- The paper introduces a probabilistic formulation that extends archetypal analysis using exponential family likelihoods to model diverse data types including binary, count, and multinomial data.
- It employs majorization-minimization algorithms to efficiently optimize archetype recovery while ensuring interpretability through convex combinations in parameter space.
- Empirical results on simulated and real-world datasets demonstrate improved archetype identification and visualization over standard geometric approaches.
Probabilistic Archetypal Analysis: A Comprehensive Overview
Introduction and Motivation
Archetypal Analysis (AA) is a factorization method designed to express observations as convex combinations of extreme patterns, or archetypes. The standard AA framework, rooted in geometric principles, restricts archetypes to the convex hull of real-valued data and is solved via alternating non-negative least squares. This formulation is elegant for continuous and vectorial data but is insufficient for non-Gaussian, count-based, binary, or probabilistic data types, which are prevalent in many real-world applications. The paper "Probabilistic Archetypal Analysis" (1312.7604) re-examines the foundations of AA and introduces a probabilistic framework compatible with a broader class of data, leveraging exponential family likelihoods, and providing a unified toolbox for archetype discovery under various observation models.
From Geometric to Probabilistic Archetypal Analysis
The core innovation of Probabilistic Archetypal Analysis (PAA) is the transition from constructing the convex hull in the observation space to constructing it in the parameter space of an appropriate exponential family. This generalization preserves the interpretability and data-driven nature of AA but enables direct modeling of counts (Poisson), probability vectors (Multinomial), and binary data (Bernoulli), among others.
Mathematically, PAA frames archetypal analysis as minimizing the negative log-likelihood of the observations under an exponential family model, subject to stochasticity constraints on the factor matrices. The archetype matrix is expressed as a convex combination of observation-specific parameters, and the observation likelihoods are computed with respect to these archetypal parameters. This approach decouples the observation model from the vector space structure and admits majorization-minimization updates for efficient optimization regardless of the data's type.
The numerical validation of PAA is extensive and considered in three primary settings: binary, count, and term-frequency data. Standard AA is notably limited outside the Gaussian setting, often failing to recover the true archetypes when data is generated according to non-Gaussian processes.
For binary observations, simulated experiments with K=6 archetypes in a d=10 dimensional binary space demonstrate that PAA consistently recovers the true generating archetypes, as compared to standard AA which frequently fails or identifies spurious matches.
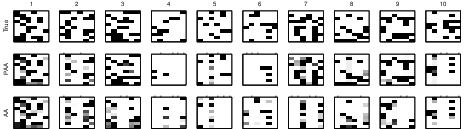
Figure 1: PAA matches ground-truth binary archetypes significantly more reliably than standard AA across 10 randomized trials.
In the context of count data modeled by Poisson distributions, PAA also demonstrates a much higher fidelity in archetype recovery, successfully matching the simulated archetype profiles more often than AA.

Figure 2: PAA achieves superior archetype identification in synthetic Poisson data, as evaluated by l1-distance matching.
Term-frequency data illustrate the challenge when archetypes are defined in the probability simplex but observed as raw frequency counts. Standard AA applied in term-frequency space is impeded by the destruction of convex-hull structure, whereas PAA, operating in the appropriate parameter space, maintains interpretability and identification.
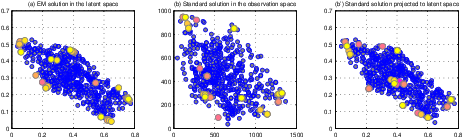
Figure 3: PAA recovers the true convex hull of archetypes in the probability simplex, while standard AA fails due to observation space distortions.
Practical Applications
NIPS Bag-of-Words (Multinomial Observation Model)
The PAA framework is applied to the NIPS bag-of-words corpus with N=1500 documents and M=12419 terms. PAA with a multinomial model identifies ten distinct document archetypes, where each archetype's prominent words are nearly mutually exclusive across archetypes, exemplifying the desired “purity” property. Notably, the approach uncovers an archetype characterized by Bayesian methodology, which standard AA did not capture when applied to term-frequency vectors.

Figure 4: Per-word probability distributions highlight the exclusivity of top words in each of the ten NIPS archetypes as discovered by PAA.
Austrian National Guest Survey (Bernoulli Observation Model)
On binary survey data describing winter tourist activities, PAA uncovers six salient tourist archetypes, from maximal sport engagement to minimal and culturally-oriented tourists. The simplex visualization reveals how individual tourists relate to these archetypes, with the model deviance and answer-specific highlighting elucidating fit and archetype composition.




