- The paper introduces a modular drone system that integrates Transformer-based semantic segmentation with real-time traffic light classification for BVIP navigation.
- It leverages SegFormer-B0 trained on Mapillary Vistas to accurately segment urban features, achieving high per-class IoU in critical zones like sidewalks and crosswalks.
- The system’s real-time control adjusts drone velocity based on segmentation outputs and provides voice feedback to safely guide users through intersections.
System Architecture and Technical Overview
The paper presents an integrated assistive system leveraging drone-based vision and real-time Transformer-based semantic segmentation to support blind and visually impaired people (BVIP) in urban navigation. The "flying guide dog" is composed of three core modules: street view semantic segmentation, traffic light classification, and drone control, unified for robust path guidance and intersection safety.
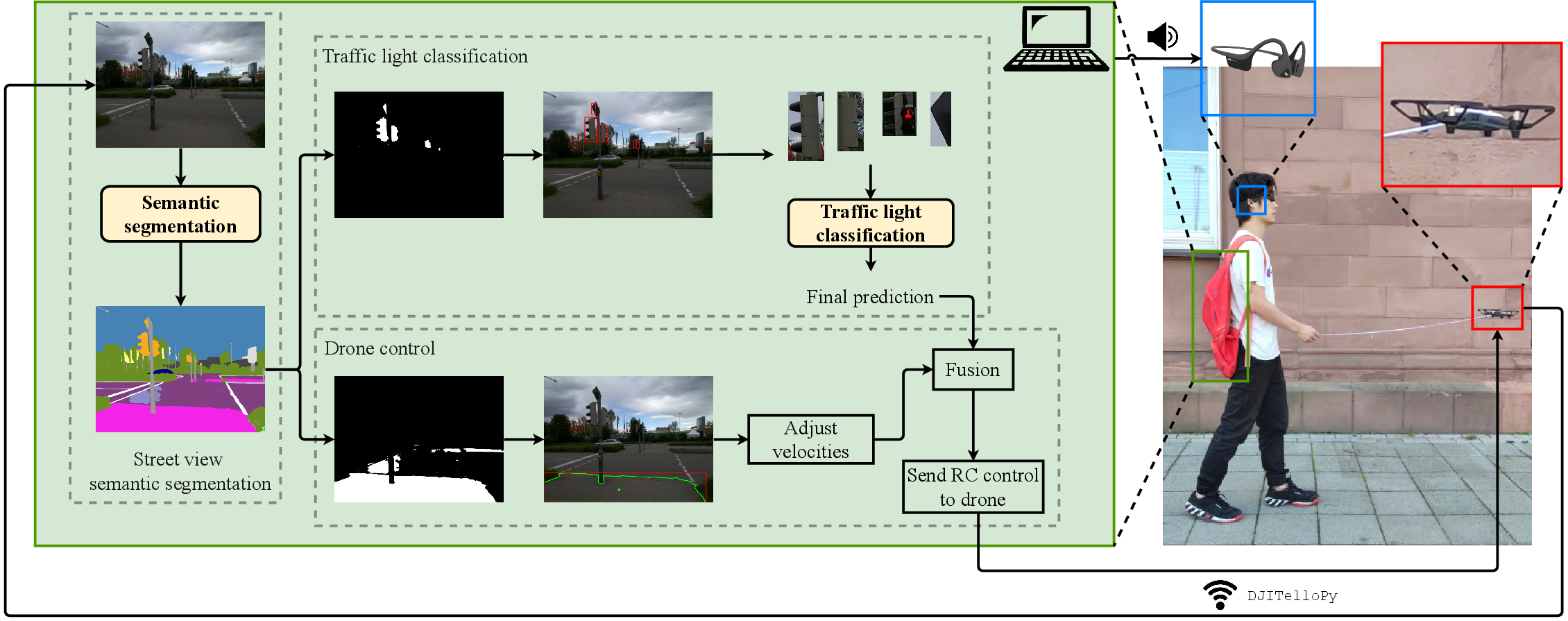
Figure 1: System overview. There are three components: street view semantic segmentation, traffic light classification, and drone control.
SegFormer-B0, a hierarchical Transformer backbone, was chosen for its computational efficiency and robustness against scene corruption. The drone's forward-facing camera supplies real-time images, processed to deliver dense pixel-level predictions of walkable areas (sidewalks, crosswalks), obstructions, and traffic light locations. Model inference, velocity computation, and logical fusion with traffic light status are executed onboard or via laptop; the drone responds with velocity adjustments and voice prompts to the user.
