RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Abstract: LLM applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping engineers quickly find the “root cause” of problems in big cloud systems (like the services that run apps and websites). The authors built a smart assistant called RCAgent that uses a LLM plus special tools to act like a careful, step-by-step detective. It looks at different kinds of data (like logs and code), decides what to do next, and produces clear explanations and fixes—without sending any private data to outside services.
Key Objectives
In simple terms, the paper aims to:
- Create a privacy-safe, practical AI “agent” that can investigate cloud problems on its own.
- Give the agent tools and techniques so it can handle messy, very long data (like huge logs).
- Improve the agent’s stability (so it doesn’t make silly mistakes) and accuracy (so its conclusions are more trustworthy).
- Show that this agent works better than older methods on real-world cloud issues.
How Did They Do It?
Think of RCAgent as a detective with a toolbox and a plan:
The Agent’s Detective Loop
The agent works in a loop:
- Think: Plan what to do next.
- Act: Use a tool (like “get logs for this job” or “analyze this code”).
- Observe: Read the tool’s results.
- Repeat until ready to report.
This is called a “thought–action–observation” loop. It helps the agent explore carefully.
Privacy-Friendly Model
Instead of using powerful online models (like GPT) that might send data outside the company, RCAgent runs on a local model (Vicuna) within the company. This protects sensitive cloud data.
Smart Tools the Agent Uses
- Information-gathering tools: Simple buttons like “fetch logs for this job ID” so the agent doesn’t need to write complex queries. This reduces mistakes.
- Expert analysis tools:
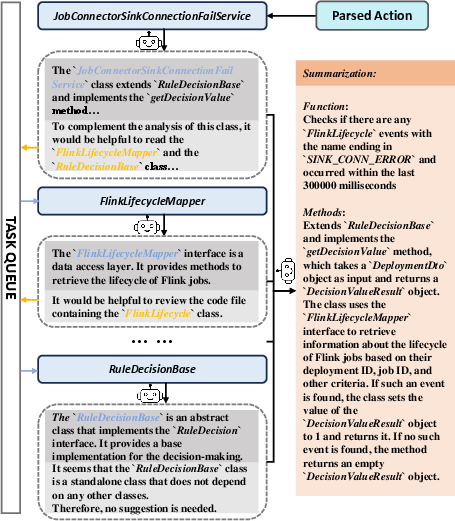
- Code analysis tool: Reads code files, suggests related files to check, and builds a summary. Imagine reading a chapter, then checking the references it mentions.
- Log analysis tool: Splits long logs into meaningful chunks using text similarity (like grouping related messages together), then analyzes each chunk and extracts exact evidence from the logs. This reduces “made-up” conclusions.
Handling Very Long Data: Observation Snapshot Key (OBSK)
Logs and results can be huge. RCAgent shows the agent only the “head” (a short preview) and attaches a “snapshot key” (like a label for the full data). When the agent needs details, it uses the key to fetch the full content. Think of it like using an index card number to pull the right book from a library.
Keeping Actions Valid: Stabilization
Sometimes the agent’s output format can be messy. Two fixes help:
- JSON Repairing (JsonRegen): If the agent’s structured output (like a form) is broken, it is cleaned and regenerated so tools can read it.
- Error Handling: If the agent repeats the same action, gives trivial inputs, or tries to finish too early, it gets helpful error messages to steer it back.
Making Results More Reliable: Self-Consistency
The agent samples multiple versions of its final answers and then:
- Either “votes” using embeddings (picks the answer closest to the others in meaning),
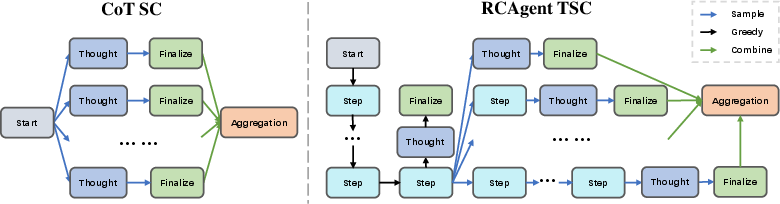
- Or asks the LLM to combine them into a better summary. A special version called Trajectory-level Self-Consistency (TSC) only samples near the end of the investigation. This saves time and keeps early steps stable.
Main Findings and Why They Matter
RCAgent beat the older agent method (called ReAct) across the board:
- It found root causes, suggested solutions, and listed evidence more accurately and helpfully.
- It stayed stable: far fewer invalid actions and errors.
