Unity by Diversity: Improved Representation Learning in Multimodal VAEs
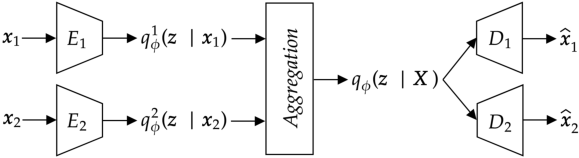
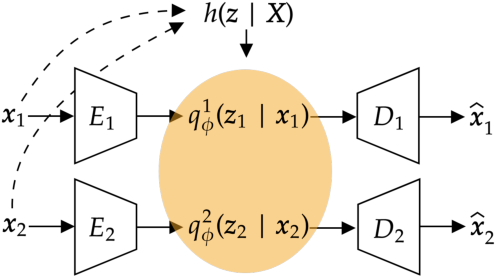
Abstract: Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
- Nonspatial sequence coding in ca1 neurons. Journal of Neuroscience, 36(5):1547–1563, 2016. ISSN 0270-6474. doi: 10.1523/JNEUROSCI.2874-15.2016. URL http://www.jneurosci.org/content/36/5/1547.
- Multimodal machine learning: A survey and taxonomy. IEEE transactions on pattern analysis and machine intelligence, 41(2):423–443, 2018.
- Multi-level variational autoencoder: Learning disentangled representations from grouped observations. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- A Simple Framework for Contrastive Learning of Visual Representations, June 2020. URL http://arxiv.org/abs/2002.05709. arXiv:2002.05709 [cs, stat].
- Self-supervised Disentanglement of Modality-specific and Shared Factors Improves Multimodal Generative Models. German Conference on Pattern Recognition, 2020. Publisher: Springer.
- On the Limitations of Multimodal VAEs. International Conference on Learning Representations, 2022.
- Efron, B. Large-scale inference: empirical Bayes methods for estimation, testing, and prediction, volume 1. Cambridge University Press, 2012.
- Falcon, W. and The PyTorch Lightning team. PyTorch Lightning, March 2019. URL https://github.com/Lightning-AI/lightning.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- beta-vae: Learning basic visual concepts with a constrained variational framework. 2016. URL https://openreview.net/forum?id=Sy2fzU9gl.
- Hosoya, H. A simple probabilistic deep generative model for learning generalizable disentangled representations from grouped data. CoRR, abs/1809.0, 2018.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Auto-Encoding Variational Bayes. In International Conference on Learning Representations, 2014.
- Gradient-based learning applied to document recognition. In Proceedings of the IEEE, volume 86, pp. 2278–2324, 1998. Issue: 11.
- Foundations and recent trends in multimodal machine learning: Principles, challenges, and open questions. arXiv preprint arXiv:2209.03430, 2022.
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Transactions on Information Theory, 37(1):145–151, January 1991. ISSN 1557-9654. doi: 10.1109/18.61115. URL https://ieeexplore.ieee.org/document/61115. Conference Name: IEEE Transactions on Information Theory.
- Deep Learning Face Attributes in the Wild. In The IEEE International Conference on Computer Vision (ICCV), 2015.
- Weakly-supervised disentanglement without compromises. In International Conference on Machine Learning, pp. 6348–6359. PMLR, 2020.
- Representation Learning with Contrastive Predictive Coding, January 2019. URL http://arxiv.org/abs/1807.03748. arXiv:1807.03748 [cs, stat].
- Mmvae+: Enhancing the generative quality of multimodal vaes without compromises. In The Eleventh International Conference on Learning Representations. OpenReview, 2023.
- Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pp. 8024–8035. Curran Associates, Inc., 2019.
- Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Learning Transferable Visual Models From Natural Language Supervision, February 2021. URL http://arxiv.org/abs/2103.00020. arXiv:2103.00020 [cs].
- Zero-shot text-to-image generation. In International Conference on Machine Learning, pp. 8821–8831, 2021.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. CoRR, abs/2205.1, 2022. doi: 10.48550/arXiv.2205.11487. URL https://doi.org/10.48550/arXiv.2205.11487.
- Hippocampal ensembles represent sequential relationships among an extended sequence of nonspatial events. Nature Communications, 13(1):787, February 2022. ISSN 2041-1723. doi: 10.1038/s41467-022-28057-6. URL https://www.nature.com/articles/s41467-022-28057-6.
- Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep Generative Models. In Advances in Neural Information Processing Systems, pp. 15692–15703, 2019.
- Ladder variational autoencoders. Advances in neural information processing systems, 29, 2016.
- Sutter, T. M. Imposing and Uncovering Group Structure in Weakly-Supervised Learning. Doctoral Thesis, ETH Zurich, 2023. URL https://www.research-collection.ethz.ch/handle/20.500.11850/634822. Accepted: 2023-10-04T05:58:47Z.
- Multimodal Generative Learning Utilizing Jensen-Shannon Divergence. Advances in Neural Information Processing Systems, 2020. URL https://arxiv.org/abs/2006.08242.
- Generalized Multimodal ELBO. International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=5Y21V0RDBV.
- Learning Group Importance using the Differentiable Hypergeometric Distribution. In International Conference on Learning Representations, 2023a.
- Differentiable Random Partition Models. In Advances in Neural Information Processing Systems, 2023b.
- A survey of multimodal deep generative models. Advanced Robotics, 36(5-6):261–278, 2022.
- Contrastive Multiview Coding, December 2020. URL http://arxiv.org/abs/1906.05849. arXiv:1906.05849 [cs].
- VAE with a VampPrior. arXiv preprint arXiv:1705.07120, 2017.
- Multimodal Generative Models for Scalable Weakly-Supervised Learning. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montreal, Canada, pp. 5580–5590, February 2018. URL http://arxiv.org/abs/1802.05335.
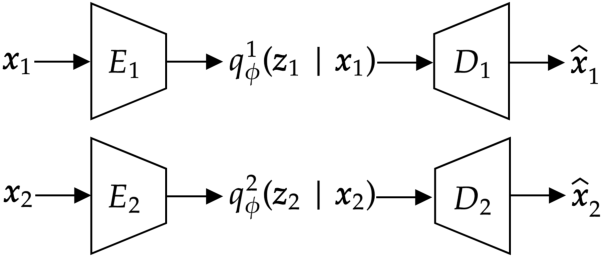


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.