To ensure the segmentation module generalizes across diverse viewpoints (pedestrian vs. vehicle), the model is trained on Mapillary Vistas—a dataset that is substantially larger (25,000 annotated images, 66 categories) and more viewpoint-diverse than Cityscapes.
The SegFormer-B0 configuration, trained with AdamW and strong spatial augmentations, achieves a mean Intersection over Union (mIoU) of 41.83% on Mapillary Vistas validation, with strong per-class IoU in streetscape categories critical for BVIP navigation: Road (85.20%), Sidewalk (62.32%), Crosswalk markings (63.80%), and Traffic Light (61.06%).
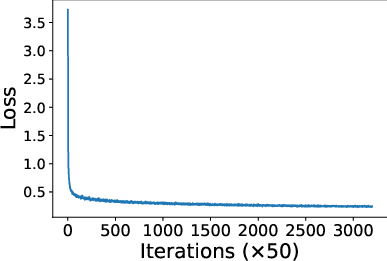
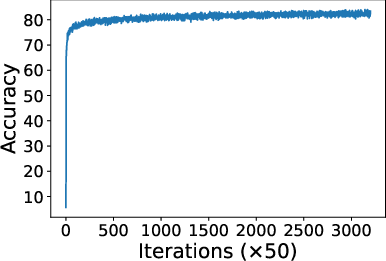
Figure 2: Loss dynamics during SegFormer-B0 training, depicting fast early convergence and plateauing after 25,000 iterations.

Figure 3: Qualitative results of predictions of different models trained on different datasets. SegFormer-B0 trained on Mapillary Vistas segments sidewalk and crosswalk significantly better than models trained on Cityscapes.
Models trained exclusively on Cityscapes fail to generalize to pedestrian point-of-view images; SegFormer-B0 on Mapillary Vistas produces accurate segmentation, enabling reliable extraction of walkable paths and safer navigation.
Traffic Light Classification and Dataset Creation
Recognizing the absence of a dedicated traffic light dataset covering both pedestrian and vehicle targets, the authors introduce the PVTL (Pedestrian and Vehicle Traffic Lights) dataset. Images are cropped from Cityscapes, Mapillary Vistas, and Pedestrian Lights, then manually labeled into five classes: {pedestrian-red, pedestrian-green, vehicle-red, vehicle-green, others}, with class balancing at 300 images per class for training parity.

Figure 4: PVTL dataset overview with five traffic light categories.
Classification is performed on cropped patches generated from SegFormer’s mask output. A lightweight CNN (5 conv, 3 FC layers, 2.4M params) is trained on PVTL, achieving 83% accuracy at 670 FPS, offering substantially higher throughput than fine-tuned ResNet-18 (90% accuracy, 167 FPS). The lightweight model’s performance is adequate for safety-critical feedback in intersection crossing scenarios where real-time response is paramount.
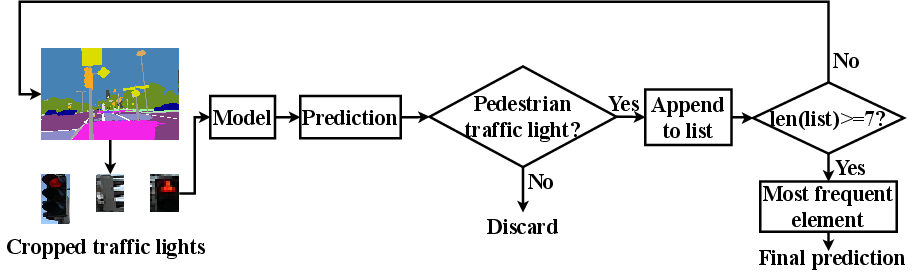
Figure 5: Multi-frame based traffic light classification process. Prediction buffer robustifies final decision and mitigates false positives from transient frames.
Each traffic light prediction is buffered across seven frames; only the mode of accumulated predictions is output, which improves robustness against misclassification due to lighting or occlusion.
Drone Control Integration
Based on segmentation outputs, the drone estimates centroid and contour of the largest walkable area, updating four velocity components: up/down (via vision-based altitude), forward, left/right, and yaw. Horizontal centroids dictate left/right commands, partitioned for yaw orientation through binary control codes. Traffic light prediction is fused into the control logic; forward velocity is set to zero and prompts "stop" if pedestrian red is detected, or is incremented for green with "go" prompts via a bone conduction headset.
