- The paper shows that structured pruning of inner U-Net layers achieves aggressive compression (50–75% filter removal) with minimal impact on FID.
- It leverages detailed layer-wise sensitivity analysis to target redundant filters, resulting in over 7× parameter reduction without compromising quality.
- Empirical results on Pix2Pix and Wav2Lip demonstrate that focusing on inner layers maintains fidelity and efficiency, outperforming global pruning methods.
Structured Pruning for U-Net GAN Generators: A Sensitivity-driven Approach
Introduction
This work presents a systematic investigation into structured pruning for U-Net-based generative adversarial networks, focusing on conditional GAN settings (Pix2Pix and Wav2Lip). Contrasting with the extensive literature on pruning discriminative models, the analysis here targets generative architectures, executing a layer-wise sensitivity study to reveal the prunability profile of U-Net generators. The primary claim, supported by comprehensive empirical evidence, is that the innermost layers of the U-Net generator contain a substantial number of filters that can be excised with negligible, or even positive, impact on generation quality. The paper establishes both filter-level and layer-level structured pruning methods driven by these insights and demonstrates superior performance to global pruning strategies which do not leverage the U-Net's structural idiosyncrasies.
U-Net Prunability: Sensitivity Analysis
A rigorous per-layer pruning sensitivity analysis is conducted, measuring the impact on FID for progressively higher pruning ratios for each layer.
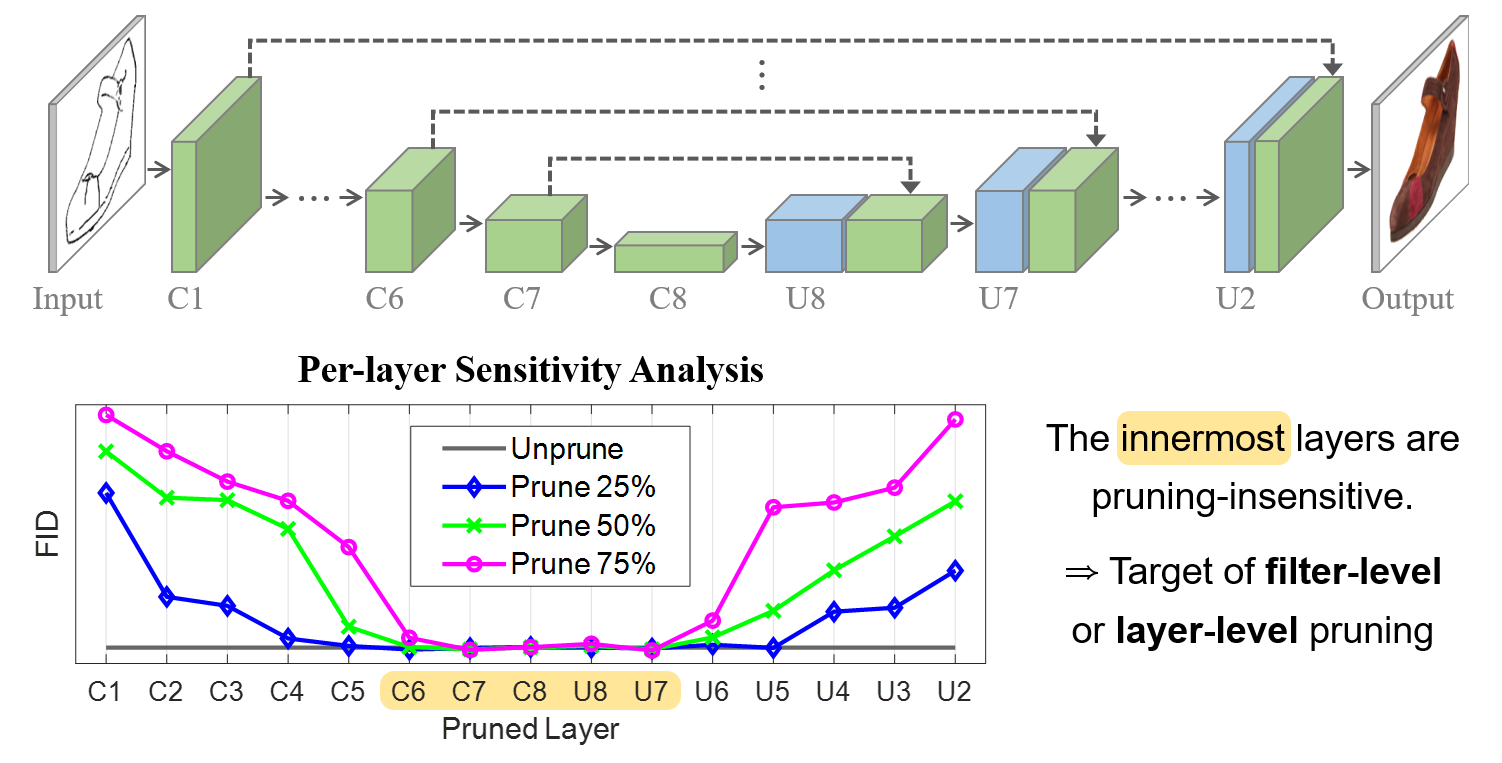
Figure 1: U-Net generator architecture and per-layer pruning sensitivity analysis, showing substantial redundancy in innermost filters.
