Learning Without Forgetting: The Self-Replay Solution
This presentation explores a fundamental challenge in deploying large language models: catastrophic forgetting during fine-tuning. The authors demonstrate that models can effectively preserve prior knowledge by regularizing on self-generated replay data, effectively eliminating the traditional stability-plasticity tradeoff when sufficient model capacity is available. Through systematic experiments on both base and instruction-tuned models, the work reveals that forgetting is not inevitable but controllable through three key factors: model capacity, optimization strategy, and replay on the model's own prior distribution.Script
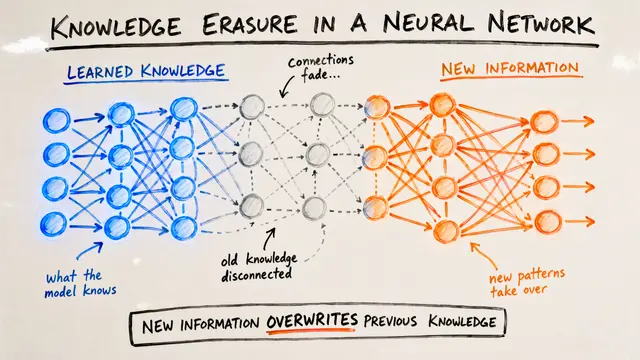
When you fine-tune a language model on new tasks, it typically forgets what it learned during pretraining. This catastrophic forgetting costs billions in retraining and limits how we can adapt models in production.
The researchers show that models can sample from their own pretraining distribution and use these self-generated examples as replay data. By adding a KL regularization loss between current and prior model predictions on this replay data, forgetting drops dramatically while downstream performance remains strong.
But replay alone isn't enough if your model is too small. The experiments reveal that model capacity imposes a hard lower bound on forgetting. When models are overtrained relative to their parameter count, they face an unavoidable tradeoff between old and new knowledge, even with strong regularization.
Learning rates during both pretraining and fine-tuning also matter. High pretraining learning rates push models toward flatter minima that resist forgetting later. During adaptation, replay regularization breaks the traditional tradeoff by enabling aggressive learning rates for fast convergence without catastrophic forgetting, making continual learning computationally efficient.
This approach extends beyond base models. Even for instruction-tuned models where pretraining data is unavailable, the authors demonstrate that simply sampling from a beginning-of-sequence token generates data close enough to the pretraining distribution. For challenging domain shifts like Verilog code generation, KL regularization on self-generated replay nearly eliminates forgetting.
Forgetting in language models isn't inevitable. It's controllable through the interplay of three factors: sufficient capacity, self-generated replay, and careful optimization. This framework enables production-scale adaptation without massive replay buffers or access to original pretraining data. To explore more research like this and create your own video presentations, visit EmergentMind.com.