- The paper introduces a full-parameter Bayesian inference method for MAR models, enabling complete exploration of the stationarity region.
- The method employs advanced MCMC sampling with conjugate priors and automated relabelling to resolve label switching without bias.
- Empirical results on synthetic and real data demonstrate improved model selection, uncertainty quantification, and density forecasting.
Bayesian Analysis of Mixture Autoregressive Models Covering the Complete Parameter Space
Introduction
Bayesian inference for mixture autoregressive (MAR) models allows quantification of forecast uncertainty in non-Gaussian, multimodal, and heteroskedastic time series. The paper "Bayesian analysis of mixture autoregressive models covering the complete parameter space" (2006.11041) addresses significant limitations observed in previous Bayesian approaches, specifically with respect to covering the full stationarity region of the MAR parameter space and handling label switching in MCMC outputs. The authors propose new MCMC schemes and post-hoc relabelling algorithms enabling rich posterior exploration and robust inference, empirically validated on both synthetic and real-world data.
Background: MAR Models and Bayesian Challenges
A MAR(g;p1,...,pg) model represents the conditional distribution of yt as a convex combination of g AR processes (potentially differing in lag length), thus providing flexible modeling of regime-switching, asymmetric, and multi-modal time series. The primary statistical challenge in Bayesian estimation of MAR models is that the stationarity region in the autoregressive parameter space is highly complex and constraints on the stationarity of mixture components are not sufficient nor necessary for MAR process stationarity. Previous works, notably Sampietro (2006) and Hossain (2012), imposed simplifying restrictions that precluded significant subregions of the parameter space, causing biased inference and missing potentially relevant regimes.
Furthermore, Bayesian mixture models are subject to label switching due to the invariance of the likelihood under permutation of mixture component indices. Prior works handled this via identifiability constraints, but these introduce sampling bias and convergence problems.
Methodology: Full-Region Bayesian Inference with Efficient Label Handling
The methodology consists of several key innovations over prior Bayesian estimation approaches for MAR:
- Direct Sampling in the Stationarity Region: For AR coefficients, the authors use Random Walk Metropolis moves with proposals unrestricted except for rejection of non-stationary parameters, as defined by the joint stationarity matrix condition. This is in contrast to sampling in partial autocorrelation space or using truncated proposals, which inadequately cover the full stationary region.
- Priors: Conjugate and hierarchical priors are chosen for other parameters (shifts, scales, mixing probabilities), following recommendations of Richardson and Green (1997).
- Gibbs-type Updates: All but the AR parameters are sampled directly via conjugate updates, with the latent data allocations also drawn to facilitate tractable likelihoods via data augmentation.
- Model Selection via RJMCMC: Reversible jump MCMC (RJMCMC) is implemented for autoregressive order selection in each component, using symmetric proposal moves to balance acceptance probabilities without conservative bias towards lower orders. Marginal likelihoods required for model selection are estimated using the Chib and Chib-Jeliazkov identities.
- Post-hoc Relabelling for Label Switching: Rather than imposing identifiability constraints, the method employs a k-means based relabelling algorithm, selecting initial cluster centers in parameter space from the early chain sample and iteratively updating assignments and centroids.
Empirical Evidence: Simulation Studies
The performance of the method is systematically evaluated using both synthetic data and real-world time series.
Simulation Results
Simulated series from two mixture models—one with two components and order-one AR, another with three components and a mix of AR(2) and AR(1)—demonstrate the algorithm’s ability to:
- Correctly select the true mixture model order and lag structure via marginal likelihood comparison (Table results described in the paper).
- Accurately recover the true parameter values, with high posterior densities close to ground truth.
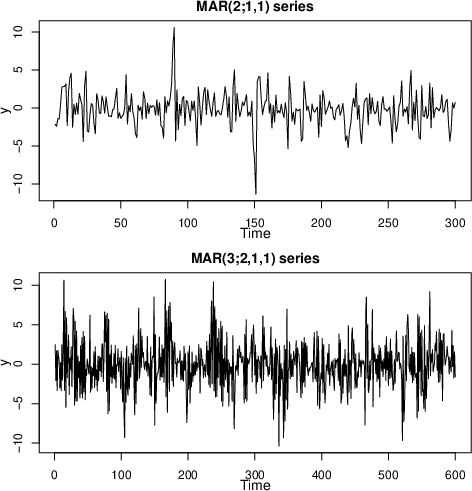
Figure 1: Simulated series from MAR (2;1,1) (top) and MAR (3;2,1,1) (bottom).