Results elucidate a pronounced "U-shaped" sensitivity: the deep (bottleneck-proximal) layers are highly insensitive to pruning, tolerating removal of up to 75% of filters with minimal degradation in FID. In contrast, the outer layers—especially those linked by skip connections—demonstrate strong dependence, and even modest pruning here yields significant performance penalties.
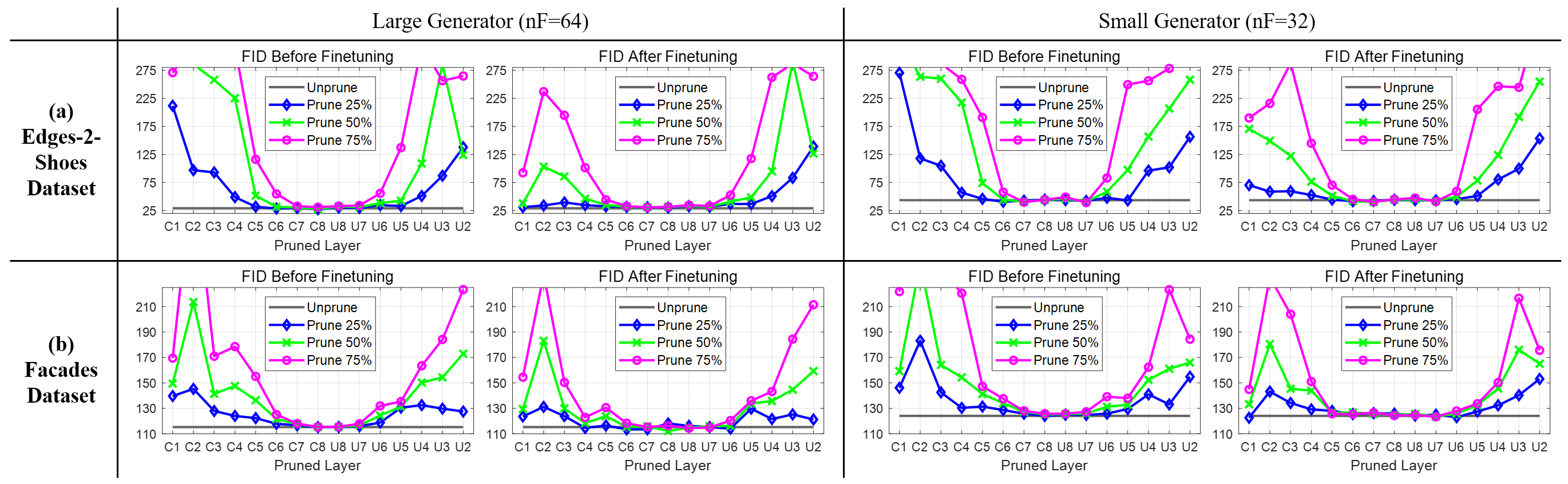
Figure 3: Layer-wise sensitivity analysis for Pix2Pix on Edges2Shoes and Facades shows robust prunability in inner layers.
