Unlocking Multimodal Power with Frozen Encoders
This presentation explores a novel framework for building high-performance vision-language models by aligning pre-trained frozen encoders. Instead of retraining massive backbones from scratch, the researchers demonstrate how choosing compatible encoders via Representational Similarity and training lightweight projectors can match CLIP performance with significantly less data and compute.Script
What if you could build a world-class multimodal AI by simply plugging together existing vision and language models like modular building blocks? The researchers behind this paper explore how to harness frozen unimodal encoders for flexible and efficient multimodal alignment.
While existing models like CLIP are powerful, they rely on massive datasets and enormous compute power that most cannot afford. Meanwhile, specialized encoders like DINOv2 outperform CLIP backbones on vision tasks but remain siloed in their own modalities.
Building on this observation, the researchers propose a 3-part framework that selects compatible encoder pairs, curates specialized datasets, and trains only tiny projector layers to bridge the gap.
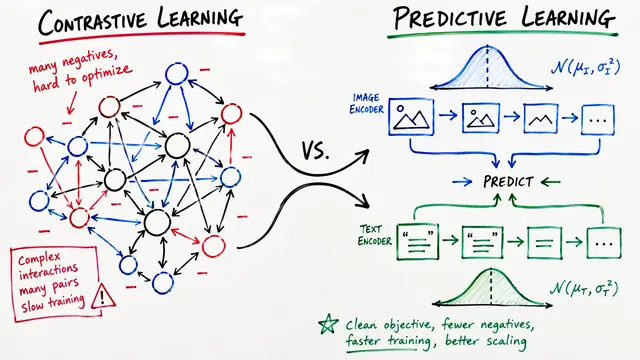
Connecting two models works best when they already perceive the world in a similar way.
By using Centered Kernel Alignment, the authors found they could predict alignment success before training. They discovered that higher CKA scores directly correlate with lower loss, making it much easier to select the right vision and text partners.
Because they are only training small projectors, data quality becomes more important than quantity. By focusing on concept coverage in a 20-million-pair dataset, they only need to update 1% of the total parameters to achieve alignment.
Despite the smaller training footprint, their DINOv2 and Roberta combination reached 76.3% on ImageNet zero-shot. They also found the model handles long text better than CLIP, which is often limited to just 77 tokens.
The efficiency metrics are truly striking. The researchers achieved these results using 20 times less data and 65 times less compute than traditional baselines.
While this approach is highly efficient, its success relies on finding compatible encoders and high-quality captions. Future work might extend this modular strategy to modalities beyond just text and images.
By treating pre-trained models as modular units, we can build efficient AI that matches current standards with a fraction of the cost. To explore more research summaries like this, visit EmergentMind.com.