- The paper proposes a Bayesian nonparametric framework that eliminates the need to predefine the number of skills via a dynamic Dirichlet Process approach.
- It employs variational inference with a Gumbel-Softmax reparameterization to optimize option policies and termination functions in hierarchical RL.
- Empirical results in proof-of-concept and Atari environments demonstrate the model's high adaptability and superior performance against fixed-skill baselines.
Bayesian Nonparametrics for Offline Skill Discovery
Introduction
The paper "Bayesian Nonparametrics for Offline Skill Discovery" addresses the challenge of skill discovery in the context of offline reinforcement learning (RL). In hierarchical RL frameworks, skills or low-level policies provide temporal abstraction, enhancing the learning process and facilitating complex behavior. While existing methods require prior specification of the number of skills (K), this paper proposes a Bayesian nonparametric approach that obviates the necessity to predetermine K and dynamically adapts the skill set as learning progresses. This approach leverages variational inference and continuous relaxations, implementing a Dirichlet Process Mixture Model (DPMM) inspired structure. Empirical results demonstrate its superiority over state-of-the-art skill discovery algorithms in various environments.
Methodology
Model Setup
Reinforcement learning skills are represented within an options framework, comprising initiation sets, policies, and termination functions. The high-level policy controls when options should be initiated and terminated. In this work, a shared high-level policy across expert-generated trajectories is assumed, which does not depend on the specific state. This simplification allows for a Bayesian treatment of η (the policy over options), modeled with a nonparametric infinite dimensional vector using a stick-breaking process.
Variational Inference
The paper employs variational inference to handle the intractability of direct posterior computation. The ELBO (Evidence Lower Bound) is maximized, facilitating the differentiation required to optimize the model parameters θ (option policies and termination functions) and ϕ (variational parameters for posterior approximation). The approximate posterior assumes a structure, respecting the conditional independences of a graphical model and uses the Gumbel-Softmax distribution to handle categorical latent variables within a reparameterizable framework.
Nonparametric Extension
The nonparametric aspect is achieved by employing a GEM(α) prior over options η. This facilitates working with an infinite number of potential skills, incrementing K as needed based on utilization across trajectories, following a heuristic method based on usage statistics. This process dynamically increases the model's capacity to adapt to complex environments without explicit specification of K, improving adaptability and performance across diverse RL tasks.
Results
Proof-of-Concept Environment
In a controlled environment designed to verify capability, the model successfully infers a sufficient number of options to capture the expert behavior, scaling well with increasing vocabulary size of agent inputs. Without manual tuning, the method consistently recovered the correct number of options to fulfill the task requirements, emphasizing its potential for cases where the number of requisite skills is not known a priori.
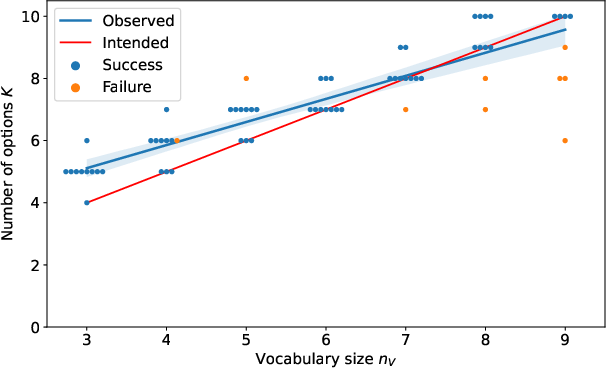
Figure 1: Results for our proof-of-concept environment. The model successfully recovers and utilizes a sufficient number of options aligning with theoretical expectations.
Atari Environments
Extensive evaluation in several Atari games demonstrated that the proposed model outperformed existing baselines such as DDO and CompILE. By using nonparametric skill discovery, the model achieved comparable or superior performance without pre-specifying the number of skills, achieving high adaptability across varying gameplay dynamics.
