Learning the Unlearned: Mitigating Feature Suppression in Contrastive Learning
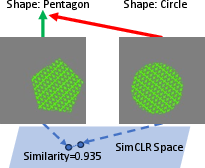
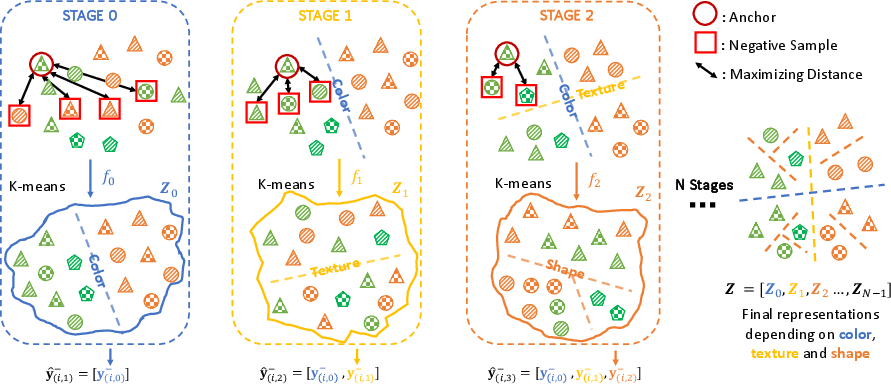
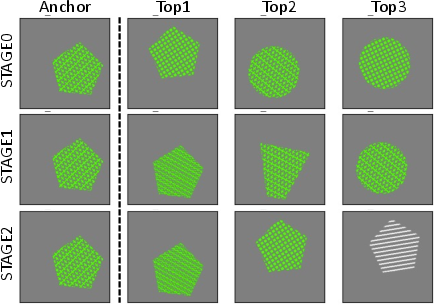
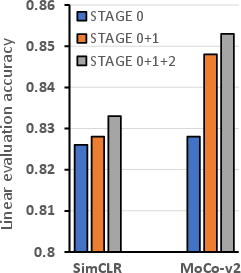
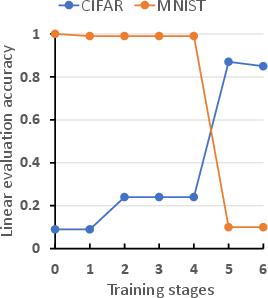
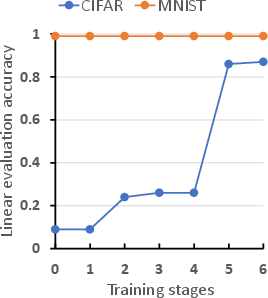
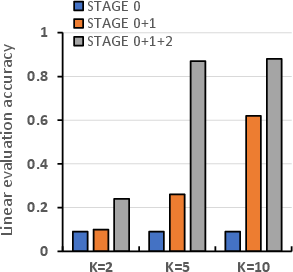
Abstract: Self-Supervised Contrastive Learning has proven effective in deriving high-quality representations from unlabeled data. However, a major challenge that hinders both unimodal and multimodal contrastive learning is feature suppression, a phenomenon where the trained model captures only a limited portion of the information from the input data while overlooking other potentially valuable content. This issue often leads to indistinguishable representations for visually similar but semantically different inputs, adversely affecting downstream task performance, particularly those requiring rigorous semantic comprehension. To address this challenge, we propose a novel model-agnostic Multistage Contrastive Learning (MCL) framework. Unlike standard contrastive learning which inherently captures one single biased feature distribution, MCL progressively learns previously unlearned features through feature-aware negative sampling at each stage, where the negative samples of an anchor are exclusively selected from the cluster it was assigned to in preceding stages. Meanwhile, MCL preserves the previously well-learned features by cross-stage representation integration, integrating features across all stages to form final representations. Our comprehensive evaluation demonstrates MCL's effectiveness and superiority across both unimodal and multimodal contrastive learning, spanning a range of model architectures from ResNet to Vision Transformers (ViT). Remarkably, in tasks where the original CLIP model has shown limitations, MCL dramatically enhances performance, with improvements up to threefold on specific attributes in the recently proposed MMVP benchmark.
- The hidden uniform cluster prior in self-supervised learning. arXiv preprint arXiv:2210.07277, 2022.
- Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
- Reducing predictive feature suppression in resource-constrained contrastive image-caption retrieval. Transactions on Machine Learning Research, 2023.
- Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- A simple framework for contrastive learning of visual representations. In International conference on machine learning, pp. 1597–1607. PMLR, 2020.
- Intriguing properties of contrastive losses. Advances in Neural Information Processing Systems, 34:11834–11845, 2021.
- Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 15750–15758, 2021.
- Learning robust representations via multi-view information bottleneck. arXiv preprint arXiv:2002.07017, 2020.
- Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9729–9738, 2020.
- What shapes feature representations? exploring datasets, architectures, and training. Advances in Neural Information Processing Systems, 33:9995–10006, 2020.
- A survey on contrastive self-supervised learning. Technologies, 9(1):2, 2020.
- Temperature schedules for self-supervised contrastive methods on long-tail data. arXiv preprint arXiv:2303.13664, 2023.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- Self-supervised learning: Generative or contrastive. IEEE transactions on knowledge and data engineering, 35(1):857–876, 2021.
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Zero-shot text-to-image generation. In International Conference on Machine Learning, pp. 8821–8831. PMLR, 2021.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Can contrastive learning avoid shortcut solutions? Advances in neural information processing systems, 34:4974–4986, 2021.
- Everything at once-multi-modal fusion transformer for video retrieval. In Proceedings of the ieee/cvf conference on computer vision and pattern recognition, pp. 20020–20029, 2022.
- Feature dropout: Revisiting the role of augmentations in contrastive learning. arXiv preprint arXiv:2212.08378, 2022.
- Self-supervised learning from a multi-view perspective. arXiv preprint arXiv:2006.05576, 2020.
- Unsupervised semantic segmentation by contrasting object mask proposals. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10052–10062, 2021.
- What should not be contrastive in contrastive learning. arXiv preprint arXiv:2008.05659, 2020.
- Which features are learnt by contrastive learning? on the role of simplicity bias in class collapse and feature suppression. arXiv preprint arXiv:2305.16536, 2023.
- A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 8980–8987, 2022.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.