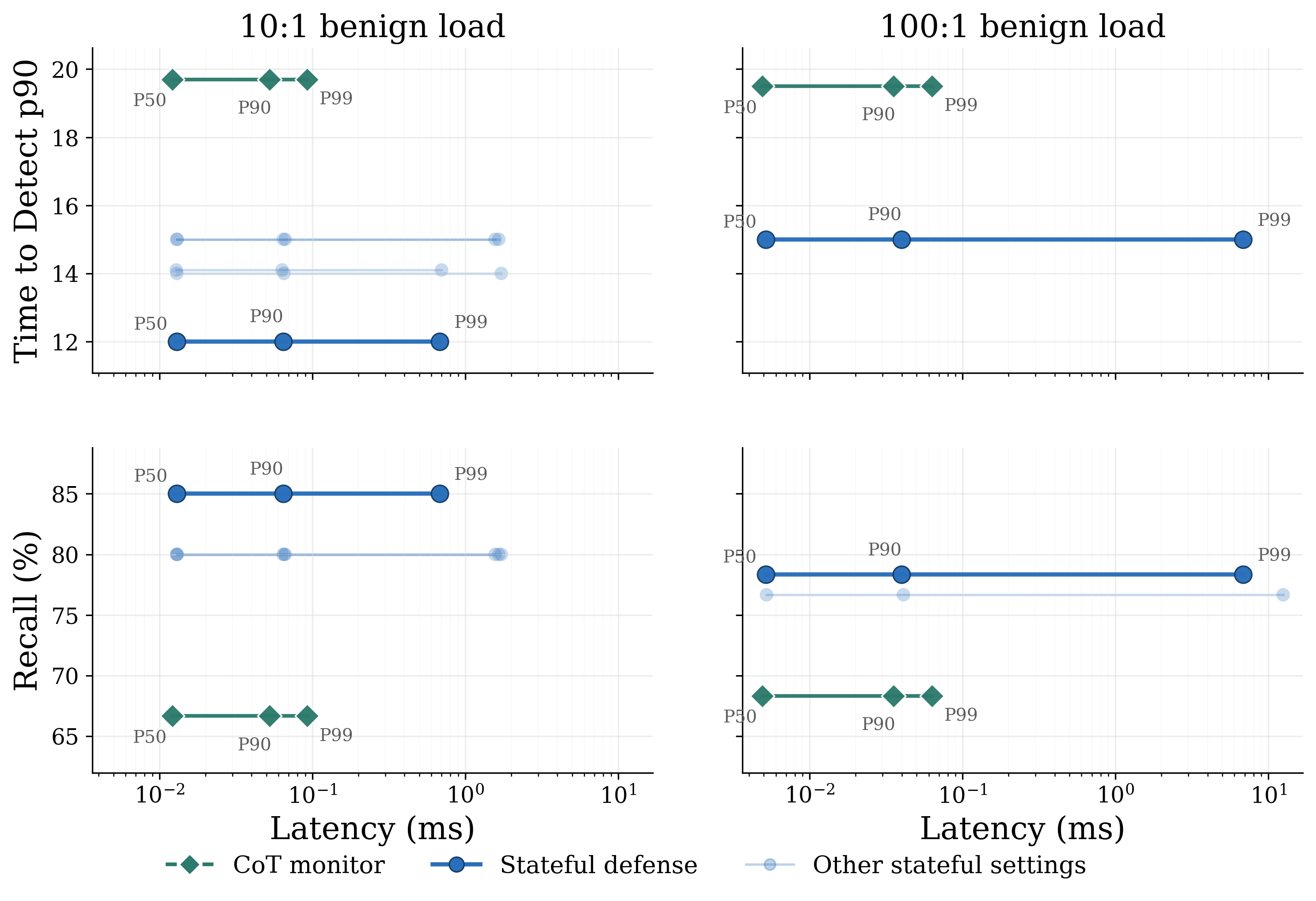
- It stays fast for almost everyone: About 99% of normal user traffic saw almost no extra delay because the system only runs the heavy cross-check when bins look suspicious.