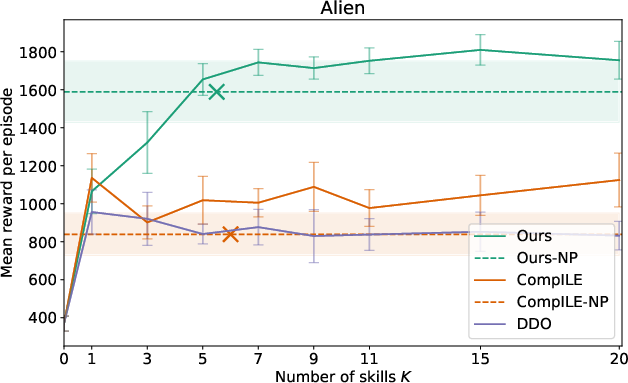
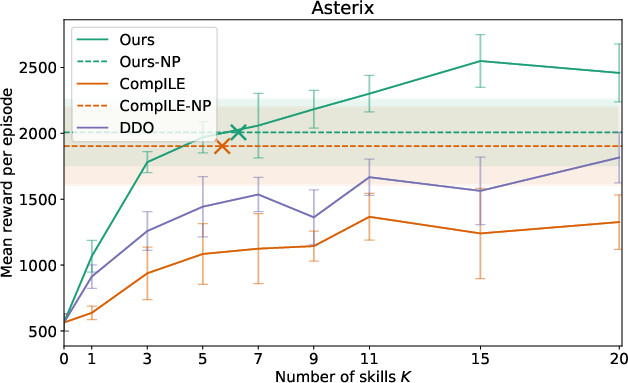
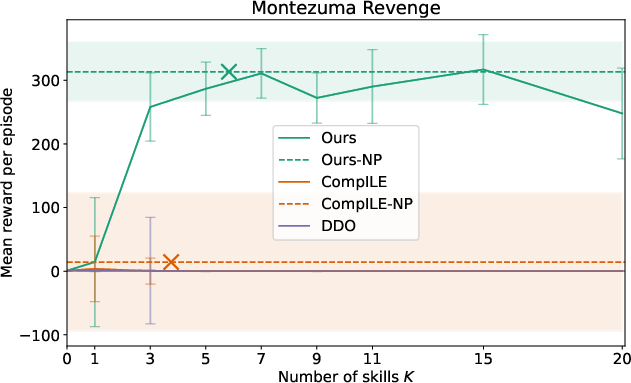
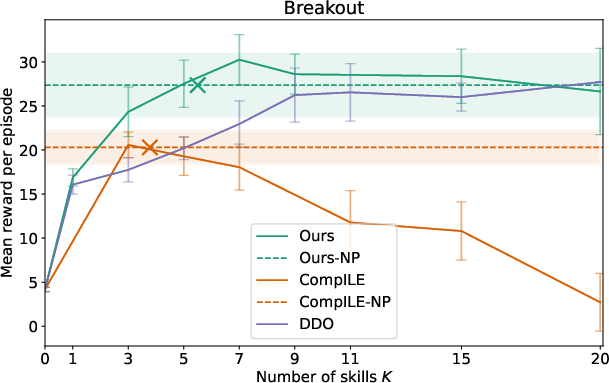
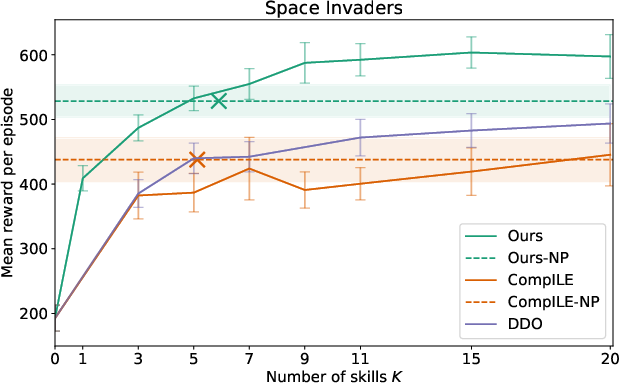
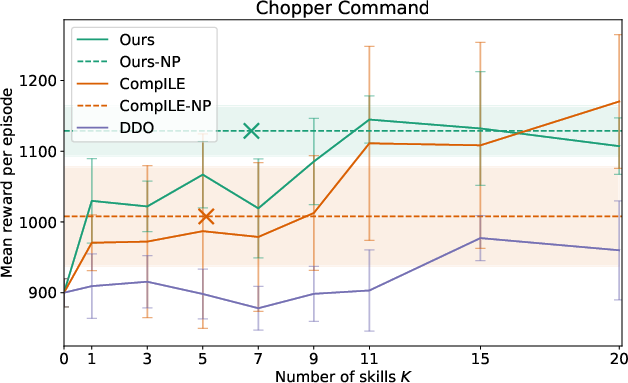
Figure 2: Results for Atari environments highlighting the competitiveness of the nonparametric model against fixed K baselines.
