- The paper demonstrates that text-to-image diffusion models can act as effective zero-shot classifiers by leveraging the denoising diffusion process.
- It introduces methodologies like shared noise and dynamic class pruning to reduce computational costs while preserving competitive accuracy.
- Results reveal that these models rival or exceed CLIP in handling conflicting visual cues and attribute binding, despite practical deployment challenges.
Text-to-Image Diffusion Models as Zero-Shot Classifiers
This essay provides an expert overview of "Text-to-Image Diffusion Models are Zero-Shot Classifiers" (2303.15233), which explores the application of text-to-image diffusion models as zero-shot classifiers. The paper investigates diffusion models' ability to generalize to downstream tasks beyond generation, arguing for generative pre-training as a viable alternative for vision-language tasks.
Introduction and Problem Statement
The recent progress in large pre-trained models, such as transformers in NLP and contrastive learning models for vision, has sparked interest in exploring generative pre-training for visual tasks. This paper examines the potential of text-to-image diffusion models, like Imagen and Stable Diffusion, as zero-shot classifiers. The central question is whether these models' generative capabilities correspond to an ability to perform well on classification tasks without additional training.
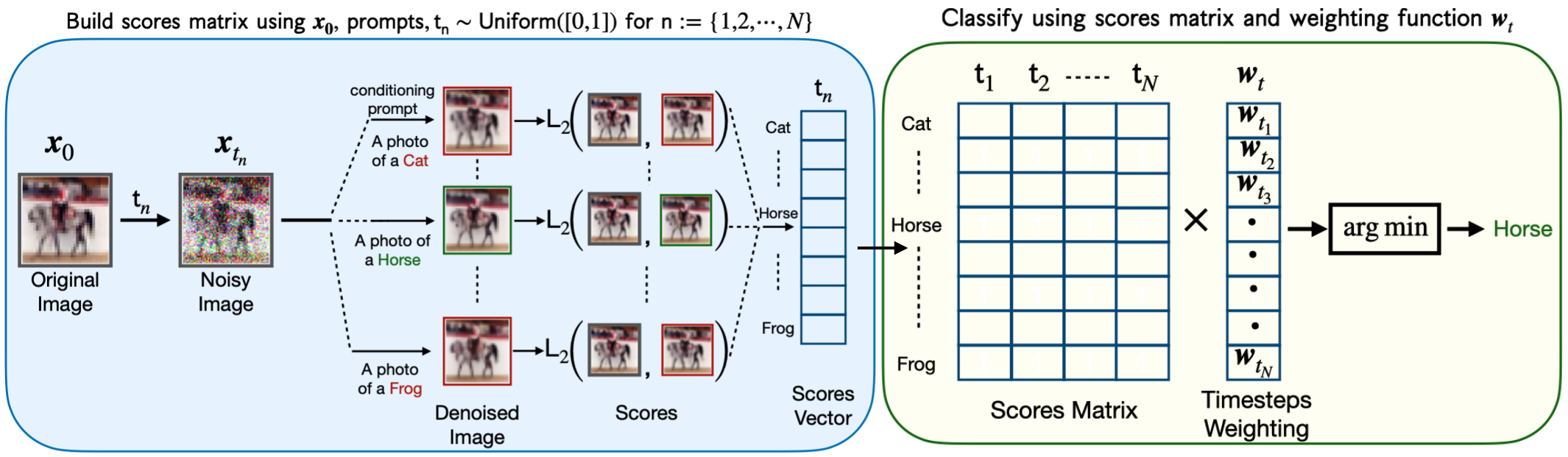
Methodology: Tuning Generative Models for Classification
The approach applies the denoising diffusion process in diffusion models as a proxy for classification likelihood, a novel perspective for leveraging these models. By noising an image and denoising it conditioned on text prompts for candidate classes, the model evaluates which class prompt results in the best restoration of the original image. Key methodological improvements include:
Experimental Setup and Results
The experiments conducted demonstrate compelling results across several benchmarks:
- Image Classification: Imagen and Stable Diffusion show comparable accuracy to CLIP on various datasets, with especially strong performance observed in lower resolution datasets and tasks requiring text recognition.
- Robustness to Conflicting Cues: Both Imagen and Stable Diffusion outperform contemporary models like CLIP and ViT-22B in handling images with conflicting texture and shape cues, as analyzed using the Cue-Conflict dataset.

Figure 2: Example predictions from Imagen when denoising the same image with different text prompts. Each set of images shows the original, noised, and denoised images for the two classes. The top two rows use ImageNet images and the bottom row uses Cue-Conflict.
Analysis of Results
Limitations and Computational Challenges
While diffusion models were competitive, their use as classifiers remains impractical for large-scale deployment due to computational demands. Significant resources are needed to denoise multiple samples per class, requiring efficiency strategies such as shared noise and adaptive class pruning.
Attribute Binding and Compositional Generalization
The evaluation of attribute binding tasks using synthetic datasets highlights an area where diffusion models excel compared to contrastive methods like CLIP. Their ability to bind attributes, demonstrated in tasks that require compositional generalization, suggests advantages inherent in the way generative models integrate multiple concepts.

Figure 3: Examples of the synthetic-data attribute binding tasks. We explored more sophisticated prompts than in the figure (e.g., ``A blender rendering of two objects, one of which is a yellow sphere."), but they didn't substantially change results.
Conclusion and Future Directions
Text-to-image diffusion models show promise beyond image generation, particularly in zero-shot classification. Their competitive performance with established models and robustness to texture-shape conflicts suggest untapped potential in generative pre-training for vision tasks. However, practical deployment necessitates addressing computational inefficiencies. Future work could explore fine-tuning diffusion models for specific tasks, scaling laws comparisons, and further evaluation on diverse manipulations to fully understand their capabilities in compositional tasks.