- Works even as traffic grows (with limits): The monitor still helped when there was a lot more benign traffic, though its advantage narrowed as the “haystack” got very large.
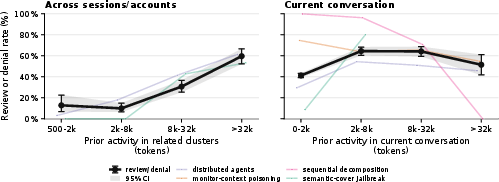
- Red teaming improved it—and revealed a bonus: Testers found two weaknesses (attackers could scatter similar tasks across slightly different bins by renaming things, and old, borderline examples could linger and cause false alarms). The authors fixed this by:
- Assigning messages to multiple related bins when appropriate.
- Deduplicating and prioritizing only the strongest evidence before escalation.
- Surprisingly, the monitor also helped catch standard jailbreaks, because attackers tend to reuse similar tricks across accounts. The system noticed these repeated patterns.
Why is this important?
Real attackers already try to hide by spreading their work across many accounts and sessions. Safety tools that only look at one chat at a time are “blind” to that strategy. A monitor with memory that can spot patterns across users closes this gap, catching misuse that would otherwise slip through.
What does this mean for the future?
- Safety systems should reason about groups, not just single conversations. Looking for repeated patterns across users makes it harder for attackers to hide.
- Real-time and low-latency design matters. Watching many streams at once can be done efficiently if you only escalate when clusters look suspicious.
- Defense will keep evolving. Attackers will try new disguises; monitors will need to keep improving (better grouping, better signals, and careful tuning).
- Broader impact: This approach could help protect AI-powered tools in companies and datacenters, reducing the risk that agents are misused for cyberattacks—without slowing down normal users.
In short, the paper shows that split-up, hidden attacks are real and effective—but a smart, memory-based monitor that connects small hints across many accounts can catch them earlier and more often, helping keep AI systems safer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains unresolved in the paper—specific gaps future work can address:
- Robustness to embedding evasion: How well does clustering hold up against adversarial paraphrasing, synonym/variable renaming, code transformations, multilingual/mixed-script prompts, or encoding (e.g., base64) explicitly optimized to minimize embedding similarity while preserving attack function?
- Adversarially robust representations: Can ensemble or adversarially trained embedding models, code-aware embeddings, or semantic normalization/preprocessing (e.g., canonicalizing identifiers) reduce cluster splitting under obfuscation?
- Poisoning and overload resilience: How resilient is the cluster-buffer evidence aggregation (sum of top-k suspiciousness) to targeted poisoning (e.g., seeding clusters with ambiguous samples), alert flooding, or efforts to inflate the number of clusters M_t to degrade performance?
- Concept drift and cluster lifecycle: What policies (TTL/decay, split/merge criteria, dedup windows) best manage cluster staleness, drift, and growth over weeks/months without degrading recall or inflating the false positive rate (FPR)?
- Scalability at internet scale: How do M_t (cluster count), memory footprint, and per-request latency evolve under millions of concurrent users and large benign-to-attack ratios well beyond 100×, especially in bursty traffic?
- Tail latency characterization: The paper claims “negligible” added latency for ~99% of traffic but does not quantify tail behavior; what are P95/P99/P99.9 latencies and their sensitivity to cross-context invocation rates and load?
- Base-rate shifts and calibration: How robust are thresholds (routing τ_route, top‑k sum thresholds, m) to sudden changes in attack prevalence? Are there online calibration/drift-detection methods that maintain performance without frequent offline retuning?
- Privacy and compliance of cross-account aggregation: How can the system aggregate evidence across users while satisfying privacy regulations (e.g., GDPR/CCPA) and minimizing reidentification risk? Can differential privacy, secure enclaves, or federated detection be applied without collapsing recall?
- Human-in-the-loop triage burden: What is the escalation volume, reviewer time, and operator load at different operating points? How should the system prioritize/merge clusters for analyst review to avoid alert fatigue?
