- The paper demonstrates that transformer-based Wav2Vec2 reliably extracts speech and pause features, showing high concordance with manual assessments.
- It compares Gaussian mixture/HMM-based approaches with Wav2Vec2, revealing that audio quality significantly impacts feature extraction accuracy.
- The study highlights the potential for automated speech assessment in ALS to enable efficient remote monitoring and clinical intervention.
Concurrent Validity of Automatic Speech and Pause Measures During Passage Reading in ALS
Introduction
The study "Concurrent Validity of Automatic Speech and Pause Measures During Passage Reading in ALS" explores the deployment of automatic feature extraction techniques in evaluating speech and pause metrics in individuals suffering from Amyotrophic Lateral Sclerosis (ALS). Given the neurodegenerative nature of ALS and its profound impact on speech, this research addresses the inefficiency of current manual or semi-automatic speech assessment tools. The study leverages advanced speech-text alignment algorithms employing transformer-based models, presented as a potential automation to replace laborious conventional methods.
Methodology
The study was conducted on 646 audio samples from ALS patients and control subjects. The analysis focused on two computational models: a Gaussian mixture/hidden Markov model (GMM/HMM) as implemented in the Montreal Forced Aligner (MFA), and a transformer-based Wav2Vec2 model. Both models executed forced alignment for speech and pause feature extraction. A total of eight features were extracted, including pause duration, speech duration, and total duration. Validation was performed against the semi-automated Speech and Pause Analysis (SPA) software, assessing correlation across various subsets of audio quality and ALS severity.
Results
The transformer-based Wav2Vec2 model demonstrated superior performance in feature extraction accuracy compared to the gold-standard SPA software. Notably, the agreement of features like pause and speech duration with SPA outputs was robust across quality variants of audio samples, with the strongest correlations observed in high-quality recordings. This is evident in the Bland–Altman plots which articulate the close agreement of these parameters within acceptable limits (Figure 1).
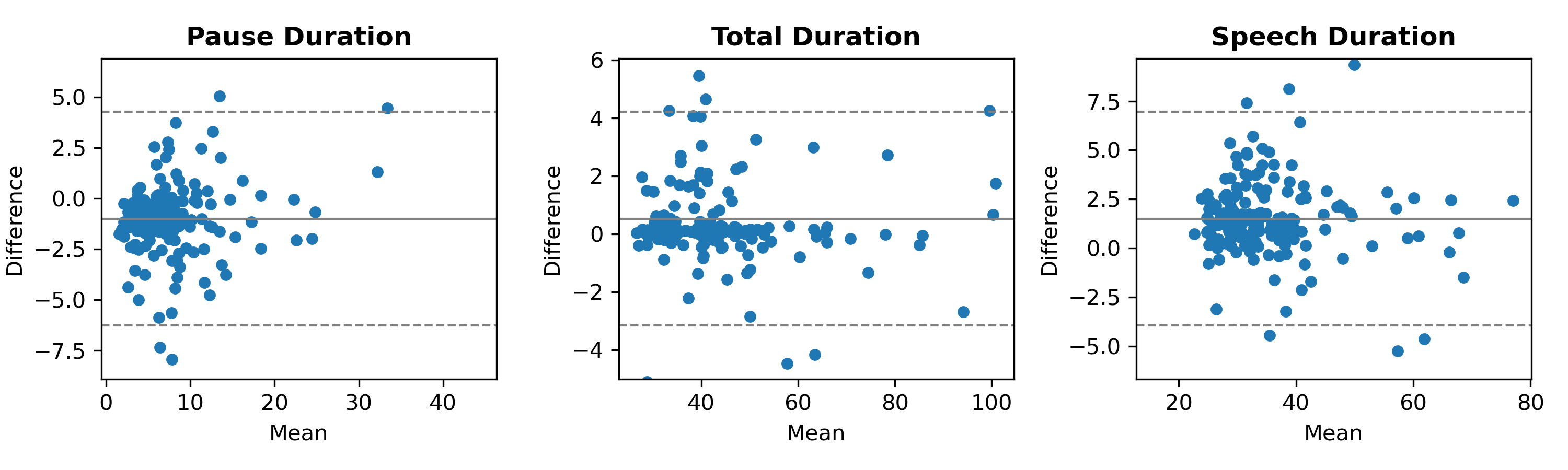
Figure 1: The Bland-Altman plots between Wav2Vec2 and SPA features of pause duration, speech duration, and total duration on Good audio quality data. The dashed lines indicate the limits of agreement.
Discussion
These findings suggest a promising shift towards automated assessment using transformer-based models, particularly the Wav2Vec2, as they offer consistent performance regardless of disease severity. However, the sensitivity to audio quality suggests a need for higher quality data acquisition in clinical settings. The adaptation to utilize high-performing models like transformers highlights a path forward for remote and efficient ALS symptom tracking, marking significant potential for intervention and management strategies in home environments.
The study acknowledges limitations due to variance in audio sample quality and suggests further research into adaptive algorithms that can mitigate these variations. Future work could expand beyond ALS to encompass other neurodegenerative diseases affecting speech, such as Parkinson's disease and post-stroke conditions, further enhancing the generalizability of the findings.
Conclusion
This research underscores the viability of transformer-based automatic speech alignment in extracting reliable speech measures in ALS patients. The Wav2Vec2 model, in particular, demonstrates high validity against established methods, emphasizing the critical need for precise audio input. This advancement could ultimately revolutionize the landscape of clinical assessment tools, facilitating more accessible diagnostic and progression-monitoring methodologies for speech impairments arising from neurodegenerative disorders.