C-DEQ: Consistency Deep Equilibrium Model
This lightning talk introduces the Consistency Deep Equilibrium Model (C-DEQ), an innovative implicit neural network framework that dramatically accelerates inference while maintaining the constant-memory advantages of traditional Deep Equilibrium Models. By reframing fixed-point iteration as evolution along a canonical ODE trajectory and applying consistency-driven distillation, C-DEQ achieves up to 20× faster convergence with 1-8 function evaluations instead of tens, delivering substantial gains in speed, efficiency, and accuracy across language modeling, computer vision, and graph neural network tasks.Script
Imagine training a neural network that can reach its answer in one step instead of dozens, while using the same memory regardless of depth. The Consistency Deep Equilibrium Model makes this possible by reimagining how implicit models find solutions.
Let's start with the foundation that makes this breakthrough possible.
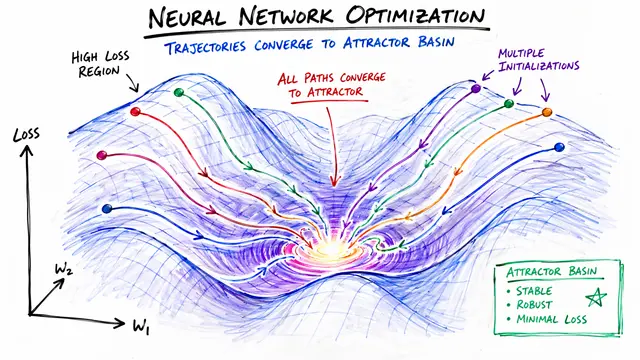
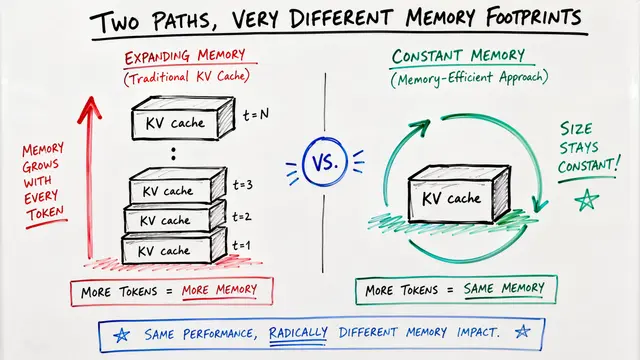
Building on that foundation, Deep Equilibrium Models represent hidden states as fixed points of a neural function, solved through iterative methods. While they achieve constant memory usage regardless of depth, the catch is they need many forward iterations to reach equilibrium, creating significant latency.
Here's the key insight that enables C-DEQ. We can view the iterative process as following an ordinary differential equation trajectory, where each input traces a unique path to its equilibrium. This trajectory becomes our teacher signal for distillation.
Now we'll see how consistency principles accelerate this process.
The distillation approach uses three complementary objectives. Global consistency ensures the student can jump directly to equilibrium from any point, while local consistency stabilizes consecutive predictions, and task loss maintains accuracy on the actual problem.
Connecting these objectives to implementation, the student architecture blends the current state with learned corrections using time-dependent weights. Training alternates between caching full teacher trajectories and updating the student on randomly sampled trajectory points with exponential moving average stabilization.
This brings us to the practical payoff. At inference, you choose your computational budget. Need maximum speed? Use one step. Want higher accuracy? Chain a few steps together. The framework gives you explicit control over the speed-accuracy tradeoff.
The empirical evidence demonstrates dramatic improvements across multiple domains.
The results speak clearly across language modeling, computer vision, and graph tasks. C-DEQ delivers 2 to 20 times better accuracy than baseline methods at the same computational budget, with particularly dramatic improvements in the ultra-low function evaluation regime.
Comparing directly to conventional approaches, C-DEQ achieves 20 times faster convergence while preserving the constant memory advantage that makes equilibrium models attractive. The memory overhead is negligible, and the approach works across diverse architectures without modification.
C-DEQ fundamentally changes the inference calculus for implicit models, making powerful equilibrium architectures practical in latency-constrained environments. To explore the technical details and implementation, visit EmergentMind.com.