- The paper presents a boundary-aware network that uses a boundary attention mechanism and refined loss function to enhance portrait segmentation precision.
- The method leverages a semantic branch for high-level features, a boundary mining branch for extracting low-level details, and a fusion part to combine them effectively.
- Experiments on the PFCN+ dataset show that BANet achieves 43 FPS on 512×512 images with a 96.13% mean IoU, demonstrating both efficiency and high accuracy.
Boundary-Aware Network for Portrait Segmentation
The paper "Boundary-Aware Network for Fast and High-Accuracy Portrait Segmentation" (1901.03814) introduces a novel Boundary-Aware Network (BANet) designed for high-precision and real-time portrait segmentation. This network leverages a boundary attention mechanism and a refined loss function to selectively extract detailed information from boundary regions, achieving segmentation results that surpass the quality of manual annotations while maintaining a processing speed suitable for real-time applications.
Addressing Limitations of Existing Methods
Existing semantic segmentation models often fall short in producing fine boundaries in portrait segmentation due to two primary reasons. First, the quality of training data is limited by the manual annotation process, which struggles to capture intricate details like hair strands (Figure 1). Second, traditional models often downsample the input image significantly, losing detail information. Although models like U-Net [ronneberger2015u] attempt to fuse low-level information, their large parameter count hinders training on high-resolution images.



Figure 1: Polygon annotations in the Supervise.ly dataset highlight the coarse nature of manual annotations, particularly in boundary areas.
BANet Architecture and Functionality
BANet addresses these limitations through a specialized architecture and training regime (Figure 2). The network comprises three key components: a semantic branch, a boundary feature mining branch, and a fusion part. The semantic branch extracts high-level semantic features, generating a boundary attention map that guides the boundary feature mining branch to focus on low-level details. The fusion part then combines these features to produce the final segmentation output.
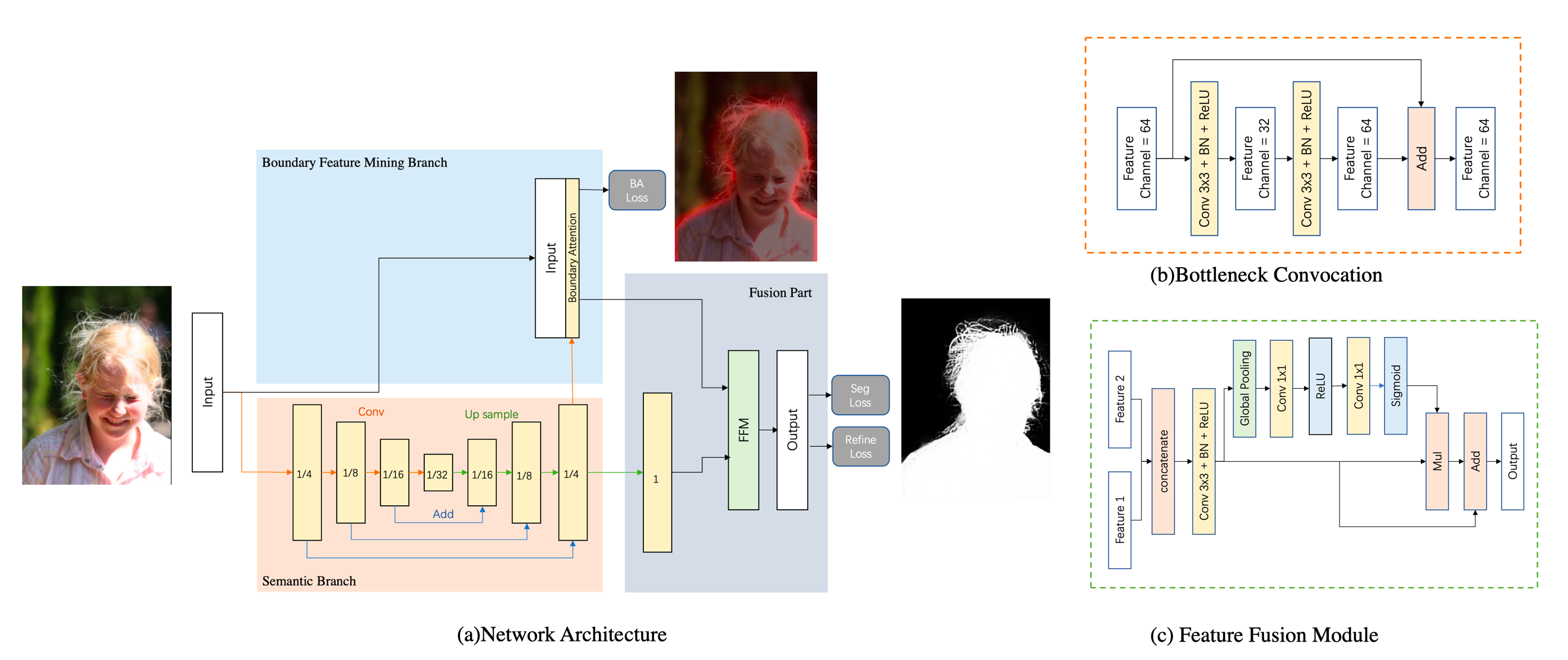
Figure 2: The Boundary-Aware Network pipeline includes a semantic branch for high-level features, a boundary feature mining branch for low-level details, and a fusion part to combine these features.
Semantic Branch
The semantic branch employs a fully convolutional structure, similar to FCN-4s, using ResNet [he2016deep] bottleneck structures to enlarge the receptive field while maintaining computational efficiency. This branch outputs a 1/4 size feature map that balances semantic information with spatial awareness.
Boundary Feature Mining Branch
This branch refines the segmentation by focusing on boundary areas. A boundary attention map, generated from the semantic branch, guides the extraction of low-level features. This attention map is supervised by a boundary attention loss (BA loss), calculated using canny edge detection on portrait annotations and dilated based on the ratio of portrait area to background area. The input image and attention map are concatenated, allowing the convolutional layers to extract detailed information in a targeted manner.


