- The paper introduces a novel virtual pipeline that generates physically executable humanoid loco-manipulation data from 3D assets and video priors.
- It integrates 4D human-object interaction recovery with metric grounding and controller adaptation to ensure robust sim-to-real transfer.
- Experimental results demonstrate high tracking success and superior policy generalization, reducing the need for costly physical demonstrations.
GRAIL: A Fully Digital Pipeline for Scalable Humanoid Loco-Manipulation Data Generation and Deployment
Overview and Motivation
The increasing functional and morphological complexity of humanoid robots necessitates scalable strategies for generating diverse, robot-compatible loco-manipulation demonstrations. Traditional pipelines leveraging teleoperation or motion capture face severe bottlenecks: each new task or scene requires expensive physical re-setup, hardware, and expert actors, while video-based reconstruction approaches remain mired by scale/morphology ambiguities and lack of control over crucial factors like metric scale and robot mapping. "GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors" (2606.05160) proposes a paradigm shift—building a purely virtual pipeline that produces physically executable, controller-ready trajectories aligned, by construction, for target robots, using only 3D assets and the generative priors of advanced video foundation models (VFMs).

Figure 1: GRAIL enables fully digital generation of physiologically plausible humanoid loco-manipulation data from 3D assets and video priors, supporting sim-to-real policy learning and real-world deployment on a Unitree G1.
Asset-Conditioned Human-Object Interaction Synthesis
The central technical insight of GRAIL is leveraging known-metric, robot-conditioned 3D assets and scene configuration as a privileged context for VFM-based video generation and subsequent 4D human-object interaction (HOI) recovery. By anchoring the 3D geometry, camera intrinsics/extrinsics, environmental structure, and robot-proportioned character before video synthesis, GRAIL avoids the ill-posed reconstruction pipeline of unconstrained internet video.
GRAIL operates in discrete stages:
- 3D Scene Assembly and Prior Generation: A target 3D object is placed within a candidate environment (e.g., tabletop, floor-level) as decided by a VLM-driven affordance prompt. A humanoid mesh, proportioned to the deployment robot, is placed in a contextually relevant rest pose. The privileged configuration (object/scene/camera/character) is passed to a VFM (e.g., Kling) using a static-camera setting, ensuring subsequent video frames retain metric consistency.
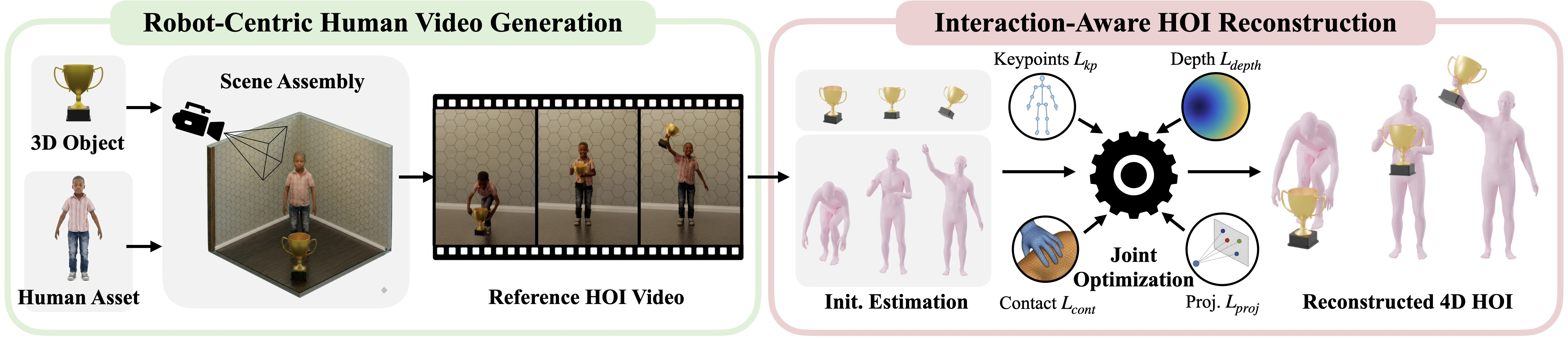
Figure 2: The asset-conditioned, metric-grounded 3D configuration enables robust 4D reconstruction by fusing generative video with privileged geometry and camera models.