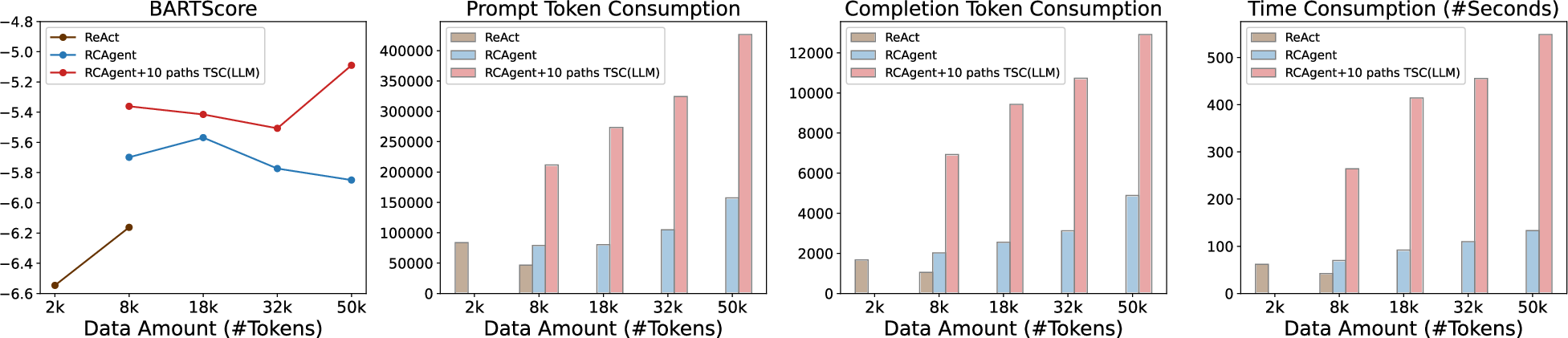
- Its results improved further when using Self-Consistency (especially the TSC method).
- Human experts judged it more helpful on “hard” real-world problems that existing rules couldn’t handle.
- It scaled well: when data got bigger, it still performed strongly, and its computing cost grew roughly in a predictable, linear way.
The agent is already used in Alibaba Cloud’s real-time platform for Apache Flink, helping diagnose stream processing jobs (these are programs that process data as it comes in). It flags issues and even suggests which team is responsible (like platform vs. user), making support work faster.
Implications and Impact
In short:
- For cloud companies: RCAgent shows that an AI agent can safely and effectively investigate real problems without sending sensitive data outside.
- For engineers: It cuts down time spent digging through huge logs and code, and it produces clearer, more trustworthy reports with evidence.
- For research: It proves tool-using AI agents can work in noisy, complex environments, not just simple demos. The techniques (like OBSK, error handling, and TSC) can inspire better agents in other fields.
If you imagine cloud problem-solving as a tough mystery, RCAgent is a careful detective with a strong plan, good tools, and a habit of double-checking itself—making it more likely to crack the case quickly and correctly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Privacy guarantees and threat modeling are not formalized: no explicit privacy threat model, attack surface analysis, or empirical assessment of data leakage risks (e.g., model memorization, PII exposure) under internal deployment; lacks evaluation of mitigation techniques (differential privacy, redaction, access control auditing).
- Generalization beyond Alibaba Cloud’s Flink platform remains untested: no cross-cloud/system validation (e.g., AWS Kinesis, Azure Stream Analytics, Kubernetes/Airflow), cross-product RCA domains (batch pipelines, microservices, storage/DB incidents), or multi-tenant contexts.
- Dataset limitations and potential selection bias: offline evaluation reduces 15,616 anomalies to 161 jobs with class-balance constraints; lacks analysis of selection bias, representativeness of failure modes, and how results shift with larger, more diverse samples.
- Causal correctness is not directly measured: RCA is evaluated via semantic similarity and LLM judges, but causality (did the model identify the true root cause?) is not validated via ground-truth incident graphs, controlled interventions, or counterfactual tests.
- Human evaluation lacks rigor and breadth: H-Helpfulness uses Likert scales without reporting inter-rater reliability (e.g., Cohen’s kappa), calibration criteria, or blinded review; responsibility determination is reported only as precision (recall/F1 missing).
- Real-world impact on operational KPIs is unquantified: no measurements of MTTR reduction, alert fatigue, false-positive/false-negative rates, or SLA breach avoidance attributable to RCAgent in sustained production use.
- Latency, throughput, and concurrency constraints are underreported: absence of per-job analysis latency, end-to-end decision loop timings, concurrent job handling capacity, and queueing/backpressure behavior under peak loads.
