- The paper introduces FDSP, a novel method where LLMs iteratively refine code using Bandit feedback to patch security vulnerabilities.
- It employs the PythonSecurityEval benchmark with 470 real-world prompts to assess improvements in mitigating threats like SQL injection.
- Empirical results show that FDSP outperforms direct prompting and self-debugging in models such as GPT-4, GPT-3.5, and CodeLlama.
Can LLMs Patch Security Issues? An Analytical Perspective
This essay explores the research presented in "Can LLMs Patch Security Issues?" (2312.00024) which explores the capability of LLMs to autonomously recognize and rectify security vulnerabilities in the code they generate. The study introduces a novel approach entitled Feedback-Driven Security Patching (FDSP) and tests its effectiveness using a newly created benchmark, PythonSecurityEval.
FDSP Methodology
The FDSP approach is centered on the utilization of static code analysis, specifically leveraging Bandit, to identify vulnerabilities within generated code. The method consists of four principal stages: code generation, code testing, solution generation, and code refinement. Upon generating code, LLMs receive feedback from Bandit to assess any security issues, subsequently using this feedback to propose solutions that potentially rectify these issues. This iterative refinement then continues until a satisfactory solution is achieved (Figure 1).
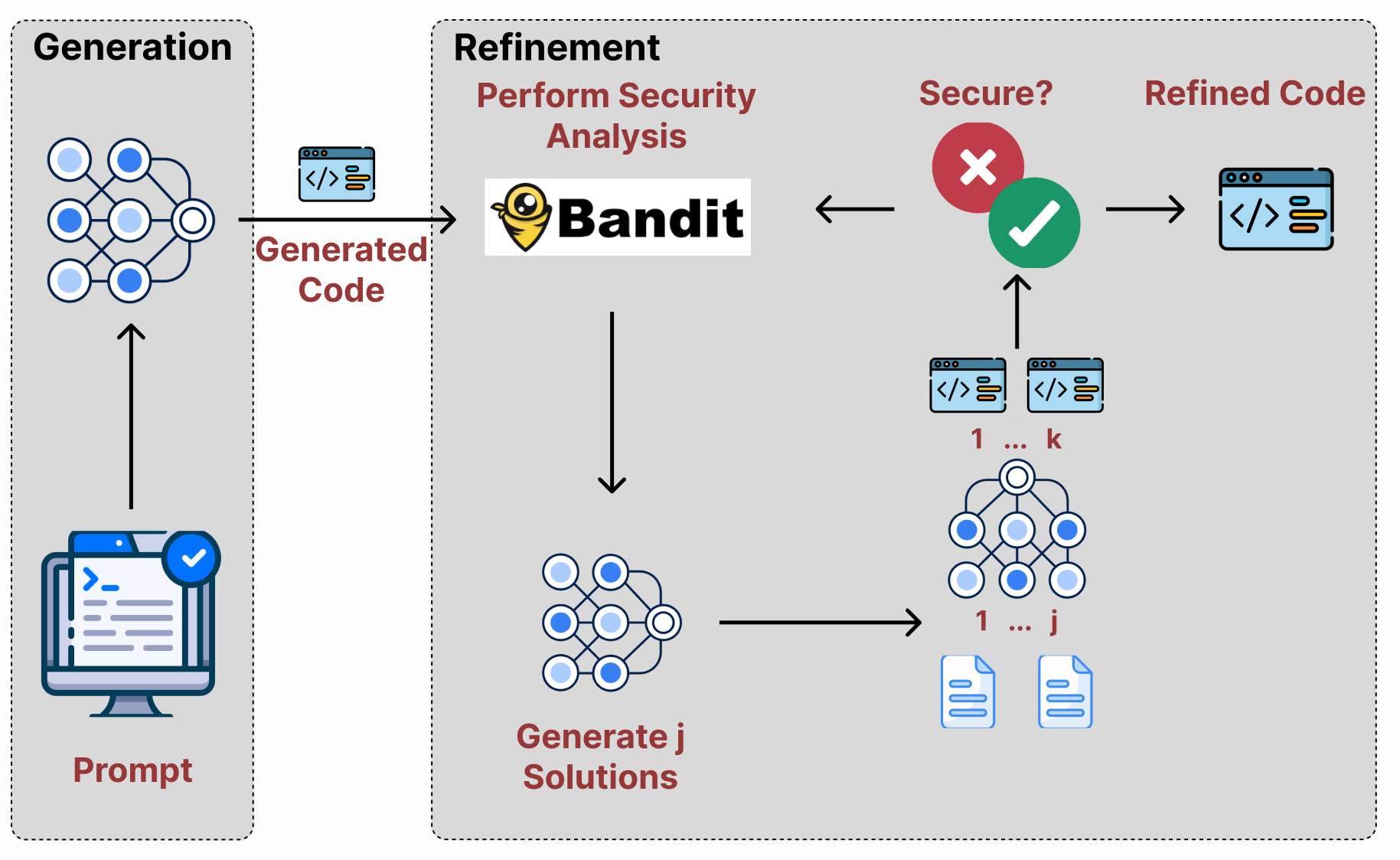
Figure 1: Overview of the FDSP method where LLMs utilize Bandit for static code analysis to identify and patch security vulnerabilities.