- Policy and ground-truth ambiguity: Reliance on a policy that refuses CTF-style tasks may not reflect real deployments. How do results change with expert-annotated labels and more nuanced dual-use policies (defensive vs offensive security work)?
- Generalization beyond cybersecurity: Does stateful monitoring transfer to other misuse domains (biosecurity, fraud, financial crime, covert persuasion/disinformation)? What domain adaptation is needed for embeddings and cross-context judgments?
- Multilingual and code-heavy attacks: How does performance vary across languages, code-only interactions, binary artifacts, and multimodal inputs (images/screenshots of code or creds)? What additional embeddings/tooling are needed?
- Integration of non-text signals: Can graph/timing/device/IP/account-linkage features (common in SIEM) be fused with text embeddings to improve precision/recall and reduce dependence on semantic similarity alone?
- External orchestrator visibility: When the orchestrator sits outside the platform (or across providers), how does limited visibility into only subagent transcripts impact detection? What mechanisms enable cross-provider or federated correlation?
- Comparative baselines and ablations: How does the method compare against stronger local monitors (fine-tuned classifiers, multi-turn judges, RAG-based monitors), alternative streaming clustering (e.g., hierarchical, sketching, ANN), and different embedding models?
- Reproducibility and artifact release: Are attack scaffolds, traffic generators, and monitoring code released to enable independent replication and stress-testing at larger scales and in other domains?
- Theoretical guarantees: Are there formal bounds on detection delay (TTD), false discovery under class imbalance, or robustness to worst-case evasion under plausible attacker budgets in a streaming setting?
- Mapping detection time to harm avoided: While TTD is measured, how does earlier detection translate to concrete reductions in exploit stages or real-world impact? Can experiments quantify prevented actions/tools/exfiltration?
- Long-lived “low-and-slow” campaigns: How does the monitor perform when attacks unfold over weeks with very sparse, temporally separated subtasks? Do cluster TTL/decay policies erase needed state?
- Handling benign topic spikes: Trending benign tasks (e.g., identical homework/code patterns) may create dense clusters—how to suppress resulting false positives without missing coordinated misuse?
- Cross-account linking risks and fairness: What procedures ensure that cross-session aggregation avoids disparate impact or bias across regions/languages/user populations, especially when correlating across accounts?
- Attackers optimizing against the monitor: How effective are strategies that explicitly minimize cluster coalescence (e.g., gradient-based embedding attacks, schedule dispersion, multi-language mixing), and what countermeasures work?
- Security of the state store: How are integrity, isolation, and abuse resistance ensured for cluster buffers and metadata (e.g., protection from insider tampering or cross-tenant leakage)?
- Cost and resource accounting: What is the marginal dollar cost per million requests for embeddings, clustering, and cross-context LLM calls at different thresholds, and how do these costs trade off with recall/TTD?
- Online thresholding and independence: The cross-context decision uses the local monitor’s scores as inputs, risking correlated errors; would independent models or Bayesian fusion reduce error coupling?
- Evaluation diversity: Results rely on specific models (gpt‑oss‑120b, gpt‑5.2, gpt‑4.1‑mini), datasets (CyBench, BountyBench, curated benign traces), and English prompts; broader cross-model, cross-corpus, and non-English evaluations are needed.
- Release and measurement of red-teaming outcomes: The red-team involved six participants for two months; how general are findings across larger, external, blind red-teams, and how much does whitebox access overfit defenses?
- Streaming implementation details: Key operational choices (buffer sizes, dedup hashing strategy, cluster split/merge thresholds, evidence top‑k) lack ablation; which parameters most affect recall/TTD/FPR and how should they be tuned online?
- Defending the cross-context judge: Prompt-injection/“monitor-context poisoning” was observed; what hardening (structured inputs, tool telemetry, sandboxed summaries, verifier models) best protects the cross-context LLM from being steered?