- Tool coverage and maintainability are unclear: semantically minimalist tools improve stability but coverage adequacy (across data sources, modalities) and maintainability (version drift, schema changes) are not evaluated; lacks dynamic tool discovery or adaptive tool selection.
- OBSK (Observation Snapshot Key) design lacks sensitivity analysis: no ablation on snapshot head length, hash/key collision handling, retrieval latency, consistency under updates, cache eviction policies, or comparison to vector-store memory systems.
- JSON repairing (JsonRegen) is ad hoc and unevaluated: no quantitative success/failure rates, robustness under adversarial/long inputs, fidelity checks (content drift during YAML→JSON regeneration), or comparisons to grammar-constrained decoding (CFG, JSON schemas).
- Error-handling heuristics cover limited classes of errors: duplicate tool calls, trivial inputs, and early finalization are handled, but subtle reasoning errors (misattribution, evidence mislinking, incorrect tool choice) and recovery strategies are not systematically detected or benchmarked.
- Self-Consistency (TSC) only samples at finalization: open questions on earlier or multi-branch sampling (e.g., Tree-of-Thought, MCTS), diversity encouragement (temperature/top-k schedules), cost-quality tradeoffs at different sample sizes, and robustness across anomaly types.
- Log analysis tool hyperparameters and method sensitivity are unexplored: window size (≤200 lines), exponential decay rate, Louvain clustering quality, multilingual logs, timestamp-aware partitioning, and comparisons to log parsers (e.g., Drain, Spell), traditional sequence models, or structured parsing are missing.
- Code analysis tool scalability and correctness are untested: limited details on handling large repos, call graph construction, versioning/branch selection, mapping log evidence to code paths, integration with static analysis (e.g., SAST), and empirical accuracy of its class recommendation loop.
- Missing modalities for RCA: current tools focus on logs, DB history, and code repositories, but do not incorporate metrics, traces (distributed tracing), configs, change events/deployments, time-series anomalies, or topology dependency graphs—key sources for robust RCA.
- Baselines are narrow: lacks comparison with alternative agent frameworks (Plan-and-Execute, Reflexion, Tree-of-Thought, ToolFormer-style training), stronger local models (e.g., LLaMA 70B), and domain-tuned RAG pipelines; no head-to-head benchmarking under identical data constraints.
- Safety and permissions for tool invocation are not formalized: no sandboxing, policy enforcement, or audit trails documented; unclear how to prevent destructive actions if write/exec tools are added in future.
- Robustness to distribution shifts and long-term drift is not evaluated: no longitudinal assessment under evolving system versions, changing log formats, new failure patterns, or tool schema changes; lacks mechanisms for continuous learning/feedback incorporation.
- Internationalization and domain terminology coverage are unaddressed: logs may contain mixed languages or specialized jargon; model performance across multilingual inputs and domain-specific lexicon normalization is not assessed.
- Explanation faithfulness and evidence attribution are partially addressed: while evidence copying is enforced, there’s no quantitative faithfulness metric (e.g., attribution scoring) or tests for spurious correlations; limited analysis of how evidence supports causal claims.
- Failure mode taxonomy is missing: lacks systematic error analysis identifying common failure categories (e.g., misclassification of root cause families, overreliance on noisy log segments, code-tool misalignment) and targeted mitigation strategies.
- Reproducibility is limited by proprietary data/tools: datasets, annotations, tool APIs, and environment specs are unavailable; no synthetic or anonymized benchmarks released for community validation.
- Resource budgeting and cost profiling are sparse: despite near-linear scaling, absolute GPU-hours, memory footprints, and per-sample token usage (controller vs expert agents vs OBSK lookups) are not reported; no cost-performance optimization study.
- Workflow integration details are limited: the human-in-the-loop process (triage, escalation, verification, rollback) is not fully specified; no user studies on SRE adoption, trust calibration, or UI/UX impacts.
- Ethical and organizational risks are unexamined: potential bias in “responsibility determination” across teams/services, accountability implications, and safeguards against unfair blame assignment are not discussed.
- Model choice trade-offs are not quantified: no empirical measurement of the performance gap vs API models (e.g., GPT-4) under identical constraints; unclear when upgrading local models yields meaningful gains.
- Automatic tool creation and adaptation are unexplored: no methods for learning new tools/functions from usage logs, discovering missing tools, or adapting tool schemas as systems evolve.
- Handling very long trajectories and deeper investigations is untested: a 15-step pass rate is reported, but behavior under complex incidents requiring longer plans, branching, or revisits remains unknown.