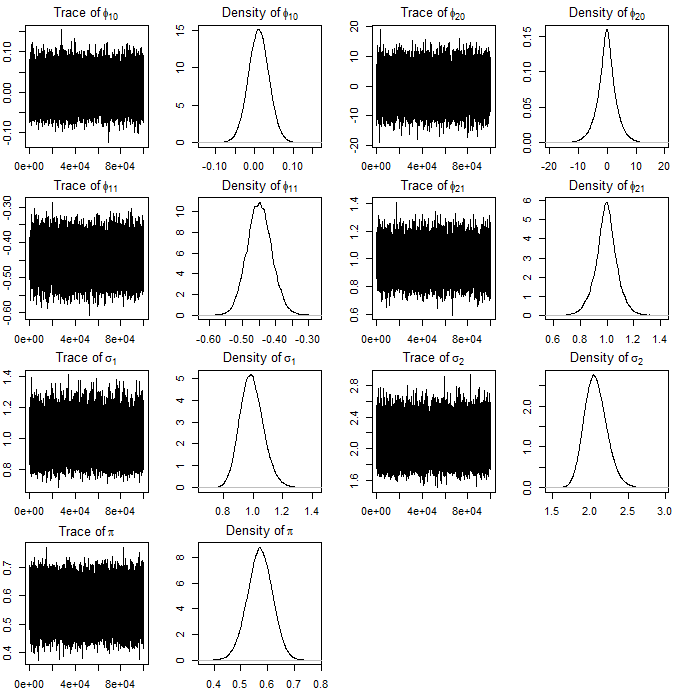
Figure 2: Trace and density plots for simulated MAR (2;1,1) model showcase fast mixing and well-identified posteriors for all parameters.
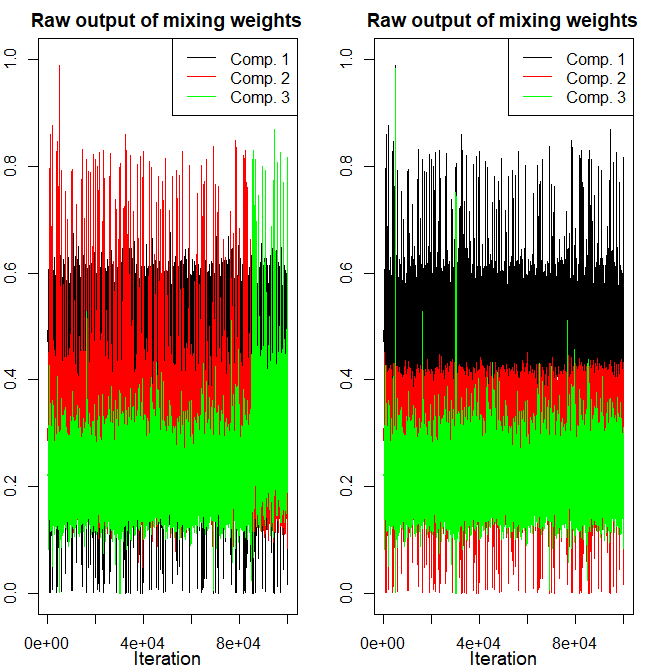
Figure 3: Demonstration of relabelling effectiveness—raw MCMC output (left) suffering label switching is resolved in the adjusted output (right), particularly visible in mixing weights.