- Sharding and hierarchy for scale: As advantage narrows with larger benign traffic, can hierarchical clustering, per-domain shards, or sketching/reservoir strategies preserve gains at internet scale without hurting recall?
- Coordination across providers: Many real attacks span multiple vendors and surfaces; how can privacy-preserving signals be exchanged to enable cross-platform campaign detection without sharing raw content?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings and methods to improve safety monitoring against distributed misuse of LLM agents.
- Stateful safety proxy for LLM platforms and SaaS (software, cloud, cybersecurity)
- Deploy an “online stateful monitor” in front of agent runtimes to aggregate weak signals across accounts and sessions using stream clustering over embeddings, escalating only suspicious clusters to a cross-context LLM judge. Integrate with API gateways (e.g., Envoy/Nginx), streaming backbones (Kafka/Kinesis/PubSub), ANN/vector stores, and existing standard monitors.
- Tools/workflows: microservice for clustering and buffers; top-k evidence assembler; TTD (time-to-detect) dashboards; auto-escalation runbooks; per-tenant throttling/kill-switches.
- Dependencies/assumptions: access to multi-tenant metadata and logs; reliable embeddings; calibrated thresholds and deduplication; acceptable data retention under privacy rules; monitor latency budgets; performance may degrade as benign background traffic becomes extremely large.
- SOC/XDR enrichment for agent telemetry (cybersecurity, enterprise IT)
- Pipe agent prompts, tool calls, and outputs into SIEM/XDR; use the stateful clusters to open incidents when cross-account evidence accumulates. Prioritize based on sum of suspiciousness across a cluster and stage-in-attack heuristics.
- Tools/workflows: Splunk/Elastic or Chronicle enrichment apps; “cluster-centric cases” in ticketing; TTD90 and campaign recall as new SOC KPIs.
- Dependencies/assumptions: stable identity resolution or heuristics for account linking; labeled holdout data to tune thresholds; agreement on acceptable false positive rates for production.
- Enterprise AI governance and insider-risk monitoring (governance, compliance)
- Monitor agent use across departments for policy violations (e.g., prohibited exploit-like tasks) that, in isolation, look benign. Generate auditable cross-context evidence packets for compliance review.
- Tools/workflows: SSO/RBAC integration; cluster-level risk scoring; evidence packs attached to audit trails; policy-as-code expressing escalation thresholds.
- Dependencies/assumptions: clearly scoped lawful bases for processing; privacy-by-design (short buffers, hashed/deduped content); worker council/legal review.
- Abuse detection for account farms and automation (platform integrity, fraud)
- Detect distributed, low-and-slow misuse (spam, scraping, coordinated inauthentic behavior) by clustering semantically related prompts/actions rather than per-account metrics. Rate-limit or sandbox at the cluster level.
- Tools/workflows: WAF policies conditioned on cluster risk; anomaly budgets per cluster; integration with bot-detection signals.
- Dependencies/assumptions: embeddings resilient to paraphrase/renaming; low-latency routing; acceptable collateral impact on legitimate multi-account operations.
- Safer coding assistants in orgs (software engineering, DevSecOps)
- For code assistants and CLI/web agents, use stateful monitoring to block coordinated attempts to introduce vulnerabilities or exfiltrate secrets across repos/projects.
- Tools/workflows: repo-aware embeddings; cross-repo evidence assembly; developer notification and just-in-time education when a cluster is refused.
- Dependencies/assumptions: access to code/context embeddings; robust disambiguation between red-team/testing vs. true misuse; clear developer opt-in.
- Education platforms: detection of distributed collusion (education)
- Identify rings that distribute assignment subtasks across accounts to avoid single-session flags. Escalate only when cross-context evidence is strong.
- Tools/workflows: course/section-aware clustering; instructor alerts with evidence bundles.
- Dependencies/assumptions: stringent privacy safeguards; governance for false positives; clear acceptable-use policies.