Theoretical implication: the U-Net generator allocates representational burden for low-level feature fidelity in the large, skip-connected lateral paths, relegating the innermost dense mappings primarily to high-level, compressible representations. This behavior is observed consistently across datasets (Edges2Shoes, Facades) and generator capacities.
Structured Pruning Strategies
Filter-level Pruning
Based on the sensitivity analysis, the method applies structured pruning by removing a fixed (e.g., 50–75%) fraction of filters across the innermost (e.g., C6–C8, U7–U8) convolutional layers. Pruned generators are then finetuned with joint optimization of the discriminator, preserving the adversarial equilibrium.
Layer-level Pruning
As an alternative strategy, entire inner layers are excised, yielding an expanded bottleneck feature map (e.g., from 1×1 to 2×2 or 4×4), with symmetric removal in both encoder and decoder paths.
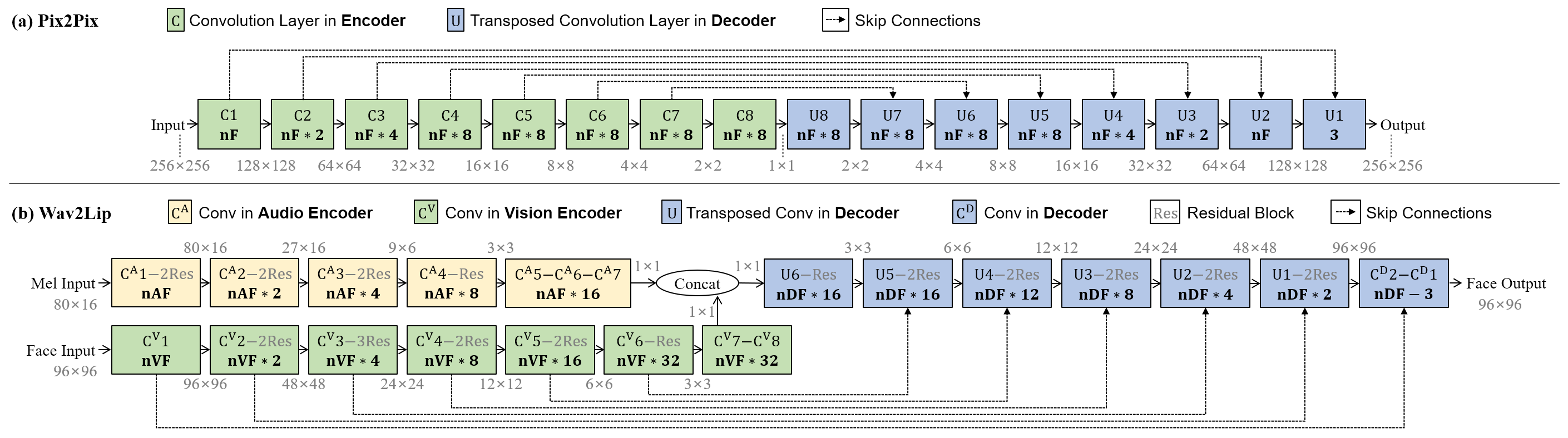
Figure 2: Comparison of Pix2Pix and Wav2Lip U-Net generator architectures with layer indexing.
Both approaches rely critically on architecture-aware selection of pruning locations rather than the layer-invariant (global) pruning applied in prior work.
Empirical Evaluation
Pix2Pix: Image-to-Image Translation
Empirical results on Edges2Shoes and Facades demonstrate that global pruning (Uniform and LAMP-based) quickly deteriorates performance, while structured pruning based on sensitivity analysis achieves substantial reduction in model complexity with maintained or even improved FID. For the Edges2Shoes dataset, removing 50% of filters in C6–C8 and U7–U8 yields nearly constant FID relative to the original. Notably, selective layer-level removal (e.g., C8, U8) leads to competitive or superior FID, with a significant parameter and MAC reduction.