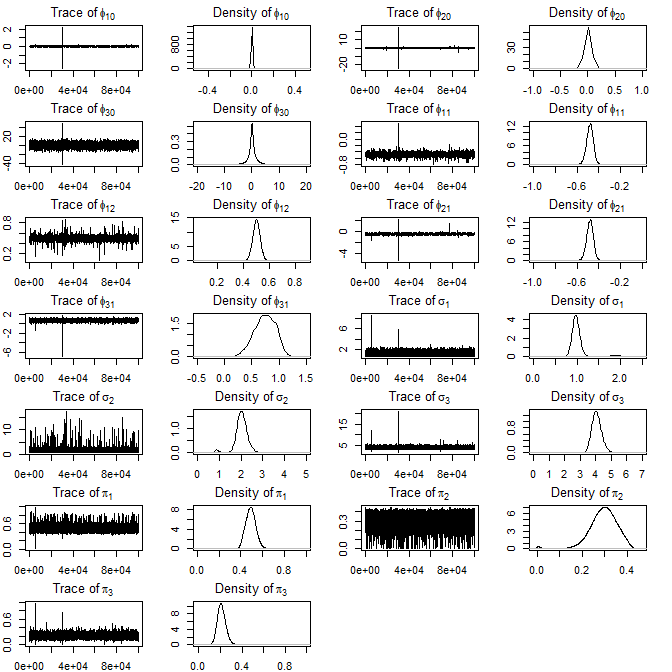
Figure 4: Trace and density plots for MAR (3;2,1,1) after relabelling; multimodalities introduced by label-switching are handled properly.
Consistency across 400 simulated datasets also demonstrates the method’s robustness (final appendix figure).
Real-Data Analyses
IBM Common Stock Closing Prices
Analysis of daily returns for IBM stock (first-differenced) favors a MAR (3;4,1,1) model. The posterior displays clear evidence of multimodality in AR parameters, capturing complex regime structure. Notably, this differs from frequentist EM-based selection that typically underfits by missing such modes.
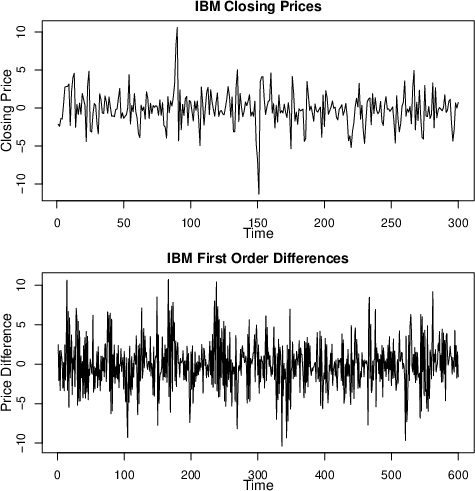
Figure 5: IBM closing prices (top); first-order differences (bottom).
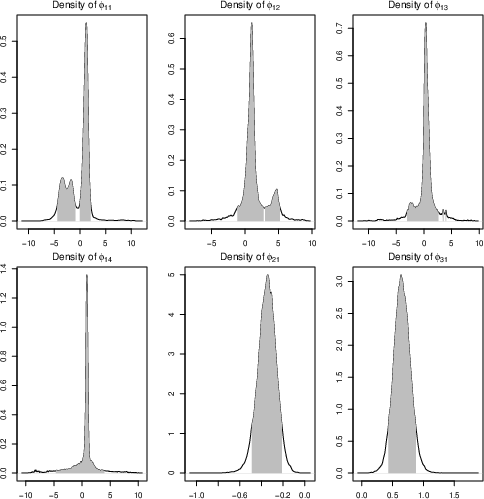
Figure 6: Posterior densities and 90% HPDR for AR parameters in the selected model for IBM—multimodal structure is evident.
Canadian Lynx Data
For the log-transformed Canadian lynx population data, the algorithm identifies a MAR (2;1,2), in contrast to previous BIC-based analyses. The resulting posteriors include parameter values estimated by Wong and Li (2000), but feature substantially wider credible regions, especially for scale parameters, highlighting correct uncertainty propagation.
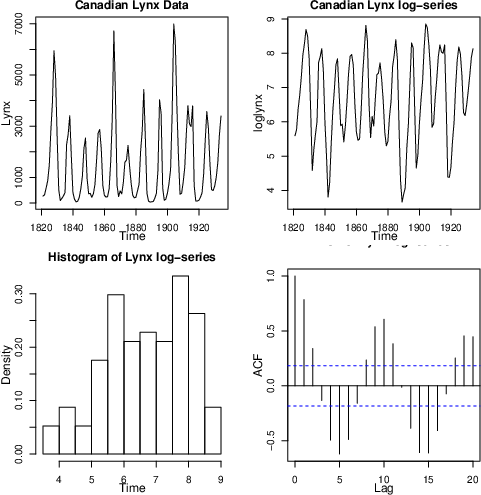
Figure 7: Original Canadian lynx series, log-transformed series, histogram, and autocorrelation plot illustrate strong cyclic structure and multimodality.