Figure 3: The boundary attention mechanism focuses the network's attention on the edges of the portrait, enabling finer detail extraction.
Fusion Part
The fusion part combines the high-level semantic features from the semantic branch and the low-level details from the boundary feature mining branch. Following the approach in BiSeNet [yu2018bisenet], features are concatenated and processed through a series of convolutional layers, batch normalization, and ReLU activations. Global pooling is used to calculate a weight vector, facilitating feature re-weighting and selection.
Loss Function
The loss function consists of three components: a segmentation loss (Lseg), a boundary attention loss (Lbound), and a refine loss (Lrefine). The segmentation loss employs binary cross-entropy to guide the segmentation results. The boundary attention loss supervises the boundary attention map, forcing the network to learn features with strong inter-class distinction.
The refine loss, composed of a cosine loss (Lcos) and a magnitude loss (Lmag), refines boundary details. The cosine loss supervises the gradient direction of the segmentation confidence map, while the magnitude loss constrains the gradient magnitude, encouraging clear and sharp results. The refine loss is applied selectively to boundary areas using a weighted loss function.
L=αLseg+βLbound+γLrefine




Figure 4: Gradient Calculation Layer (GCL) computes image gradient on GPU using Sobel operator, enabling refine loss to enhance boundary details.
Experimental Results and Analysis
The BANet was trained and evaluated on the PFCN+ [shen2016automatic] dataset, with pre-training on the Supervise.ly dataset. Data augmentation techniques, including random rotations, flips, and lightness adjustments, were employed to improve generalization. The model achieves 43 FPS on 512×512 images with a parameter size of only 0.62 MB (BANet-64). A larger version, BANet-512 (12.75 MB), achieves a mean IoU of 96.13% on the PFCN+ dataset.
The results demonstrate that BANet produces high-quality segmentation results with finer details compared to other real-time and portrait segmentation networks (Figure 5). Ablation studies confirm the effectiveness of the boundary attention map and refine loss in improving segmentation accuracy and boundary quality (Figure 6).






Figure 5: Visual comparison of segmentation results from BiSeNet, EDAnet, PFCN+, U-Net, and BANet-64, highlighting the superior boundary detail achieved by BANet.



Figure 6: Ablation study showing the impact of boundary attention map and refine loss on improving semantic representation and boundary quality.
Applications and Limitations
The model can be used in mobile applications for real-time selfie processing, background changing, and image beautification (Figure 7). The light architecture and high inference speed make it suitable for deployment on mobile devices.









Figure 7: Application of BANet to background changing, demonstrating its practical utility in image editing.
However, the reduced number of channels in the semantic branch limits the model's ability to represent complex scenarios, such as multi-person shots or occlusions. Additionally, the training dataset size is limited, which may affect the model's generalization performance in real-world applications.
Conclusion
BANet presents a compelling solution for fast and accurate portrait segmentation, leveraging boundary attention and refined loss functions to produce high-quality results with fine details. Future work will focus on expanding the training dataset and exploring the deployment of BANet on mobile phones.