- The paper introduces tree-based machine learning models to improve insurance tariff pricing over traditional GLMs.
- It demonstrates how regression trees, random forests, and gradient boosting machines capture nonlinear relationships to optimize claims frequency and severity.
- The study provides detailed evaluations using tailored loss functions, cross-validation, and interpretability tools to meet regulatory transparency.
Boosting Insights in Insurance Tariff Plans with Tree-based Machine Learning Methods
Introduction
The study focuses on innovating insurance pricing models by employing tree-based ML techniques rather than relying solely on traditional generalized linear models (GLMs). The paper articulates the integration of regression trees, random forests, and gradient boosting machines to optimize insurance tariffs by considering both the frequency and severity of claims. It underscores the complexity of insurance data, characterized by unbalanced counts and excess zeros for frequency, contrasted with potentially long-tailed distributions for severity. Moreover, the authors emphasize the importance of transparency and interpretability in insurance pricing models due to regulatory demands.
Insurance Pricing Models
The traditional GLM remains prevalent in the insurance sector, particularly for actuarial pricing models. Typically, the prediction of loss cost is bifurcated into frequency and severity models. GLMs are preferred due to their straightforward interpretability and regulatory acceptance. They model the claim frequency and severity separately, with frequency models often employing the Poisson distribution and severity models using gamma or log-normal distributions.
The novel approach in this study involves a meticulous adaptation of tree-based models to accommodate the distinct characteristics of insurance data. These models address the limitations of GLMs, particularly in capturing complex nonlinear relationships and interactions between risk factors.
Implementation of Tree-based Methods
Regression Trees: The study employs regression trees as fundamental units that divide the predictor space into distinct regions based on decision rules, with each region associated with a constant prediction. Although transparent, single decision trees suffer from high variance and are relatively simplistic.
Random Forests: By constructing numerous decision trees using bootstrap samples, random forests enhance predictive performance through variance reduction. They introduce randomness in the variable selection process, further decorrelating the trees to marginally improve model robustness.
Gradient Boosting Machines (GBM): GBMs iteratively build trees to correct errors made by existing models. By applying gradient descent in the functional space, GBMs enhance model accuracy. Stochastic gradient boosting, a variant of GBM, further improves performance by introducing randomness during training.
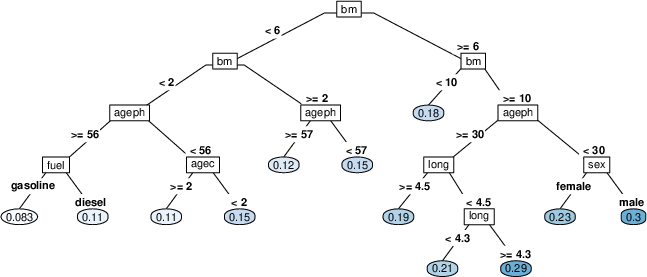
Figure 1: Visual representation of a regression tree for claim frequency with nodes (rectangles) containing the splitting variable xv, edges (lines) representing the splits with cut-off c, and leaf nodes (ellipses) containing the prediction values y^Rj.
Loss Functions and Cross-Validation
The paper adapts loss functions to align with the distributional properties of insurance data. For instance, the Poisson deviance is used for frequency models, while the gamma deviance is employed for severity models. A comprehensive cross-validation scheme is implemented to tune model parameters effectively, ensuring model stability across different data partitions.
Model Interpretability
Given regulatory requirements demanding model transparency, interpretability tools such as variable importance measures, partial dependence plots, and individual conditional expectations are utilized. These tools dissect the "black box" nature of tree-based models, offering insights into the influence of different risk factors on the predictions.
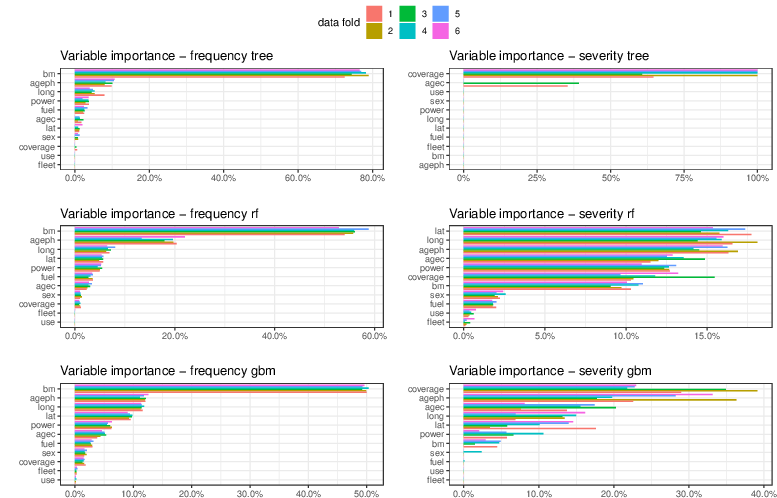
Figure 2: Variable importance in the optimal regression tree (top), random forest (middle), and gradient boosting machine (bottom) per data fold (color) for frequency (left) and severity (right).
Statistical and Economic Evaluation
The a posteriori performance of tree-based models is assessed using both statistical measures (deviance) and business metrics (model lift, Gini indices) to quantify economic value and potential for adverse selection mitigation. The analysis illustrates that gradient boosting machines provide substantial economic benefits by aligning premiums more closely with the actual risk, enhancing the insurer's ability to differentiate risk accurately.
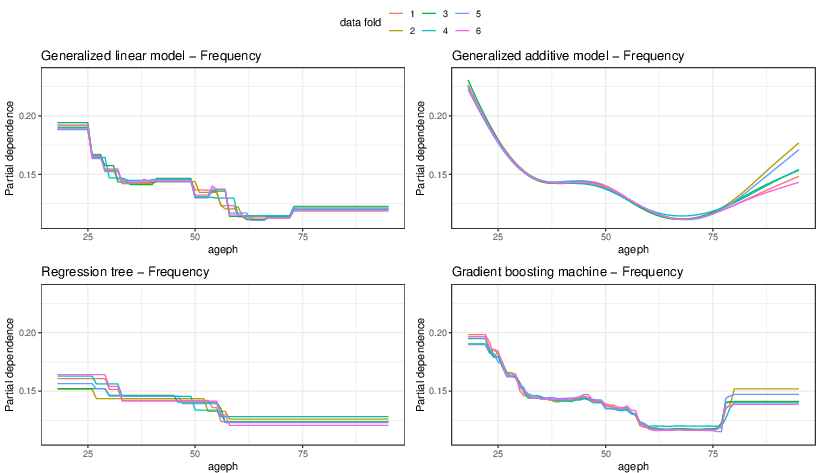
Figure 3: Partial dependence plot to visualize the effect of the age of the policyholder on frequency for the optimal model obtained per data fold (color) in a GLM (top left), GAM (top right), regression tree (bottom left), and gradient boosting machine (bottom right).
Conclusion
Tree-based machine learning techniques, particularly gradient boosting machines, show promise for advancing insurance pricing strategies beyond traditional GLMs. These methods offer enhanced predictive power and economic advantages while adhering to the transparency required by regulatory standards. Future research could explore further integration of these models into actuarial practices, balancing analytical rigor with regulatory compliance.