- Confidence estimation and calibration are absent: RCAgent does not provide uncertainty estimates or calibrated confidence in root cause/solution (e.g., via PACE-LM, conformal prediction), limiting safe automation.
- Online/streaming RCA is unaddressed: methods assume static snapshots pre-detection; handling continuous log streams, real-time updates, and race conditions during incident progression is an open area.
Practical Applications
Overview
Based on the paper “RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented LLMs,” the core innovations—privacy-preserving, locally hosted LLM agents; Observation Snapshot Key (OBSK) for long-context handling; semantically minimalist tools; expert agents for logs and code; JSON repairing and error handling stabilizers; and trajectory-level self-consistency (TSC)—enable a broad set of practical applications. Below, we group actionable use cases by immediacy, note relevant sectors, outline potential products/workflows, and list key assumptions/dependencies that affect feasibility.
Immediate Applications
The following applications can be deployed now with moderate engineering and integration effort, using on-prem/privately hosted LLMs and existing observability stacks.
- Cloud/SaaS: Autonomous incident triage and RCA for microservices, data streams, and Kubernetes
- Sectors: Software, Cloud Computing, DevOps
- What: Automate root cause identification, remediation steps, evidence gathering, and responsibility attribution for service incidents (including out-of-domain anomalies); integrate with existing rule-based advisors to cover gaps.
- Tools/products/workflows: “RCAgent for Kubernetes” add-on; connectors to PagerDuty/Jira/ServiceNow; CI/CD hooks; autosummaries with evidence snippets; responsibility labels for SRE handoff.
- Assumptions/dependencies: Centralized, queryable logs/metrics/traces; access-controlled code repo; GPU capacity to host a 13B LLM (e.g., A100 class or smaller via quantization); minimal tool interfaces (entity-ID based); governance to review high-impact actions.
- Regulated enterprises: Privacy-preserving AIOps for on-prem and hybrid clouds
- Sectors: Finance, Healthcare, Government
- What: Run RCA with locally deployed models to keep PII/PHI and production telemetry off external APIs; produce auditable, evidence-backed reports.
- Tools/products/workflows: On-prem RCA appliance; SOC2/ISO-aligned logging of agent decisions; redaction modules; export of evidence to compliance archives.
- Assumptions/dependencies: Sufficient on-prem compute; strict IAM for data access; established observability practices; auditor-approved agent governance.
- CI/CD pipeline failure diagnosis and auto-remediation suggestions
- Sectors: Software, DevOps
- What: Use the code expert agent to analyze build/test failures, dependency diffs, flaky tests; propose remediation steps or candidate patches.
- Tools/products/workflows: GitHub Actions/Jenkins plugins; PR generation with suggested fixes; evidence-linked failure summaries.
- Assumptions/dependencies: Access to build logs and source repos; robust mapping from class/component to file paths; guardrails for patch suggestions.
- Data/ML platform reliability (batch/stream processing)
- Sectors: Software, Analytics/AI Platforms
- What: Diagnose Airflow/Spark/Flink pipeline failures using log expert agent (clustering + evidence checks) and OBSK for long logs; recommend fixes and responsibility.
- Tools/products/workflows: Airflow/Spark/Flink operators packaged with RCAgent; dashboards showing clustered log evidence; MLOps pipeline triage.
- Assumptions/dependencies: Centralized pipeline logs; stable entity IDs for jobs/tasks; curated retrieval examples for RAG; clear SLO/SLA definitions.
- ERP/CRM/ITSM support triage with evidence-backed analysis
- Sectors: Enterprise Software, Customer Support
- What: Summarize error logs/events, identify likely causes, and propose next steps for support tickets; attribute responsibility (customer config vs platform).
- Tools/products/workflows: ServiceNow/Zendesk integrations; ticket enrichment with evidence snippets; auto-suggested runbooks.
- Assumptions/dependencies: Unified event and log access; runbook repositories; human-in-the-loop approvals.
- SecOps alert triage for operational (non-detection) analysis
- Sectors: Security Operations (bridging with AIOps)
- What: Apply log expert agent to SIEM/SOAR alert clusters to produce artifact-linked, evidence-backed summaries for triage (not replacing detection).
- Tools/products/workflows: SIEM connector (e.g., Splunk/ELK/Chronicle) that feeds clustered evidence to analysts; enriched alert narratives.
- Assumptions/dependencies: Careful scoping to ops/triage (not detection/response); evidence validation rules tuned to security log formats; strict privacy controls.