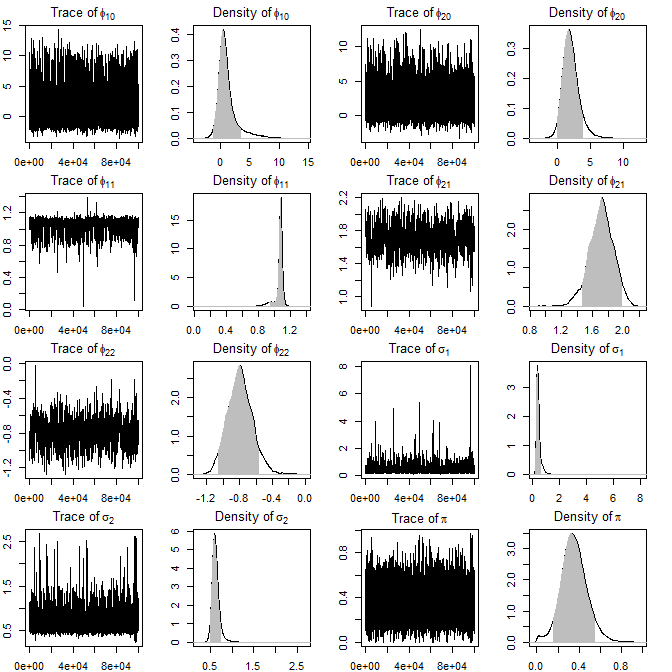
Figure 8: Posterior trace plots and densities for MAR (2;1,2) fit to log-lynx series—MLEs from prior studies are within the 90% credible region.
Comparison to Prior Methods
- Complete Parameter Space Coverage: The method never artificially restricts the sampler using arbitrary bounds in AR parameter proposals. Both stationarity and multimodal posterior features are preserved.
- Label Switching: The relabelling algorithm robustly resolves switching, compared to convergence-degrading identifiability constraints.
- Forecasting: Uncertainty in future predictions is naturally integrated by averaging density forecasts over the posterior sample.
Bayesian Density Forecasting
Density forecasting in MAR processes is carried out by simulating from the full posterior, constructing predictive densities as mixtures of conditional distributions (analytic when available or by Monte Carlo otherwise), and averaging over posterior samples. For the IBM dataset, the MCMC-based forecast outperforms EM-point-estimate predictions, especially apparent in the higher predictive probability mass attached to actual observations and more stable predictive densities for multi-step-ahead forecasts.
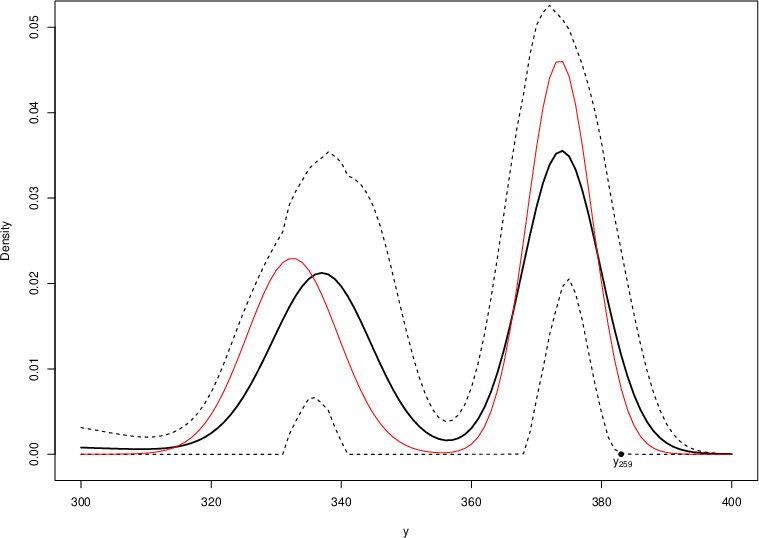
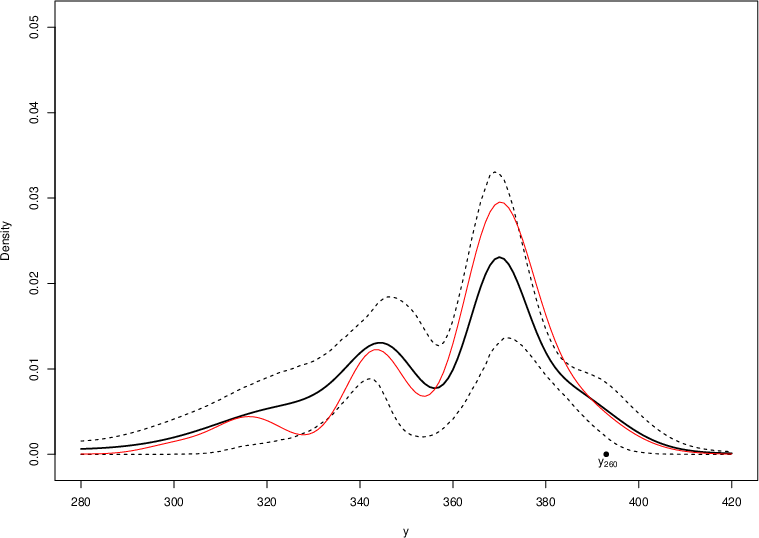
Figure 9: Bayesian density forecasts for 1- and 2-step-ahead predictions of IBM returns at t=258: MCMC-based Bayesian predictive density (solid black), 90% credible interval (dashed), EM-based prediction (solid red). Bayesian averaging stabilizes the predictive distribution and captures higher posterior predictive mass at the real observations.
Consistency and Robustness
To validate the approach’s statistical consistency, the authors perform large-scale simulation and posterior density estimation across numerous random datasets, showing that empirical densities concentrate around true data-generating values with increasing data size.