- Red-teaming and evaluation harnesses (academia, model providers)
- Reproduce the paper’s distributed attack scaffolds as benchmarks; add stateful monitors as a baseline; measure TTD, recall/FPR under controllable benign backgrounds.
- Tools/workflows: replay harnesses; synthetic traffic generators; operating-point sweeps; open red-team portals that expose cluster assignments and scores for testing.
- Dependencies/assumptions: curated benchmarks; access to representative benign traffic; policy prompts reflecting organizational risk tolerance.
- Threat intelligence sharing via “cluster fingerprints” (policy, security ecosystem)
- Share compact cluster signatures (e.g., hashed exemplars, decoy prompts, behavioral descriptors) across organizations to pre-warm monitors against ongoing campaigns.
- Tools/workflows: STIX/TAXII-like schemas extended to LLM campaign clusters; indicator-of-behavior feeds; automated enrichment in SOC tooling.
- Dependencies/assumptions: legal frameworks for sharing; privacy-preserving hashing/summarization; deconfliction across organizations.
- Productization: “Stateful AI firewall” (software product)
- Package the online clustering + cross-context judge + standard monitor as a drop-in proxy for agentic systems with pluggable embeddings and LLMs. Offer hosted and on-prem modes.
- Tools/workflows: Terraform/Kubernetes deployment recipes; latency SLO monitors; cost guardrails for escalations.
- Dependencies/assumptions: maintain vendor-agnostic connectors; continuous re-tuning as usage patterns shift; clear incident response playbooks.
- Daily-life/SMB managed safety service (MSP channel)
- A managed service that aggregates signals across multiple small-business tenants (opt-in) to detect franchise-wide or supply-chain–wide coordinated misuse against their AI tools.
- Tools/workflows: lightweight agent telemetry connectors; monthly “stateful safety” reports; alerting with evidence snapshots.
- Dependencies/assumptions: consent and data processing agreements; careful multi-tenant isolation; explainability for non-expert admins.
Long-Term Applications
The following use cases require further research, scaling, or maturation of standards to be feasible and robust.
- Federated and privacy-preserving cross-org monitoring (policy, privacy tech, cybersecurity)
- Correlate distributed attacks across vendors without raw data sharing using secure aggregation, sketches, or privacy-preserving embeddings; compute cluster-risk scores with DP guarantees or MPC.
- Potential tools/products: federated “campaign radar”; standardized privacy budgets for telemetry.
- Dependencies/assumptions: mature cryptographic protocols at scale; standard schemas for cross-context evidence; regulatory clarity.
- Robust, adversary-resilient embeddings and stream clustering (research, software)
- Develop embeddings and online clustering resistant to lexical obfuscations (file renames, paraphrase) and adaptive concept drift. Learn routing thresholds online with bandit/ML approaches.
- Potential tools: adversarially trained embedding services; learned routers with verifiable worst-case latency.
- Dependencies/assumptions: high-quality red-team corpora; offline/online evaluation standards; compute budgets.
- Cross-modal stateful monitoring (robotics, cyber-physical, web automation)
- Extend clustering across text, code, web actions, tool I/O, shell commands, and sensor logs to catch distributed misuse in automation stacks and robots.
- Potential tools: multimodal embeddings; unified trace schemas; task-graph–aware clustering.
- Dependencies/assumptions: instrumentation coverage; synchronization across modalities; safety-case engineering for CPS.
- Agent policy controllers and “budgeted risk” schedulers (agent orchestration)
- Use cluster-level risk to dynamically cap tool access, credentials, or execution budgets across accounts; auto-mitigate by forcing higher-assurance reviews or inserting canary tasks.
- Potential tools: risk-aware agent schedulers; policy compilers for cluster-based constraints.
- Dependencies/assumptions: reliable risk calibration; minimal disruption to benign workflows; formal guarantees desirable.
- Standards and regulation for group-level AI safety (policy, governance)
- Codify best practices for stateful monitoring (e.g., target TTD90, campaign recall, acceptable FPR bands), audit requirements, and red-teaming obligations focused on cross-context harms.