- Edge/IoT fleet operations triage
- Sectors: IoT, Manufacturing IT
- What: Cluster device logs at scale, identify recurrent failure modes, attribute responsibility (device/firmware vs platform/network), recommend steps (e.g., firmware rollback).
- Tools/products/workflows: Fleet management plugin; device-class runbook suggestions; evidence-linked dashboards.
- Assumptions/dependencies: Telemetry aggregation; stable device IDs; network constraints management for local inference.
- SRE team augmentation and knowledge capture
- Sectors: Software, Cloud Computing
- What: Use TSC to aggregate multiple analyses into concise incident narratives; convert postmortems into in-context exemplars for expert agents; bootstrap knowledge bases.
- Tools/products/workflows: Postmortem-to-RAG pipeline; “RCA Knowledge Builder” that curates examples and embeds them for retrieval.
- Assumptions/dependencies: Access to historical incidents; policies for anonymization and reuse; embedding store.
- Agent reliability toolkits
- Sectors: Software Tools
- What: Productize JsonRegen (YAML-based repair), OBSK (snapshot key-value store), error handling heuristics, and TSC as reusable agent stabilization components.
- Tools/products/workflows: SDKs for agent developers; plug-ins for LangChain/LlamaIndex/OpenAI function calling alternatives.
- Assumptions/dependencies: Integration testing in heterogeneous toolchains; performance tuning for target LLMs.
- Academic research testbeds and benchmarks for tool-augmented agents on noisy/long data
- Sectors: Academia
- What: Use the methodology (OBSK, expert agents, TSC) to build replicable agent benchmarks on open-source logs/code; evaluate action validity and stability.
- Tools/products/workflows: Open benchmarks with realistic log/code corpora; ablation suites; baseline leaderboards.
- Assumptions/dependencies: Availability of non-sensitive datasets; standardization of log schemas; compute access for local models.
Long-Term Applications
These applications require further research, tooling, data integration, scaling, or domain adaptation. Many are feasible extensions but need robust safety, regulation adherence, and broader tool ecosystems.
- Proactive, closed-loop remediation with policy-aware guardrails
- Sectors: Software, Cloud, Energy, Manufacturing IT
- What: Move from RCA to automated remediation (e.g., rollback, throttling, circuit breakers) under strict policy constraints; verify actions via guardrails and simulators.
- Tools/products/workflows: Policy engines; canary/sandbox validation; secure action dispatch; continuous verification pipelines.
- Assumptions/dependencies: High-fidelity test environments; formalized rollback/runbooks; risk scoring; regulatory reviews.
- Cross-domain autonomous diagnostics (OT/IT convergence)
- Sectors: Healthcare (device ops), Energy (grid), Manufacturing (OT), Robotics, Automotive
- What: Adapt expert agents to domain-specific logs and telemetry (PLC logs, DICOM device logs, robot telemetry) for evidence-backed RCA.
- Tools/products/workflows: Domain adapters for log schemas; safety-certified agent sandboxes; curated RAG bases with domain exemplars.
- Assumptions/dependencies: Vendor cooperation for APIs/log formats; rigorous safety processes (e.g., IEC 62304 in med devices); domain expert oversight.
- Responsibility attribution frameworks for SLA/SLO and insurance/legal workflows
- Sectors: Finance, Insurance, Cloud Contracts, Legal Tech
- What: Standardize agent-generated evidence and responsibility outputs for SLA dispute resolution and cyber insurance claims.
- Tools/products/workflows: Evidence schemas; digitally signed reports; auditor dashboards; chain-of-custody for evidence.
- Assumptions/dependencies: Industry standards for evidence; insurer and legal acceptance; auditability requirements.
- Federated/private LLM AIOps across organizations
- Sectors: Healthcare, Finance, Government
- What: Share patterns, embeddings, and insights without data leakage (e.g., federated learning or privacy-preserving RAG) to improve RCA across organizations.
- Tools/products/workflows: Secure enclaves; homomorphic encryption or differential privacy; cross-org model distillation.
- Assumptions/dependencies: Inter-org agreements; mature privacy-preserving ML; regulatory approvals.
- Continual learning from incidents to evolve rules and tools
- Sectors: Software, Cloud
- What: Use human feedback and TSC outcomes to refine expert agents, curate new retrieval examples, and synthesize rules/runbooks automatically.
- Tools/products/workflows: Feedback loops; active learning pipelines; rule synthesis and validation frameworks.
- Assumptions/dependencies: Safe data pipelines; versioned knowledge bases; evaluation harnesses to prevent regressions.