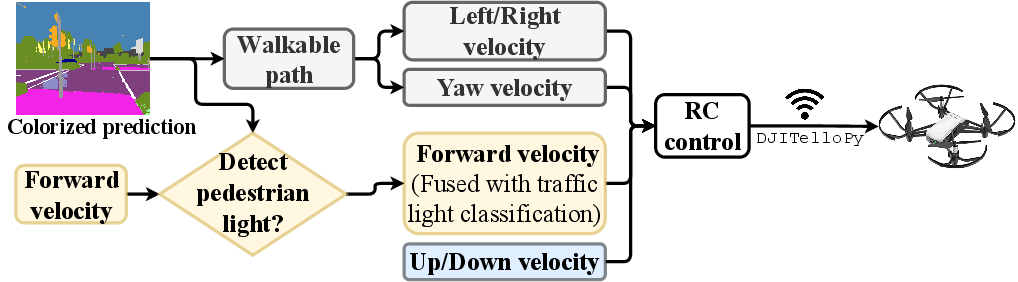
Figure 6: Drone control overview. Velocity is dynamically updated according to walkable path segmentation and real-time traffic light prediction.
Algorithmic smoothing (high-pass and low-pass filtering) of centroid motion mitigates jitter-induced navigation errors, ensuring stable guidance and obstacle avoidance.
Experimental Evaluation
Benchmarking against state-of-the-art real-time segmentation networks (e.g., RGPNet), SegFormer-B0 achieves comparable mIoU with far fewer parameters (3.8M vs. 9.4M-17.8M) and operates at 15.2 FPS on high-resolution (1024x2048) images. On the drone (DJI Tello with integrated RGB camera), end-to-end pipeline inference is measured at ~85 ms/frame (11.7 FPS) at 320x240 resolution, with segmentation consuming the majority of runtime.
Qualitative and User Study Analysis
A user study employing NASA-TLX was conducted under two scenarios: sidewalk navigation and intersection crossing. Six blindfolded participants (aged 24-35) followed the drone—either via a string or voice feedback.


Figure 7: Sidewalk navigation scenario during user study.
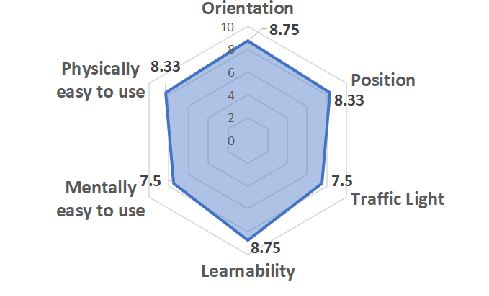
Figure 8: Evaluation results of the user study. Participants rate orientation, position, learnability, and physical ease highly; mental ease and traffic light assistance receive slightly lower scores.
Participants reported reliable orientation guidance and robust obstacle avoidance. Learnability and physical effort were rated positively, substantiating usability for BVIP. The traffic light crossing feature requires further refinement: false guidance toward mid-intersection pedestrian zones was observed, suggesting more nuanced velocity modulation and intersection-specific logic.
Implications and Future Directions
The integration of Transformer-based segmentation into drone navigation systems introduces a scalable, viewpoint-agnostic solution for BVIP navigation in complex urban environments. PVTL dataset facilitates further research in intersection navigation, supporting both semantic segmentation and classification benchmark creation.
Practical deployment is currently constrained by drone battery runtime (~13 minutes) and limited wind resistance; addressing these technical barriers will demand hardware scaling and edge AI optimization (e.g., Nvidia Jetson). Research trajectories include full onboard AI inference, extension to embedded systems, and more nuanced multi-agent or multi-sensor fusion for intersection-specific logic.
The theoretical implications are substantial, demonstrating the viability of Transformer architectures for real-time urban scene understanding applications outside classical autonomous driving. The modular system paves the way for robust, portable, and adaptive AI-driven assistive robotics.
Conclusion
This paper proposes a methodologically rigorous, modular prototype for BVIP outdoor navigation leveraging Transformer-based segmentation, custom traffic light recognition, and real-time control logic. While runtime and environmental robustness remain bounded by current drone hardware, experimental results—both quantitative and from user studies—demonstrate effective, easy-to-use navigation and intersection assistance. The system architecture, dataset creation, and deployment methodology constitute a solid foundation for subsequent development in multimodal, mobile AI assistive technologies.