- The paper introduces STI-KNN, a novel algorithm that reduces computational complexity for pair-interaction Shapley value calculations from O(2^n) to O(t n^2) in KNN models.
- It leverages sorted training data and recursive updates to efficiently compute interaction values across diverse dataset conditions, including balanced and mislabeled data.
- The methodology advances data valuation by improving scalability and providing actionable insights for dataset quality and explainable AI applications.
Optimizing Data Shapley Interaction Calculation for KNN Models
The paper "Optimizing Data Shapley Interaction Calculation from O(2n) to O(tn2) for KNN models" presents an innovative algorithm called "STI-KNN". This algorithm significantly improves the computational efficiency of calculating exact pair-interaction Shapley values for KNN models, reducing complexity from O(2n) to O(tn2). The implications and applications of this research are discussed, focusing on its practical benefits and theoretical contributions. This essay explores the core concepts, implementation, and potential impacts.
Introduction to Data Valuation and Shapley Values
In the expanding field of AI, accurately valuating each training data point's contribution is critical for tasks such as dataset summarization, acquisition, and removing outliers. Shapley values offer a principled method for quantifying these contributions by considering every possible subset of data points, albeit with high computational costs historically pegged at O(2n). This paper proposes an optimized approach for KNN models, focusing on efficient data valuation.
Methodology: Understanding STI-KNN
The STI-KNN algorithm calculates pair-interaction Shapley values with a reduced computational burden. It leverages the properties of KNN models where data points are evaluated based on their closeness to a given test point, simplifying the overall calculation process.
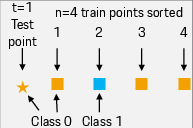
Figure 1: Example of a simple dataset to explain the test score calculation for KNN model.
Key steps in the algorithm include:
- Sorting: Train points are sorted based on their distance to a test point.
- Recursive Calculation: Pair-interaction values are computed recursively, leveraging the consistency in nearest-neighbor rankings.
- Efficiency: By averaging results over multiple test points, STI-KNN efficiently captures interaction terms across large datasets.
Implementation and Complexity Analysis
STI-KNN operates in O(tn2), where t is the size of the test set and n is the size of the training set. This improvement makes it feasible to apply Shapley-based valuations in real-world, large-scale datasets.
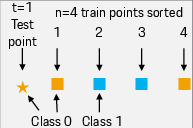
Figure 2: Example of a simple dataset to explain a pair interaction between train data points.
The algorithm’s steps are outlined in pseudocode, offering a clear path for implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def sti_knn(training_data, test_data, k):
# Initialize variables
pair_interactions = np.zeros((len(training_data), len(training_data)))
# Iterate over test points
for test_point in test_data:
# Sort training points by distance to test_point
sorted_indices = sort_by_distance(training_data, test_point)
# Recursively calculate interactions
for j in range(len(training_data)-1, k, -1):
update_interactions(sorted_indices, j, pair_interactions, k)
return pair_interactions / len(test_data) |
This pseudocode provides the foundation for implementing STI-KNN, demonstrating its scalability and applicability to diverse datasets.
Interaction Analysis
Through empirical examples, the study highlights interaction patterns such as:
- Balanced vs. Unbalanced Datasets: The algorithm reveals how data redundancy affects interaction values.
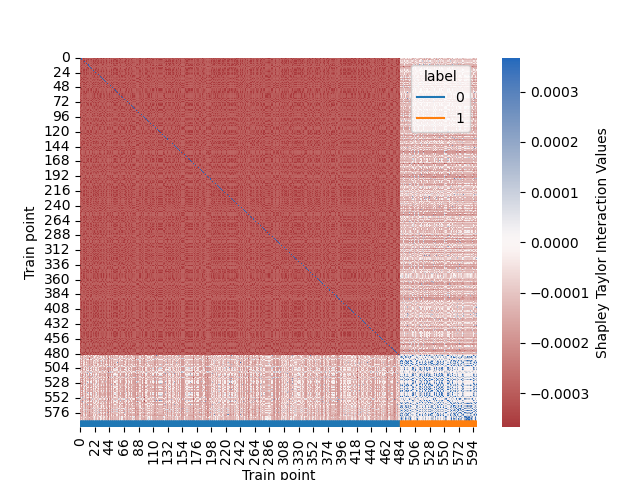
Figure 3: Example of interaction with a balanced dataset.
- Mislabeled Data: Points labeled incorrectly exhibit distinct interaction behaviors, identifying potential errors in the dataset.
(Figure 4 and 5)
Figure 4: Example of interaction with an unbalanced dataset.
Figure 5: Example of interaction with mislabeled training points.
These analyses underscore STI-KNN's utility in diagnosing and improving dataset quality by highlighting underlying interaction effects.
Discussion and Future Work
STI-KNN not only accelerates data valuation calculations but lays the groundwork for integrating interaction terms in model explainability. The paper's results suggest that Shapley values can inform strategies in data cleaning, model training, and decision-making across AI applications.
Future research might explore adapting this approach to other models beyond KNN, further enhancing the practicality of Shapley values in AI. Additionally, investigating the utility of these interaction insights in frameworks for explainable AI could lead to improvements in AI transparency and trustworthiness.
Conclusion
The optimization of Shapley interaction calculations in KNN models through STI-KNN represents a substantial step forward in efficiently valuing training data points. By drastically reducing computational complexity, the paper enhances the applicability of Shapley values in real-world AI scenarios, offering valuable insights for both practitioners and researchers in data science and machine learning.