- Multi-agent SRE orchestration (logs, code, metrics, network traces)
- Sectors: Software, Telecom, Cloud
- What: Controller agents coordinate specialized sub-agents (metrics analysis, tracing, network diagnostics, code inspection) with shared memory and OBSK-like stores.
- Tools/products/workflows: Agent mesh frameworks; task queues; shared KV stores; arbitration policies for conflicting findings.
- Assumptions/dependencies: Interoperable tool contracts; scaling strategies; robust error handling across agents.
- Educational simulators for incident response and SRE training
- Sectors: Education, Workforce Development
- What: Build realistic incident labs where agents generate, analyze, and explain failures; trainees compare strategies and learn from agent evidence.
- Tools/products/workflows: Synthetic incident generators; graded scenarios; agent-human collaboration tools.
- Assumptions/dependencies: Open log/code datasets; training curricula; affordable compute for classrooms.
- Applying OBSK-style long-context handling beyond AIOps
- Sectors: Legal, Finance, Compliance
- What: Use snapshot keys and KV stores for agents working on lengthy documents (e-discovery, audits, regulatory filings), linking evidence reliably.
- Tools/products/workflows: Document agent frameworks; evidence-linking visualizations; compliant archiving.
- Assumptions/dependencies: Document indexing and chunking pipelines; secure storage; domain-tuned expert prompts.
- Robust structured interaction for agents (beyond JSON)
- Sectors: Software Tools, Enterprise Integration
- What: Generalize JsonRegen to robust, typed interfaces (e.g., JSON Schema, Protobuf) with automatic repair and verification for enterprise-grade agent workflows.
- Tools/products/workflows: Schematized toolcalling SDKs; conformance validators; multi-format adapters (YAML/TOML/JSON).
- Assumptions/dependencies: Tool vendor participation; performance overhead mitigation; standardization efforts.
- Cross-layer observability integration (business KPIs ↔ RCA)
- Sectors: eCommerce, FinTech, Media
- What: Correlate business impact metrics (checkout failures, drop in revenue) with technical RCA to prioritize and guide remediation.
- Tools/products/workflows: KPI-to-telemetry correlation engines; prioritized incident queues; ROI-oriented remediation recommendations.
- Assumptions/dependencies: Clean KPI telemetry; causality-aware analysis; data governance for sensitive business metrics.
Notes on Feasibility and Dependencies (Common Across Use Cases)
- Data quality and coverage: Effectiveness depends on comprehensive, centralized logs/metrics/traces and accessible source repositories.
- Tool design: Semantically minimalist tools (entity-ID based queries) are critical for action validity; exposing raw SQL/APIs markedly increases invalid actions.
- Compute constraints: Local LLM hosting requires adequate GPUs or optimized/quantized models; consider throughput vs latency trade-offs.
- Safety/governance: Human-in-the-loop reviews and guardrails are necessary in high-stakes domains; responsibility outputs must be handled carefully in legal or contractual contexts.
- Adaptation effort: Expert agent prompts, evidence filters, and error heuristics must be tuned for each domain’s log formats and workflows.
- Privacy/security: Strict IAM, redaction, and audit trails are mandatory in regulated settings; avoid cross-boundary data leakage when using embeddings or RAG.
These applications translate the paper’s findings into deployable pathways and set a map for extending tool-augmented, privacy-aware LLM agents from cloud RCA to broader, evidence-focused, and stable autonomous diagnostics across industries.
Glossary
- AIOps: The application of AI/ML techniques to automate and enhance IT operations and incident management. "a series of Artificial Intelligence for Operations~(AIOps) approaches~\cite{chen2016causeinfer,wang2020root,zhang2022netrca} have been widely adopted in RCA to reduce the MTTR~(mean time to resolve)."
- Apache Flink: An open-source stream processing framework for high-performance, real-time data processing. "RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud."
- BARTScore: A reference-based evaluation metric using a BART model to score text generation quality. "Besides semantic metric scores including METEOR~\cite{banerjee2005meteor}, NUBIA~\cite{kane2020nubia} (6-dim), BLEURT~\cite{sellam2020bleurt}, and BARTScore~\cite{yuan2021bartscore} (F-Score, CNNDM), we use additional embedding Score~(EmbScore)..."
- BLEURT: A learned evaluation metric for text generation that uses pretrained models fine-tuned for quality estimation. "Besides semantic metric scores including METEOR~\cite{banerjee2005meteor}, NUBIA~\cite{kane2020nubia} (6-dim), BLEURT~\cite{sellam2020bleurt}, and BARTScore~\cite{yuan2021bartscore} (F-Score, CNNDM)..."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from LLMs. "Both generate analyses and aggregations prompted by the zero-shot Chain-of-Thought~(CoT)~\cite{kojima2022large} and answer extraction instructions."