Figure 5: Simplex visualizations display archetype proximity, model fit, and the relation of binary survey answers to archetype composition among Austrian winter tourists.
Disaster Counts by Country (Poisson Observation Model)
PAA identifies seven archetypal disaster profiles from a global count database spanning 15 disaster types in 227 countries. These include minimal (safe) and maximal (pervasively affected) profiles, as well as archetypes focused on complex disasters, epidemics, or geological phenomena. The simplex visualization again provides interpretability, highlighting both outlier archetypes and the disasters driving archetype formation.
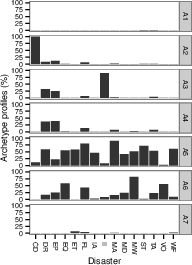
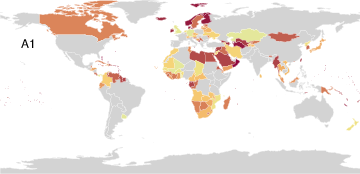
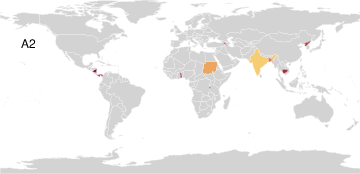
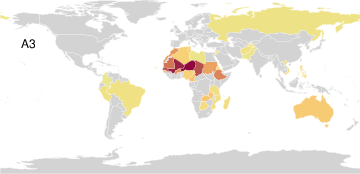
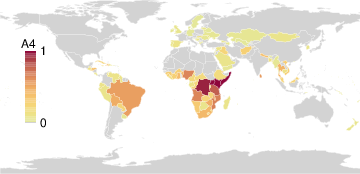
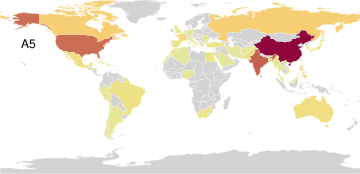
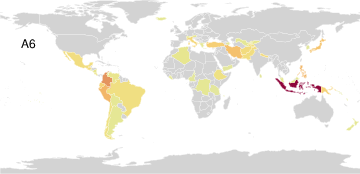
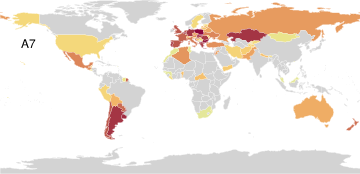
Figure 6: Disaster archetype profiles and geographic factor maps convey the diversity and concentration of disaster experiences among global archetypes.
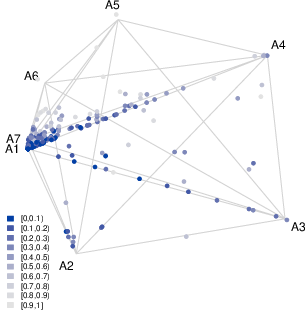
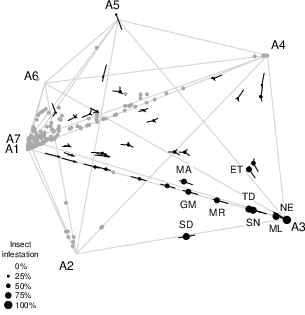
Figure 7: Simplex visualization reveals the proximity of archetypes and spatial clustering of archetype dominance in relation to insect infestations.
Connections to Other Matrix Factorizations
PAA is closely related to other matrix decompositions such as PCA, NMF, and PLSA, differing primarily in its enforcement of stochasticity and the explicit modeling of observation distributions. The data-driven construction of archetypes as convex combinations of observed parameters is a distinctive aspect, setting PAA apart from general non-negative or orthogonal factorization techniques. In the multinomial setting, for example, PAA produces archetypes analogous to LDA topics but with stricter interpretability guarantees due to its formulation.
Visualization Advances
The stochastic latent structure of archetype factors enables advanced simplex-based visualizations. The paper introduces enhancements such as deviance-based coloring, distance-preserving archetype placement, and “whiskers” indicating archetype contributions to individual projections. These tools provide granular interpretability even when the archetypal structure is non-trivial or the number of archetypes exceeds the two-dimensional simplex.
Theoretical and Practical Implications
PAA's theoretical advantage is the extension of archetypal analysis to data types that are not amenable to convex geometry, by operating in the natural parameter space of the corresponding exponential family. This framework also enables the integration of priors (e.g., sparse Dirichlet) for selecting the number of archetypes and supports Bayesian inference methods for improved statistical regularization.
Practically, PAA expands the domain of archetypal analysis to binary surveys, document corpora, count data, and likely to ordinal and Likert-scale data with appropriate observation models. This flexibility is critical for applications in marketing, social sciences, document analysis, and bioinformatics, where data is seldom continuous or Gaussian.
Conclusion
Probabilistic Archetypal Analysis broadens the applicability of archetypal analysis by generalizing the archetype discovery process to any data modeled by an exponential family, thus overcoming the constraints of the geometric convex hull construction on real-valued data. The main technical contributions include the probabilistic formulation suitable for Bernoulli, Poisson, and Multinomial data, efficient majorization-minimization algorithms, and advanced visualization methods for solution interpretability. This work provides a foundation for further research into dynamic, regularized, and Bayesian archetypal analysis, as well as extensions to ordinal and structured data types.