Conclusion
The paper presents an effective strategy for skill discovery employing a Bayesian nonparametric framework, which leads to a flexible and adaptive learning system that can dynamically adjust to complex environments. By eliminating the requirement to preset the number of skills, the method reduces the burden of hyperparameter tuning and adapts naturally to varying tasks. This work opens avenues for extending nonparametric techniques in hierarchical reinforcement learning settings, promoting the development of more generalized and autonomous systems.
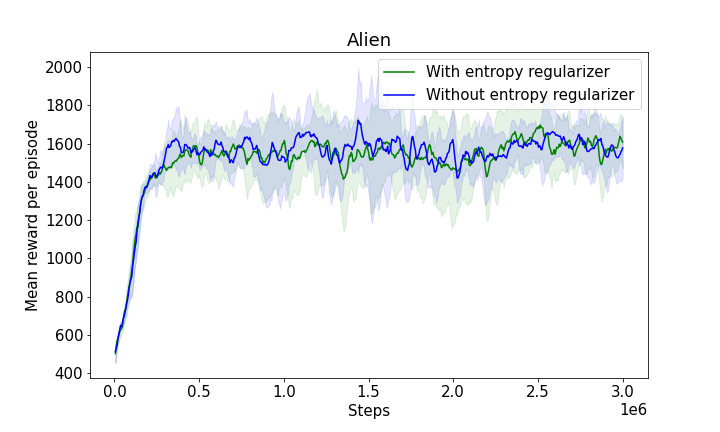
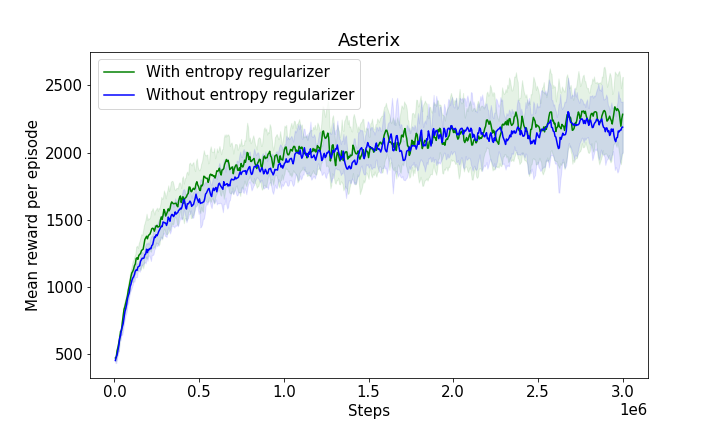
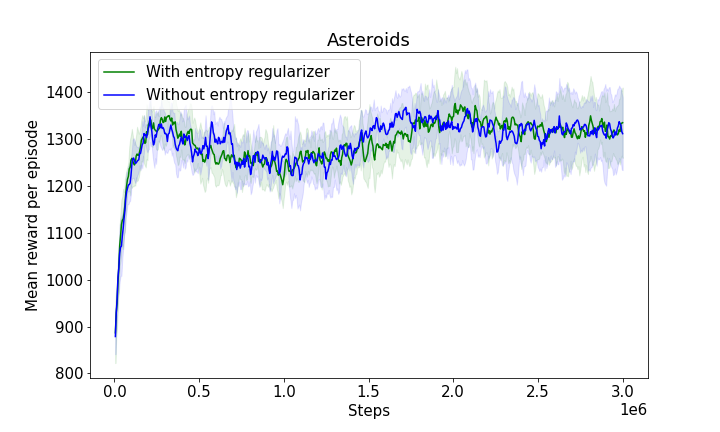
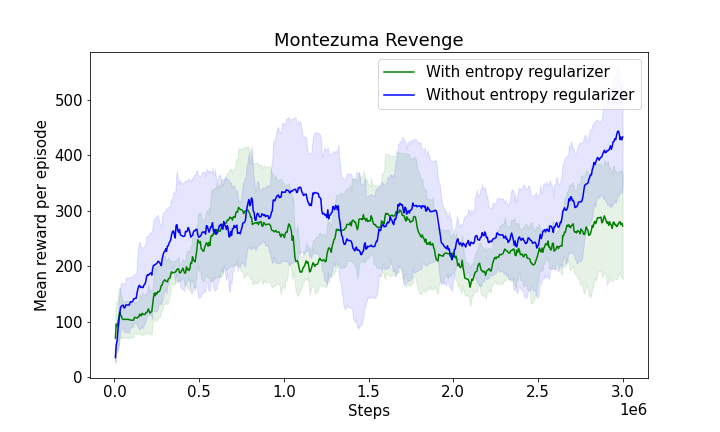
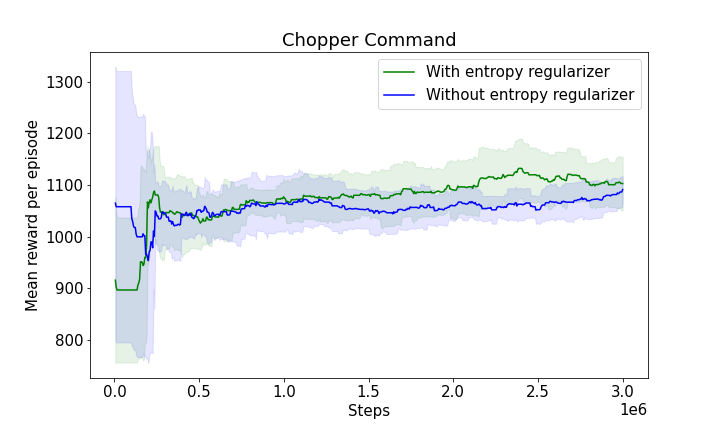
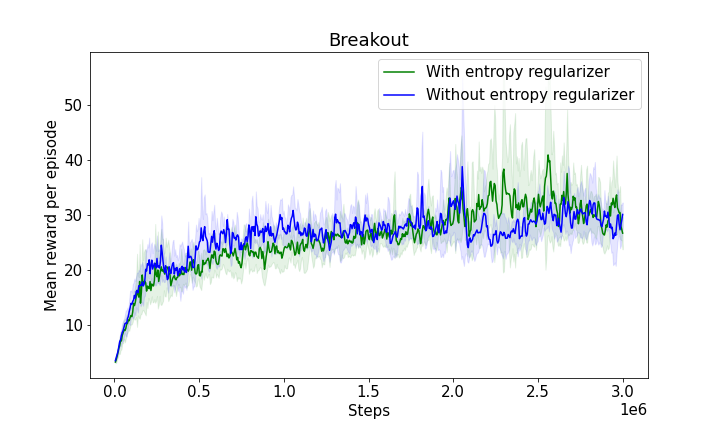
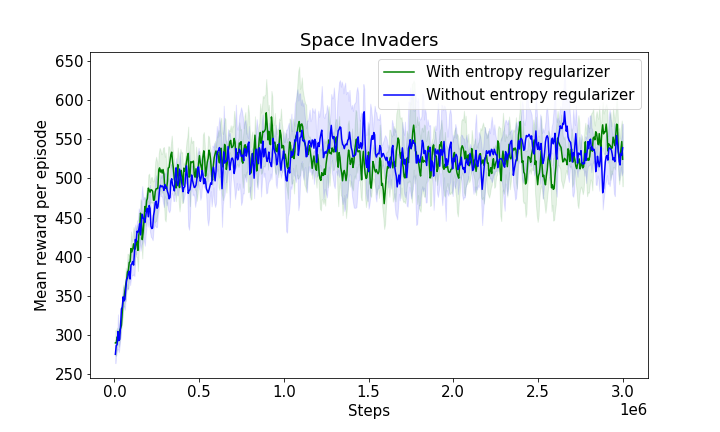
Figure 3: The progression of mean rewards illustrating learning efficiency with and without entropy regularizers, showcasing the robustness and adaptability of the model.