Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
This presentation explores Scal3R, a breakthrough neural architecture for reconstructing kilometer-scale 3D scenes from long RGB video sequences. By introducing adaptive memory sub-networks updated through self-supervised test-time training, Scal3R overcomes the scalability bottlenecks of conventional feed-forward models. The talk examines how global context synchronization enables robust trajectory estimation and geometric accuracy across thousands of frames, achieving state-of-the-art performance on multiple benchmarks while maintaining computational efficiency.Script
Reconstructing a kilometer-scale city from a single video stream sounds ambitious, but conventional methods fail when sequences stretch beyond a few hundred frames. The authors of Scal3R asked: what if the neural network could build and update its own memory of the scene as it processes thousands of images?
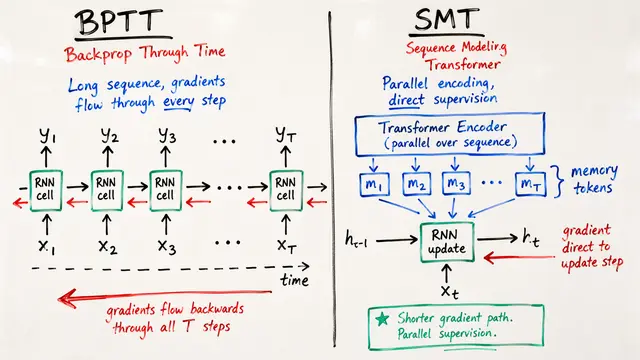
Existing feed-forward reconstruction models hit a hard ceiling. VGGT and its variants process images independently, forgetting earlier context and accumulating errors. When sequences grow to thousands of frames, quadratic attention mechanisms exhaust GPU memory, and trajectories drift catastrophically.
Scal3R introduces a fundamentally different strategy: neural memory that learns during inference.
The authors partition video into overlapping chunks, each processed on a separate GPU. Adaptive Memory Units—compact multilayer perceptrons—sit after global attention layers. During inference, these units are rapidly optimized via self-supervised losses, encoding contextual information. Crucially, gradients from all chunks are summed and synchronized across GPUs, ensuring every part of the sequence benefits from global awareness.
On KITTI Odometry, Scal3R delivers superior absolute trajectory error and avoids the tracking failures that plague VGGT-Long and classical SLAM methods. For 3D reconstruction, it achieves the lowest Chamfer distances on ETH3D and Virtual KITTI, producing high-fidelity point clouds across indoor and outdoor environments. Crucially, it processes sequences exceeding 1,000 frames on a single GPU—where competing approaches either crash or degrade.
Scal3R struggles when lighting shifts dramatically mid-sequence or when viewpoints become too sparse, weakening cross-chunk correspondences. Despite this, the architecture unlocks practical applications: autonomous vehicles can now map entire city blocks from dashcam footage, and robotics platforms can construct digital twins without LiDAR. The fusion of test-time training with distributed context aggregation suggests a broader paradigm—neural networks that adapt their memory online as the world unfolds.
Scal3R proves that neural memory, continuously shaped by what the model sees, can outperform static architectures at scale. Visit EmergentMind.com to explore this paper further and create your own research videos.