Datasets and Baseline Strategies
The introduction of the PythonSecurityEval dataset addresses the shortcomings of existing benchmarks, providing a more extensive evaluation framework for LLM capacities. The dataset comprises 470 natural language prompts sourced from Stack Overflow, reflecting a broad spectrum of real-world applications where vulnerabilities are prevalent, such as SQL injection and cross-site scripting (Figure 2).
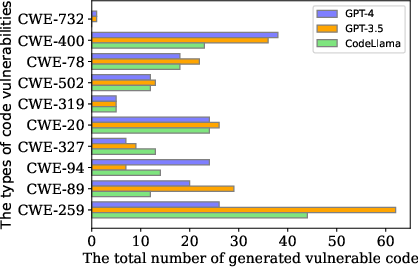
Figure 2: Distribution of the top common security issues within the code generated for the PythonSecurityEval dataset.
For comparative purposes, several baseline strategies are assessed alongside FDSP: direct prompting, self-debugging, Bandit feedback, and verbalization. Each varies in its dependence on feedback—from the model itself, external tools like Bandit, or human verbalization—to improve upon the initial code generation results.
Empirical Findings
The empirical analyses reveal that FDSP consistently outperforms other baseline methods across multiple benchmarks including LLMSecEval, SecurityEval, and PythonSecurityEval datasets. The utilization of Bandit feedback substantially improves the security performance of models such as GPT-4, GPT-3.5, and CodeLlama compared to methods relying on self-generated feedback alone (Figure 3).
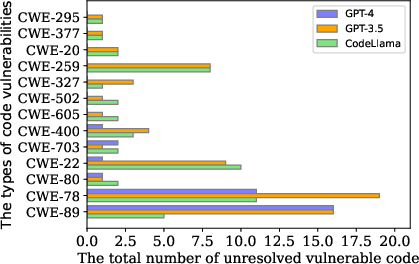
Figure 3: Unresolved top security issues in the PythonSecurityEval dataset despite refinement attempts.
FDSP achieved particular prowess in generating refined solutions and exhibited marked improvements in resolving common security vulnerabilities such as OS command injection and SQL injection (Figure 4).
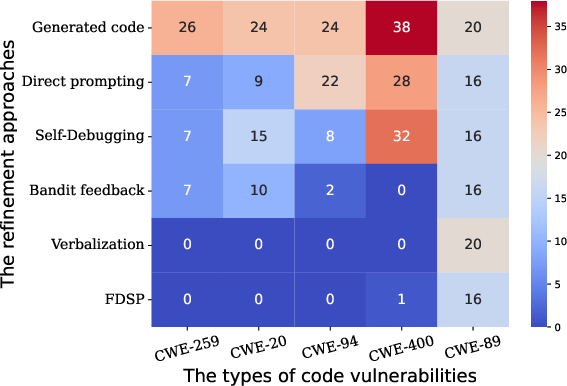
Figure 4: Impact of various refinement strategies on the most common security issues within the CodeLLama generated outputs.
Implications and Future Directions
The implications of FDSP are profound, providing potential pathways for enhancing the security capabilities of LLMs without excessive reliance on human-labeled datasets. This advances LLMs towards autonomous vulnerability detection and remediation, potentially curtailing the extensive costs associated with manual dataset creation. Still, challenges persist, including the assurance of functional correctness post-refinement—a problem that underscores the need for further research into testing methodologies that preserve code semantics.
Looking toward future developments, integrating dynamic analysis alongside static methods like Bandit might further improve detection capabilities. Exploring hybrid approaches may solve existing limitation of entirely depending on static tools, enriching the feedback loop further with runtime insights.
Conclusion
In sum, "Can LLMs Patch Security Issues?" extends the frontier for secure code generation by illustrating how FDSP, informed by static code analysis, markedly enhances LLM outputs. With demonstrated improvements in security patching, FDSP significantly advances the prospects of using LLMs for real-world application code generation while mitigating prominent security risks. Through PythonSecurityEval, researchers now have a contemporary benchmark for further investigations into LLM security vulnerabilities.