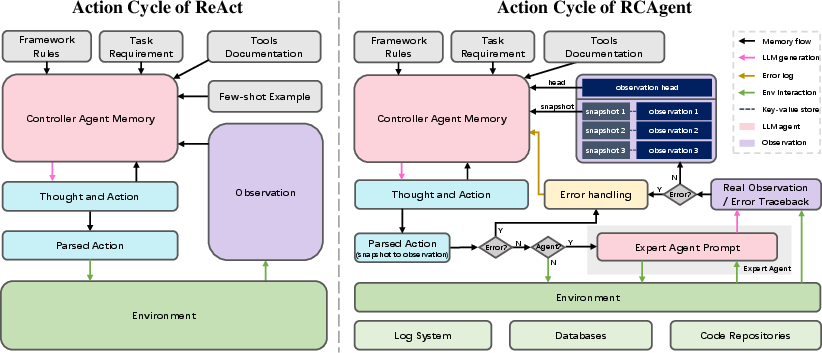
- controller agent: The primary LLM agent orchestrating the thought-action-observation loop and coordinating tool use. "the LLM agent with the prompt of thought-action-observation loop is named the controller agent responsible for coordinating actions"
- cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them; used here for log line relevance. "We split the log into lines and built edges between lines with the cosine similarity of embedding exponentially decayed by document distance as weights ."
- Embedding Score (EmbScore): An evaluation metric computed as cosine similarity between embeddings of generated and reference texts. "we use additional embedding Score~(EmbScore), the cosine similarity from the default embedding model in our experiment."
- expert agent: An LLM-powered analytical tool specialized for domain tasks (e.g., code or log analysis) invoked by the controller agent. "We name this kind of analytical tool the expert agent, which is shown in Figure~\ref{fig:overview}."
- Flink Advisor: An internal rule-based knowledge base for Flink that encapsulates domain expertise for diagnosing incidents. "We use the Flink Advisor knowledge base, which is a large rule set distilled from experienced SREs' domain knowledge, to create analysis results for these jobs."
- G-Correctness: A judgment metric scored by GPT-4 estimating the correctness of model-predicted root causes/solutions. "We prompt the model to judge the accuracy and helpfulness of root cause and solution predictions, marked as G-Correctness and G-Helpfulness, respectively, and give a score within ."
- G-Helpfulness: A judgment metric scored by GPT-4 estimating the helpfulness of model-predicted root causes/solutions. "We prompt the model to judge the accuracy and helpfulness of root cause and solution predictions, marked as G-Correctness and G-Helpfulness, respectively, and give a score within ."
- greedy decoding: A decoding strategy that selects the highest-probability token at each step for deterministic generation. "We use the greedy decoding strategy by default for better reproducibility and stability."
- GTE-LARGE: A sentence embedding model used for semantic similarity and retrieval tasks. "The embedding model we use is GTE-LARGE~\cite{li2023towards}, for its slightly better results on MTEB~\cite{muennighoff2022mteb} than text-embedding-ada-002, providing an internally deployable substitute."
- IaaS: Infrastructure as a Service; cloud computing model providing virtualized computing resources. "We have incorporated a feedback mechanism in the company to identify issues in the PaaS and IaaS layers of the cloud system, offering insights for development teams."
- in-context learning: Using examples or retrieved information within the prompt to condition LLM behavior without parameter updates. "However, these models are not aware of the workflow of cloud RCA, leaving them simply analytical tools. We thus investigate tool-augmented LLM as agents ... with fine-tuning~\cite{jin2023assess,ahmed2023recommending} or in-context learning~\cite{chen2023empowering,jiang2023xpert}."
- JsonRegen: A regeneration procedure to repair malformed JSON outputs by converting to YAML and back to enforce structure. "we employ an intuitive and effective method to generate structured interchange data named JsonRegen."
- Levenshtein: Refers to Levenshtein distance, an edit distance metric used here to filter hallucinated evidence. "\If{\Call{Levenshtein}{} \Call{L}{} - \Call{L}{} 0.9}"
- Louvain community detection: A graph clustering method optimizing modularity to find communities; used to partition logs. "Then the graph is clustered with Louvain community detection~\cite{blondel2008louvain}, and the overlaps between clusters are removed..."