- HOI Video Synthesis and Reconstruction: Frame-wise pose estimation using GENMO extracts the SMPL-X skeleton with fixed morphology, hand parameters are refined via WiLoR/MANO, and object pose is tracked using a fine-tuned FoundationPose adapted for RGB input. Interaction-aware joint optimization leverages metric depth (MoGe-2), projective and contact-based losses, and known camera parameters for physically plausible, temporally coherent, and interaction-consistent 4D trajectory recovery. Residual trajectory optimization, rather than direct pose fitting, allows fine spatial and temporal adjustment while preserving high-level affordance flow.
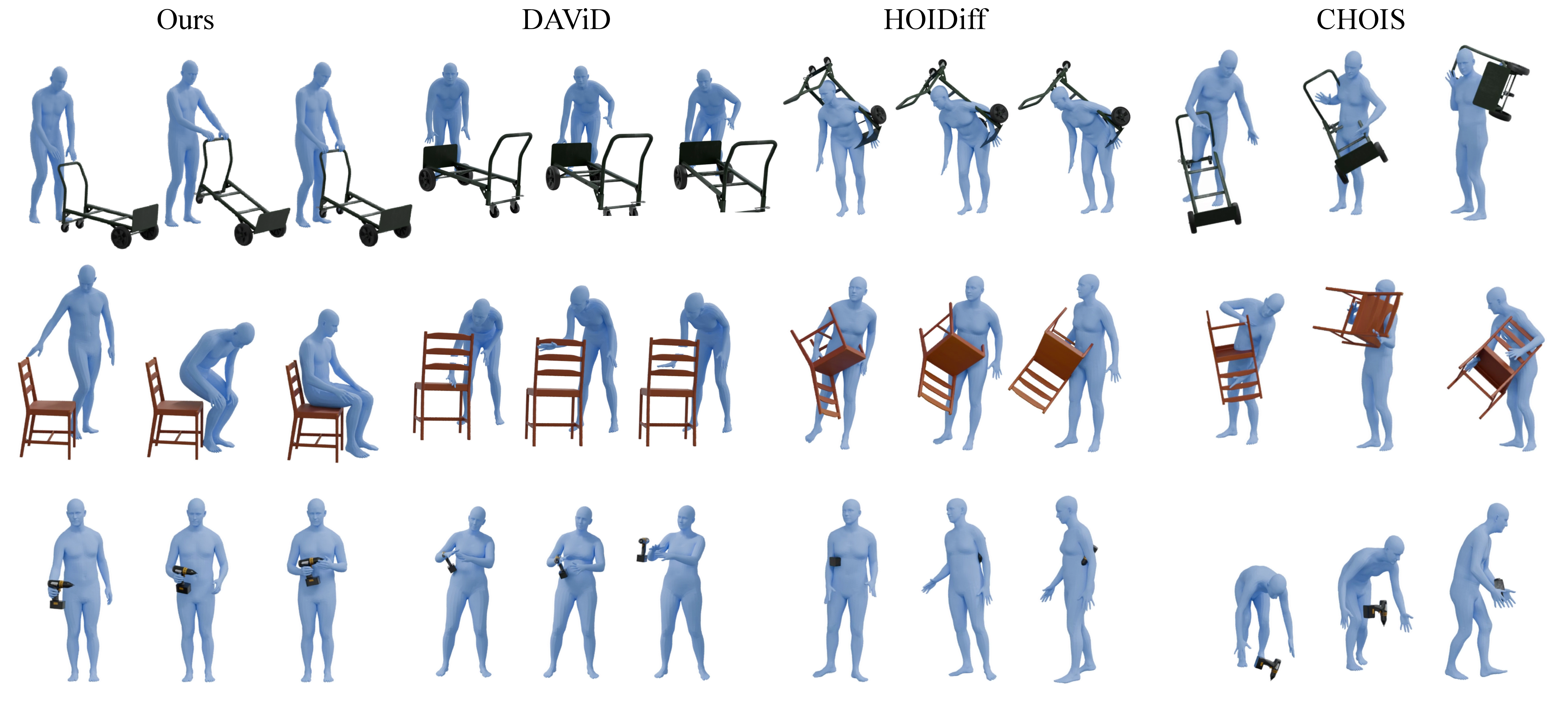
Figure 4: Qualitative comparison shows GRAIL produces articulated, natural contact-rich sequences, in contrast to baseline methods that yield stiff, flat, or implausible contacts.
