- The paper introduces a novel framework that combines sparse coding, manifold learning, and slow feature analysis to transform nonlinear signal variations into linear representations.
- It employs a functional embedding strategy that treats dictionary elements as traversing a smooth manifold, enhancing geometric interpretation and sparse function prediction.
- The study demonstrates SMT’s ability for hierarchical composition and temporal dynamics, facilitating advanced video processing and feature reconstruction.
Introduction
The paper on the "Sparse Manifold Transform" details a novel framework for signal representation that synergistically integrates concepts from sparse coding, manifold learning, and slow feature analysis. This framework transforms non-linear variations in the sensory signal domain into linear interpretations in a distinct embedding space, while preserving approximate invertibility. Distinctively, the Sparse Manifold Transform (SMT) offers an unsupervised, generative approach that concurrently models the sparse discrete and low-dimensional manifold structures observed in natural scenes. The SMT framework's stacking capability extends to modeling hierarchical compositions, broadening its applicability within signal representation dynamics. The manuscript provides both a theoretical exposition of the transform and empirical validations on synthetic and natural video datasets.
Sparse Coding in SMT
Sparse coding in the SMT approach seeks to approximate any given data vector x∈Rn as a sparse linear combination of dictionary elements, represented as a collection of signals ϕi. This yields the defining equation:
x=Φα+ϵ
In this expression, Φ∈Rn×m denotes a matrix comprising columns of the dictionary elements ϕi, while α∈Rm is a vector characterized by sparsity, containing signal coefficients. The noise vector ϵ is assumed to be Gaussian and relatively minor compared to x. Traditional dictionary learning methods adapt Φ to data statistics to maximize the sparsity of its generating coefficients α. This process often reveals significant data structure insights, such as Gabor-like dictionary elements in the context of natural images.
The sparse codes' representational strengths become evident when applied to natural image data, where the dictionary elements form Gabor-like functions. These functions embody spatial locality, orientation, and bandpass characteristics—resulting in robust tiling patterns across varied positions, orientations, and scales due to natural object transformations.
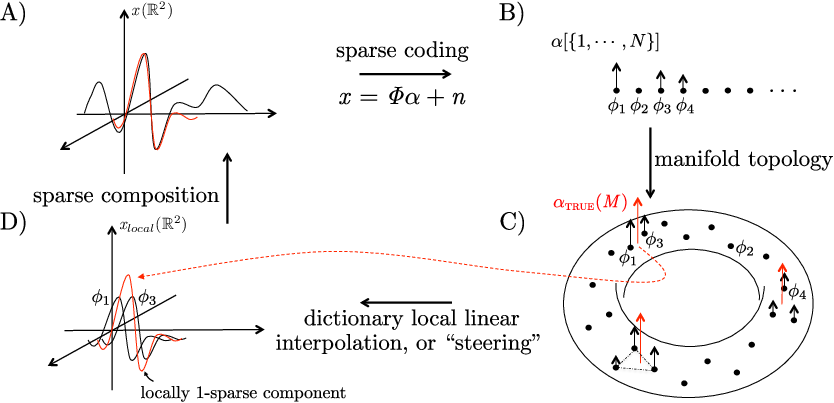
Figure 1: Dictionary elements learned from natural signals with sparse coding may be conceptualized as landmarks on a smooth manifold.
Functional Embedding and Manifold Learning
The SMT framework diverges from traditional manifold learning by employing a functional embedding strategy over individual data points. Instead of embedding specific data points on a manifold, SMT conceptualizes individual image regions as discrete components maneuvering over a unified manifold. Hence, this transforms the data into h discrete components that traverse the same manifold domain.
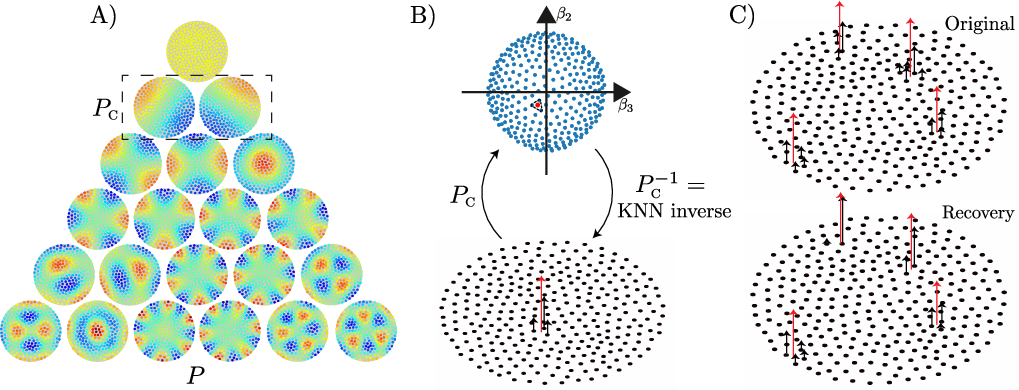
Figure 2: Demonstration of functional embedding on the unit disc, illustrating the classical manifold perspective integrated within the SMT framework.
SMT framework aligns with the theoretical principles of manifold learning by recognizing that data typically reside on a low-dimensional, smooth manifold embedded within a high-dimensional signal space. Importantly, it elucidates a general geometric embedding of dictionary elements when trained on natural scenes, leading to a significant augmentation in predictive capabilities for sparse functions.
SMT and Temporal Dynamics
Distinct from prior methods, the SMT exploits temporal coherence, thereby alleviating the conventional need for exhaustive nearest-neighbor searches. The temporal data series is treated such that video sequences form linear trajectories within embedding space, fundamentally enhancing flow linearity in both the manifold and geometric embedding perspectives.
The effectiveness of embedding matrices in the SMT framework underscores its efficacy in establishing connectivity between manifold learning, sparse coding, and temporal data structuring, transforming otherwise nonlinear transformations into linear trajectories efficiently.

Figure 3: SMT encoding of an 80-frame image sequence with temporal dynamics represented through different unit activities.
Hierarchical SMT Composition
The SMT framework's capability for hierarchical composition further demonstrates its depth and applicability. Each SMT layer can be visualized as a pair of sublayers—sparse coding followed by manifold embedding. This arrangement enables the modeling of composite hierarchical structures, aligning with tripartite pattern frameworks: sparse discrete structures, low-dimensional manifolds, and hierarchical compositions.
Hierarchically compositional properties within SMT facilitate progressive image manifold flattening through stacked layers, supporting a transition from lower to higher-level abstraction while maintaining crucial data characteristics in reconstructions and interpolations.

Figure 4: Stacked SMT layers depicting hierarchical representation and network architectures enabling hierarchical inference.
Conclusion
The "Sparse Manifold Transform" provides a comprehensive structure for understanding and modeling complex signal dynamics in both synthetic and natural domains. It addresses limitations in previous approaches by effectively amalgamating sparse discrete structures into functional embeddings on smooth manifolds, integrating dynamic spatio-temporal data characteristics. SMT's generative, unsupervised nature, combined with stackable hierarchical properties, showcases its potential in diverse applications, including advanced video signal processing and feature representation in AI. The ongoing exploration and potential developments in AI leveraging SMT principles promise significant advancements in representation learning and manifold-based signal interpretations.