- mean time to resolve (MTTR): The average time required to resolve incidents from detection to recovery. "a series of Artificial Intelligence for Operations~(AIOps) approaches~\cite{...} have been widely adopted in RCA to reduce the MTTR~(mean time to resolve)."
- METEOR: A machine translation evaluation metric considering precision, recall, and synonymy. "Besides semantic metric scores including METEOR~\cite{banerjee2005meteor}, NUBIA~\cite{kane2020nubia} (6-dim), BLEURT~\cite{sellam2020bleurt}, and BARTScore~\cite{yuan2021bartscore}..."
- NUBIA: A neural evaluation metric assessing multiple semantic dimensions of generated text. "Besides semantic metric scores including METEOR~\cite{banerjee2005meteor}, NUBIA~\cite{kane2020nubia} (6-dim), BLEURT~\cite{sellam2020bleurt}, and BARTScore~\cite{yuan2021bartscore}..."
- nucleus sampling: A stochastic decoding method that samples from the smallest set of top tokens whose cumulative probability exceeds a threshold. "when the default decoding strategy for the controller agent is changed to nucleus sampling~(w/ Sampling), the stability collapses to Pass Rate and Invalid Rate..."
- Observation Snapshot Key (OBSK): A key-value snapshot mechanism that truncates observations and stores full content retrievable by a hash key to manage context length. "we propose OBservation Snapshot Key~(OBSK), a new method to address the context length problem in realistic cloud tasks."
- Out-of-Domain (OoD): Data or cases that fall outside the distribution or coverage of existing rules/models. "RCAgent analyzes all Out-of-Domain~(OoD) jobs that existing automatic SRE tools cannot properly handle."
- PaaS: Platform as a Service; cloud model providing platforms to build, run, and manage applications. "We have incorporated a feedback mechanism in the company to identify issues in the PaaS and IaaS layers of the cloud system, offering insights for development teams."
- ReAct: A thought-action-observation loop paradigm for LLM agents enabling reasoning and acting with tools. "A representative paradigm within the realm of autonomous agents is ReAct~\cite{yao2022react}, a workflow that embodies a thought-action-observation loop and offers flexibility for extensions~\cite{liu2023bolaa}."
- Retrieval-Augmented Generation (RAG): A method that augments LLM generation by retrieving relevant documents or examples. "This clustering functions as semantic partitioning, and the result log chunks are then fed into the log agent one chunk per round to perform Retrieval-Augmented Generation~(RAG)~\cite{lewis2020retrieval}."
- Root Cause Analysis (RCA): The process of identifying the underlying causes of incidents or failures. "Root Cause Analysis~(RCA)~\cite{zhang2021cloudrca, nguyen2013fchain, aggarwal2020localization}, a core component of site reliability engineering, is currently receiving ongoing attention..."
- Self-Consistency (SC): An inference-time technique that samples multiple reasoning paths and aggregates them to improve reliability. "Self-Consistency~(SC)~\cite{wang2022self} has proved its efficacy in various close-ended NLP tasks while aggregating sampled open-ended multi-step generation like RCA..."
- Simple Log Service (SLS): Alibaba Cloud’s managed log storage and analytics service. "Log data at three levels: platform, runtime, and infrastructure, stored in SLS~(Simple Log Service) of Alibaba Cloud."
- SRE (Site Reliability Engineering): A discipline that applies software engineering to infrastructure and operations to create reliable systems. "similar to the data collection and analysis process done by human SREs."
- Trajectory-level Self-Consistency (TSC): An SC variant that samples and aggregates only near-final segments of agent trajectories to reduce cost and improve stability. "Therefore, we propose a mid-way sampling method named Trajectory\nobreakdash-level Self-Consistency~(TSC) as shown in Figure~\ref{fig:selfconsistency}."
- vLLM: A high-throughput LLM inference engine for efficient serving. "Our implementation is based on Vicuna-13B-V1.5-16K~\cite{zheng2023judging} with vLLM~\cite{kwon2023efficient} backend on a single NVIDIA A100 SXM4 GPU (80 GB)."
- Vicuna-13B-V1.5-16K: A 13B-parameter LLaMA-based chat model variant configured for 16K context length. "Our implementation is based on Vicuna-13B-V1.5-16K~\cite{zheng2023judging} with vLLM~\cite{kwon2023efficient} backend..."
- XGBoost: A scalable, regularized gradient-boosted decision tree algorithm often used for classification/regression. "We use all possible types of relevant data of a job, truncated if exceeding the model length constraint, to train XGBoost using document embeddings..."
Collections
Sign up for free to add this paper to one or more collections.