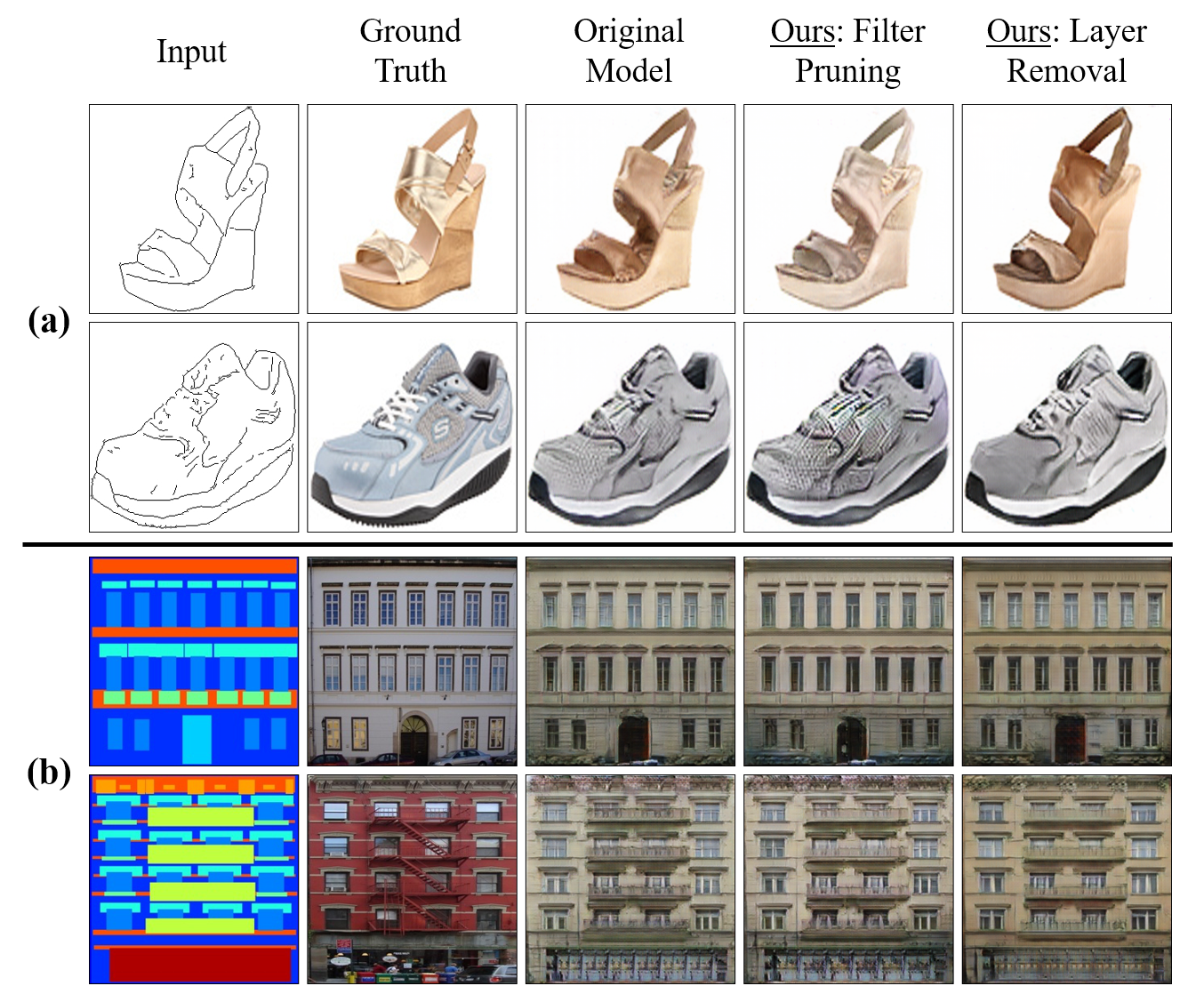
Figure 4: Visual outputs of Pix2Pix on Edges2Shoes and Facades datasets with original and pruned generators.
Wav2Lip: Speech-driven Talking Face Generation
A similar protocol is followed for Wav2Lip, targeting deep layers of both vision and audio encoders and the decoder. The structured pruning achieves >7× parameter reduction with almost no degradation in FID, LSE-D, or LSE-C, and effectively maintains perceptual lip sync quality, unlike global pruning baselines which induce sharp artifacting beyond moderate sparsity levels.
