Generator-Critic Framework: Learning Through Competition
The generator-critic framework is a powerful architectural paradigm where two interacting modules—a generator that creates outputs and a critic that evaluates them—jointly drive learning through adversarial feedback, iterative refinement, or reward-guided optimization. This framework unifies methodologies across reinforcement learning, generative modeling, vision-language reasoning, and code synthesis, delivering substantial performance gains by leveraging competitive or cooperative feedback loops between generation and evaluation.Script
Two neural networks locked in a productive competition: one creates, the other evaluates, and together they achieve what neither could alone. The generator-critic framework transforms adversarial feedback into a powerful learning signal that now drives everything from image synthesis to mathematical theorem proving.
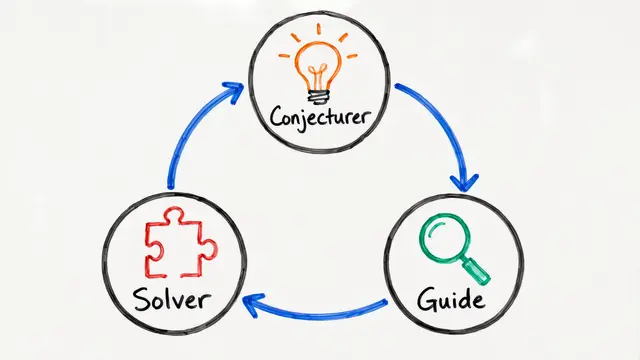
At its core, this framework coordinates two specialized modules through competitive or cooperative dynamics. The generator proposes solutions—images, actions, code, or reasoning chains—while the critic scores them, rejects poor candidates, or provides gradient signals that sharpen future proposals. This bidirectional flow creates a learning loop far more powerful than supervised training alone.
How do we formalize this interplay mathematically?
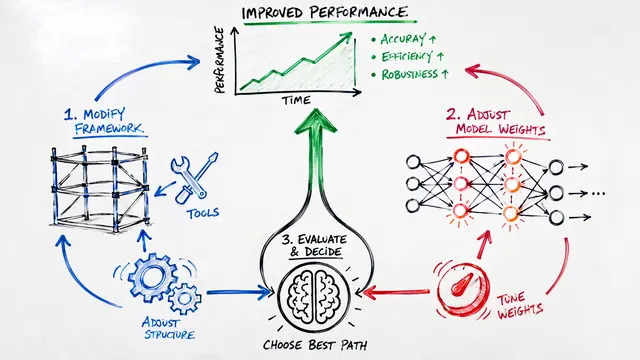
Generator-critic objectives take two dominant forms. In adversarial settings like GANs, the generator minimizes while the discriminator maximizes a minimax loss, creating a saddle-point game often stabilized by Wasserstein metrics or gradient penalties. In reinforcement learning, the actor's policy gradient is scaled by the critic's value estimate, enabling sample-efficient learning through bootstrapped returns and clipped objectives.
Training alternates between critic and generator updates, but the interaction patterns vary widely. GANs and actor-critic methods use staged gradient steps with stabilization tricks. In vision-language or code models, the critic provides textual critiques or scores entire candidate pools, guiding the generator through iterative revision or tournament-style selection—no gradient required, just smarter sampling.
The performance gains are dramatic and measurable. On visual question answering, critic-guided selection delivers double-digit accuracy improvements. In formal mathematics, critic scoring raises autoformalization success from barely one-third to nearly nine in ten, rivaling closed-source systems. For code synthesis, hybrid RL with critique loops outperforms pure reinforcement learning while slashing the computational budget for verification.
Generator-critic systems prove that learning through structured competition—whether adversarial, cooperative, or iterative—unlocks capabilities no single model can achieve alone. To explore this framework further and create your own deep-dive presentations, visit EmergentMind.com.