- Potential tools: certification programs; compliance test suites for “distributed misuse readiness.”
- Dependencies/assumptions: multi-stakeholder consensus; alignment with data protection laws; proportionality to organization size.
- Open distributed-misuse benchmarks and simulators (academia, evaluation)
- Community-maintained corpora and traffic simulators with tunable benign-to-harmful ratios and realistic agent traces to test stateful defenses and adaptive attackers.
- Potential tools: replay frameworks; labeled attack-stage annotations; public leaderboards tracking TTD and recall-FPR frontiers.
- Dependencies/assumptions: safe release policies; ongoing curation; governance for dual-use risks.
- Jailbreak family tracking and rapid-variant containment (model providers, platform integrity)
- Treat jailbreaks as “campaign families” and use state to learn evolving variants across users; automatically generate counter-prompts and targeted mitigations.
- Potential tools: jailbreak lineage graphs; variant detectors; semi-automated patch pipelines.
- Dependencies/assumptions: low false positives on benign prompt styles; human-in-the-loop review; continuous evaluation.
- Integration into next-gen SIEM/XDR as first-class “LLM telemetry” (security analytics)
- Elevate stateful LLM monitoring to a core signal in enterprise defense-in-depth, correlated with identity, network, and endpoint data for end-to-end campaign views.
- Potential tools: cross-domain correlation rules; unified incident timelines; MITRE-style attack-stage mapping for agent misuse.
- Dependencies/assumptions: vendor ecosystem alignment; common schemas; training for analysts.
- On-device/edge stateful monitoring for privacy-critical settings (healthcare, finance, gov)
- Run clustering and evidence assembly locally with ephemeral buffers, escalating only compact summaries to cloud judges, or using local small judges.
- Potential tools: WASM- or mobile-optimized ANN; policy-controlled data lifetimes.
- Dependencies/assumptions: resource constraints; acceptable accuracy/latency trade-offs; formal privacy assurances.
- Market intelligence on “attack herders” and supply chains (threat intel, finance)
- Use cross-context clustering to attribute campaigns to orchestrators coordinating many accounts, informing risk ratings, takedowns, and financial crime monitoring.
- Potential tools: orchestrator fingerprinting; linkage analysis; cooperative takedown playbooks.
- Dependencies/assumptions: careful attribution standards; legal pathways for action; anti-evasion research.
Notes on feasibility across applications:
- Performance depends on the benign-to-harmful traffic ratio, with advantages narrowing as benign background grows extremely large; careful thresholding and resource-aware escalation are key.
- Latency targets are met for ~99% of traffic by keeping cross-context LLM escalations rare; cost controls and p99 tail management are necessary.
- Privacy, legal, and ethical safeguards (minimization, retention limits, hashing/dedup, transparency) are essential where cross-account aggregation is used.
- Adversaries adapt; periodic re-tuning, red-teaming, and robust embedding research are ongoing needs.
Glossary
- agent orchestrator: A coordinating component that receives the overall task and delegates subtasks to other agents. "using an agent orchestrator which receives the full task objective"
- ARTEMIS: A specific multi-agent scaffold used to organize and execute tasks among multiple agents. "We build our distributed agent attack from a multi-agent scaffold, ARTEMIS"
- centroid: The representative point (e.g., mean embedding) of a cluster used to route and aggregate similar items. "compare it to the centroids of our clusters"
- cross-context monitor: A reviewer that reasons over multiple related conversations or sessions to assess coordinated misuse. "a cross-context monitor is called in two cases"
- CTF benchmarks: Capture-the-Flag style security challenge datasets used to evaluate exploit capabilities. "CTF benchmarks"
- Cybench: A benchmark suite of cybersecurity tasks used to evaluate agents’ exploit or defense capabilities. "a difficult Cybench subset"
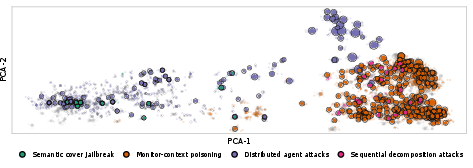
- distributed agent attack: A strategy that decomposes a harmful objective across multiple accounts or sessions so each local piece looks benign. "In distributed agent attacks, a single harmful objective is decomposed into subtasks."