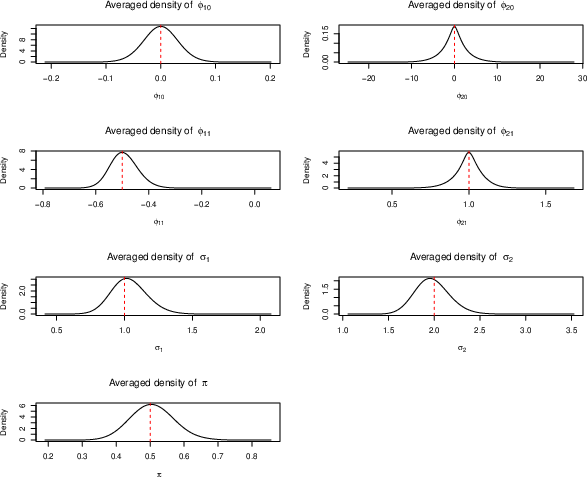
Figure 10: Averaged posterior densities for parameters across 400 simulated datasets; vertical reference lines indicate true parameter values.
Implications and Future Directions
This work resolves a longstanding practical challenge in Bayesian time series modeling with mixtures—efficient, bias-free posterior inference and model comparison for MAR models. By fully accounting for the complex geometry of the stationarity region and by employing robust post-processing for label assignment, this method ensures that multimodal posteriors, common in financial and ecological applications, are faithfully captured. This has practical implications for regime identification, risk modeling, and high-fidelity probabilistic forecasting in non-linear, non-Gaussian settings.
Theoretically, the approach establishes a template for full-region Bayesian inference in other classes of non-linear, mixture-based time series models. Future improvements could focus on optimizing algorithmic efficiency for high-dimensional mixtures (e.g., via MALA or Riemannian MCMC proposals), and non-Gaussian components such as Student-t or alpha-stable processes to better model heavy tails, as alluded to in the discussion.
Conclusion
The proposed Bayesian inference scheme for mixture autoregressive models advances the state of the art by providing:
- Full exploration of the stationary parameter regime without truncation or constraint bias.
- Unbiased, automated resolution of label switching via post-hoc relabelling.
- Empirically validated robust parameter and order inference with informative uncertainty quantification.
- Improved density forecasting by integrating model and parameter uncertainty over the true posterior.
These methodological advancements are applicable to a range of fields requiring accurate modeling of complex, multimodal, and non-linear temporal dynamics.