Whole-Body Policy Tracking and Robot-Action Generation
The reconstructed, metric-grounded 4D HOI trajectories are subjected to GMR-based retargeting, ensuring minimal morphology mismatch for the target humanoid, here the Unitree G1. GRAIL introduces a bifurcated tracking paradigm:
This design yields task-general, amortized policies instead of trajectory-specific controllers, massively reducing policy training cost per motion and supporting efficient extension to new motion/task families.
Sim-to-Real Transfer with Visual Policies
GRAIL closes the sim-to-real gap by distilling these tracking policies into egocentric visual policies, trained with domain randomization using only GRAIL-generated data. The resulting RGB-based policies are deployed on the Unitree G1 (using only a head-mounted RGB camera and torque control), achieving 84% real-world pick-up and 90% stair-climbing success across both seen and compositional novel-object scenarios, with no real robot demonstration pretraining.

Figure 6: Diverse simulated loco-manipulation sequences (e.g., pick-up, sit, whole-body manipulation, traversal), generated entirely virtually.

Figure 7: Policies trained solely in simulation successfully deploy for multi-object pick-up and stair climbing without domain overfitting.
Experimental Findings
Comprehensive evaluations establish several strong claims:
- GRAIL's generated HOI sequences are significantly more executable (88.9% tracking success) versus state-of-the-art learning-based and video-generation baselines, both in geometry metrics (lowest contact distance/penetration) and physics-execution (lowest body/object deviation).
- Qualitative/subjective assessments confirm GRAIL sequences are substantially preferred for both affordance accuracy and physical plausibility.
- Task-general tracking policies outperform HDMI and ResMimic by a wide performance margin, supporting more robust, generalizable manipulation.
- Sim-to-real deployment validates closed-loop controller + visual stack, matching or exceeding contemporary research using only digital assets and VFM priors.
Limitations and Discussion
The approach is bounded by the availability and quality of 3D assets and the robustness of the VFM to follow desired interaction prompts. Scene/appearance drift, fast motion, or occlusion—especially under high scene diversity—can degrade reconstruction yields, necessitating filtering and outlier removal. While GRAIL amortizes controller adaptation per task-family, large distributional shifts or new motor primitives will require additional fine-tuning.
Nonetheless, this work asserts a scalable and fully virtual alternative to physical demonstration pipelines for whole-body humanoid skill acquisition, enabling data-efficient, compositional, and transferable skill synthesis at scale.

Figure 3: Candidate scene templates select between indoor layout and tabletop context, supporting affordance-appropriate interaction generation.
Theoretical and Practical Implications
By front-loading scene definition and robot-conditioned scene synthesis, GRAIL decouples ambiguous inverse problems nested in standard video-based HOI recovery. Explicit metric alignment, known camera, and morphology control eliminate the bulk of scale, depth, geometry, and mapping errors, guaranteeing that generated policies are syntactically trackable and numerically viable for deployment. This foundational technique generalizes: any high-DOF robot with a riggable mesh and enough asset priors is amenable.
Practically, this pipeline (i) obviates the need for large-scale physical demonstration or labor-intensive teleoperation, (ii) democratizes the generation of multi-domain skill datasets, and (iii) supports rapid iteration and transfer for both manipulation and navigation controllers. Future directions might include extension to high-fidelity hand-object dynamics, social human interaction, embodied multi-agent scenarios, or in-the-wild sim-to-real adaptation across robot morphologies and environments. Integration with LLMs and multimodal affordance engines can further expand behavior coverage.
Conclusion
GRAIL establishes a high-fidelity, asset-conditioned, sim-to-real humanoid loco-manipulation data generation and policy pipeline requiring no physical interaction or motion capture until deployment. By leveraging video generative priors inside a fully specified 3D and robot-centric asset pipeline, GRAIL defines a pathway to scalable, diverse, and physically executable dataset creation for high-DOF robots. The empirical results demonstrate quantitative and qualitative superiority over prior 4D HOI pipelines, robust policy generalization, and effective sim-to-real transfer for complex manipulation and traversal, pointing toward a future where most of the data bottleneck in humanoid learning is addressed virtually.
Reference:
GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors (2606.05160)