- embedding: A vector representation of text or context used to measure semantic similarity for retrieval or clustering. "We compute an embedding (in most experiments, with \citep{voyage2026voyage4}) of the current agent context"
- embedding space: The geometric space where embeddings reside, enabling similarity-based grouping of related content. "identified in a structured embedding space."
- false-positive rate (FPR): The fraction of benign items incorrectly flagged as malicious by a detector. "At modest false-positive rates, the monitor essentially always catches sequential decomposition attacks"
- jailbreaks: Prompts or strategies that cause a model to bypass safety policies. "catches standard jailbreaks"
- monitor-context poisoning: An attack that manipulates or injects misleading information into the monitor’s inputs or metadata to evade detection. "monitor-context poisoning (faking classifier outputs and approvals to prompt inject the cross-context monitor)"
- multi-agent scaffold: An architectural pattern that coordinates multiple agents, each handling part of a larger task. "We build our distributed agent attack from a multi-agent scaffold, ARTEMIS"
- online stateful monitor: A real-time defense that accumulates and uses historical evidence across users and sessions to detect distributed misuse. "we develop an online stateful monitor"
- operating curve: A curve showing detector performance across thresholds (e.g., tradeoffs between recall and false positives). "the operating curves over the reported harmfulness scores."
- operating point: A specific threshold choice on an operating curve that yields a particular performance tradeoff. "the operating points from our stateful monitor Pareto dominate"
- Pareto dominates: A performance comparison where one method is strictly better or equal on all considered metrics and better on at least one. "our monitor Pareto dominates standard monitors"
- P99 tail: The slowest 1% (99th percentile) of latency or performance distribution, often where outliers and worst-case delays appear. "except for the P99 tail."
- recall: The fraction of true attacks correctly detected by the monitor. "the stateful moniter reaches 81.1--87.2\% campaign recall"
- redteaming: An adversarial testing process where attackers probe a system to find weaknesses. "We redteamed the stateful monitor to investigate two questions:"
- safety monitor: A policy or model that evaluates and filters content for harmfulness within a single context. "Because safety monitors score only one agent context at a time"
- sequential decomposition attack: An attack that splits a harmful objective into sequential steps within a single conversation/context. "sequential decomposition attacks are on average caught while just obtaining access"
- semantic-cover jailbreaks: Jailbreak attempts disguised as benign tasks like code review or debugging to evade detection. "semantic-cover jailbreaks, i.e. standard jailbreaking"
- standard monitor: A language-model-based judge that assesses each interaction in isolation without aggregating cross-session evidence. "A standard monitor is a LLM judge"
- stateful monitoring: Monitoring that retains and leverages historical, cross-session evidence when making current decisions. "Overall, stateful monitoring helps to catch but does not solve distributed cyber misuse."
- stream clustering: Clustering that updates incrementally on incoming data, enabling real-time grouping without reprocessing all history. "we formulate distributed misuse detection as stream clustering"
- subagent: A delegated agent that receives a limited subtask description to perform part of a larger objective. "The subagents receive a narrow task description"
- suspiciousness score: A numeric score expressing how likely a request or action is harmful, used for routing and escalation. "provide suspiciousness scores for each prompt or agent action."
- Time-to-detect (TTD): The number of attacker actions that occur before the defense flags the attack. "Time-to-detect (TTD) measures the number of attacker turns"
- top‑k retrieval: Selecting the k most similar items (e.g., prior transcripts) based on a similarity measure for downstream reasoning. "Even a top- retrieval requires comparing the current request against prior transcripts"
- verifier tool: A check that periodically assesses whether the overall cyber task has been successfully completed. "A verifier tool periodically checks if the cyber task is solved."
Collections
Sign up for free to add this paper to one or more collections.