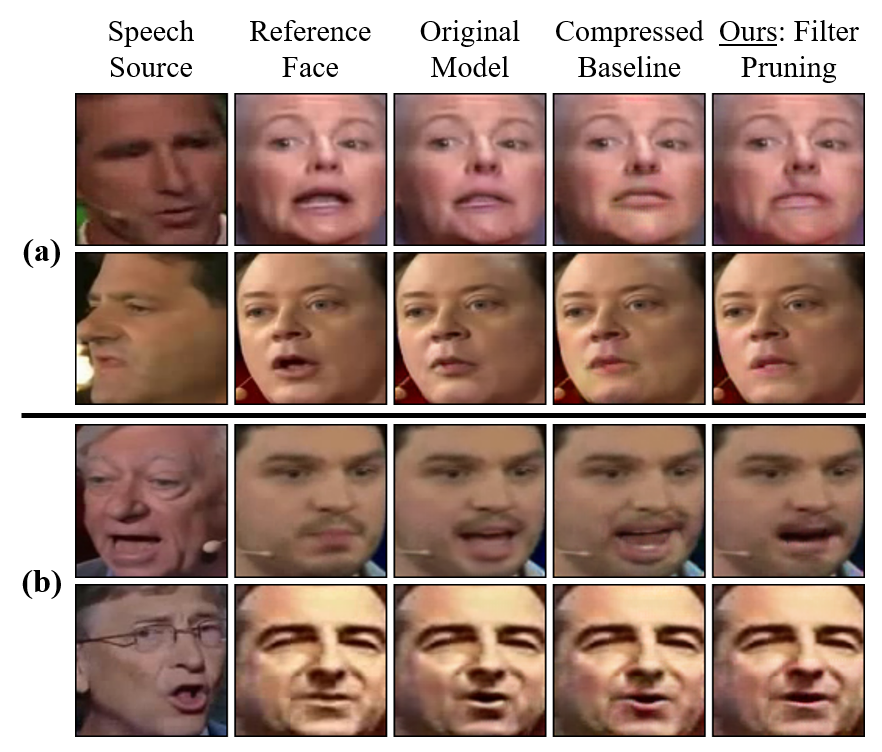
Figure 5: Visual examples from Wav2Lip showing consistent mouth dynamics in pruned models.
Fidelity and Diversity
Recent generative model metrics are applied: Kynkaanniemi precision and recall distinguish fidelity and diversity. Pruning outer layers disproportionately degrades both, while aggressive pruning of inner layers sustains fidelity and only marginally impacts diversity, confirming the functional segregation of U-Net's inner and outer representational pipelines.

Figure 6: Pruning sensitivity on fidelity/diversity metrics: inner layers exhibit resilience to pruning.
Pruning Criteria
Comparison of criterion: L2-norm magnitude and geometric median both validate the main finding. The redundancy-based criterion (geometric median) identifies similar prunability in inner layers.
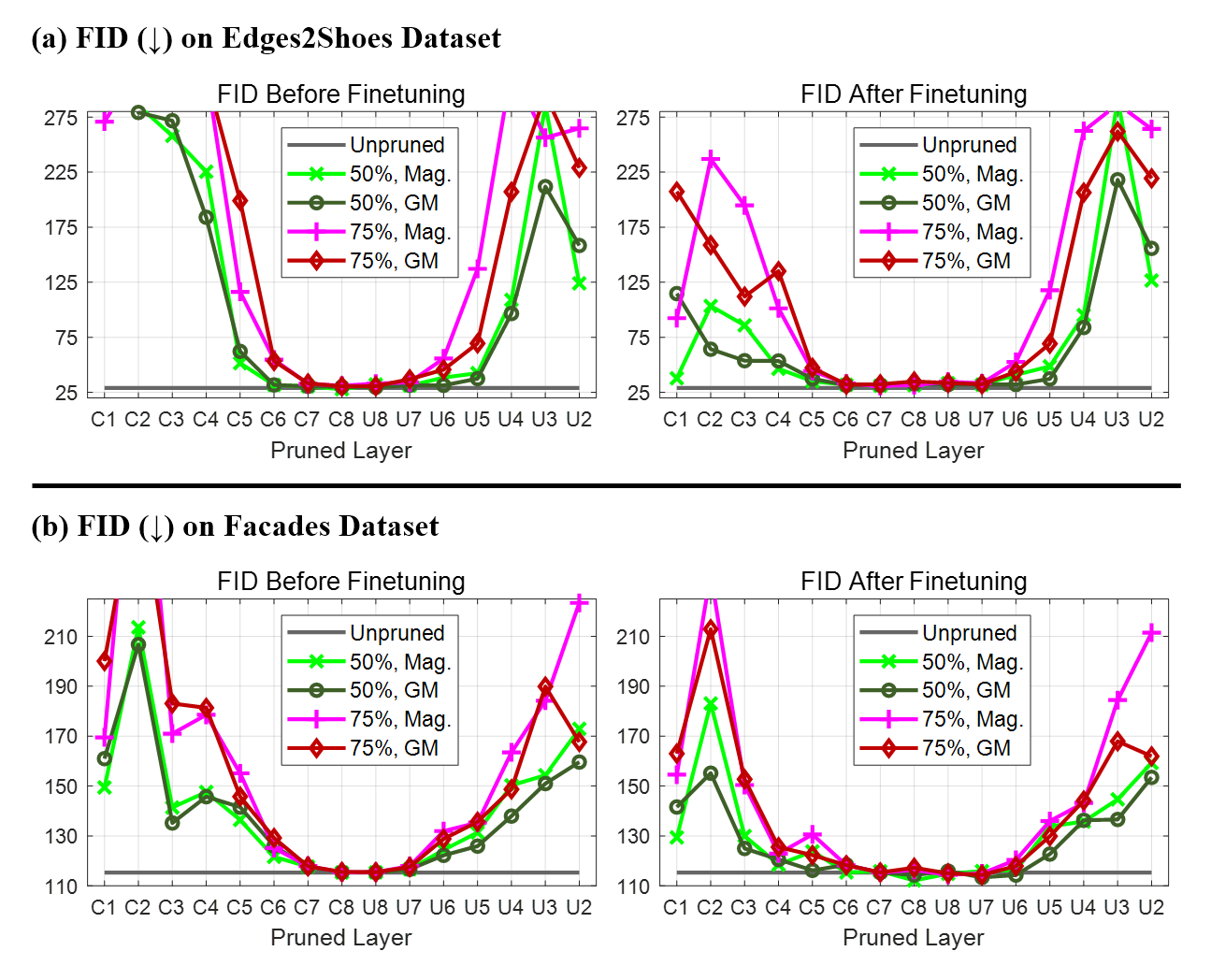
Figure 7: Evaluation of different pruning metrics (magnitude, geometric median) reveal congruent prunability profiles.
Retraining Protocols and Implementation Insights
Retraining with joint finetuning of both pruned generator and pretrained discriminator outperforms both random reinitialization and finetuning with a frozen discriminator. This protocol is critical for maintaining adversarial balance after structured pruning.
Implications and Future Directions
These findings challenge the conventional uniform or sensitivity-agnostic pruning practices for generative models. By exploiting the architectural bias in U-Net's function allocation, model compression can be achieved without sacrificing sample quality, and sometimes yielding positive regularization effects. This empirical observation suggests that future work on GAN architecture design—especially for mobile and edge applications—should focus on bottleneck sparsification and potentially dynamic reallocation of capacity toward outer, skip-connected paths.
Integrating structured pruning with KD and advanced quantization techniques is a natural extension, presenting an avenue for even more aggressive compression. Moreover, understanding the effect of pruning on generator-induced distribution support (e.g., diversity) remains an important open problem.
Conclusion
This study establishes that the innermost layers of U-Net generators, in conditional GANs, are highly redundant and can be structuredly pruned with minimal impact on sample quality. Sensitivity-guided pruning strategies, both at the filter and layer level, consistently outperform architecture-agnostic (global) baselines across tasks. These results endorse architecture-aware model compression as essential for deploying efficient generative models, and motivate further research on adaptive compression protocols for structured generative architectures.
Reference: "Cut Inner Layers: A Structured Pruning Strategy for Efficient U-Net GANs" (2206.14658).