- The paper introduces the MUSE framework, a novel self-supervised approach that leverages multimodal similarity-keeping contrastive learning for zero-shot EEG-based image classification.
- It employs advanced EEG encoders like STConv and NervFormer with a pre-trained CLIP-ViT image encoder, achieving superior performance (e.g., 19.3% top-1 accuracy) over established benchmarks.
- The study demonstrates the framework's neurophysiological relevance by aligning model attention with occipital and parietal regions during key EEG windows, supporting robust brain-inspired AI.
Multimodal Similarity-Keeping Contrastive Learning for EEG-Based Image Recognition
Introduction
Decoding high-dimensional visual representations from non-invasive electrophysiological signals remains a pivotal challenge at the crossroads of computational neuroscience and artificial intelligence. Electroencephalography (EEG) offers millisecond-scale temporal resolution, making it a premier modality for characterizing rapid neural responses to complex visual stimuli. Despite its advantages, EEG-based image decoding has been hampered by low signal-to-noise ratios, substantial nonstationarity, and architectural limitations of prior deep learning frameworks. This work introduces the Multimodal Similarity-keeping contrastivE learning (MUSE) framework, a self-supervised approach leveraging cross-modal contrastive learning and novel similarity-keeping regularization to improve zero-shot EEG-based image classification.
MUSE Framework: Architecture and Objectives
MUSE utilizes a two-tower architecture comprising an advanced EEG encoder—either classic spatial-temporal convolution (STConv) or a Transformer-inspired NervFormer—and a pre-trained CLIP-ViT image encoder. EEG-image pairs are independently mapped to a joint embedding space, where the model is trained to maximize separation between matched and unmatched pairs and preserve within-batch relationships for intra-modal consistency.
(Figure 1)
Figure 1: Schematic of the MUSE framework showing independent processing of EEG and image modalities and dual objectives for contrastive separation and similarity preservation.
A critical innovation is the similarity-keeping regularization, inspired by object representation topographies in inferotemporal cortex, which augments the InfoNCE contrastive loss with a term aligning inter-sample relationships across modalities. The trainable parameter β governs the trade-off between strict contrastive alignment and preservation of intra-batch structure.
Feature Space and Contrastive Learning Mechanics
Traditional multimodal contrastive learning focuses solely on aligning cross-modality pairs (e.g., image-text). MUSE extends this paradigm by incorporating batch-wise feature similarity: it enforces not only the alignment of EEG-image pairs but also the correlation in feature relationships within a batch, reflecting biological mechanisms in cortical visual processing.
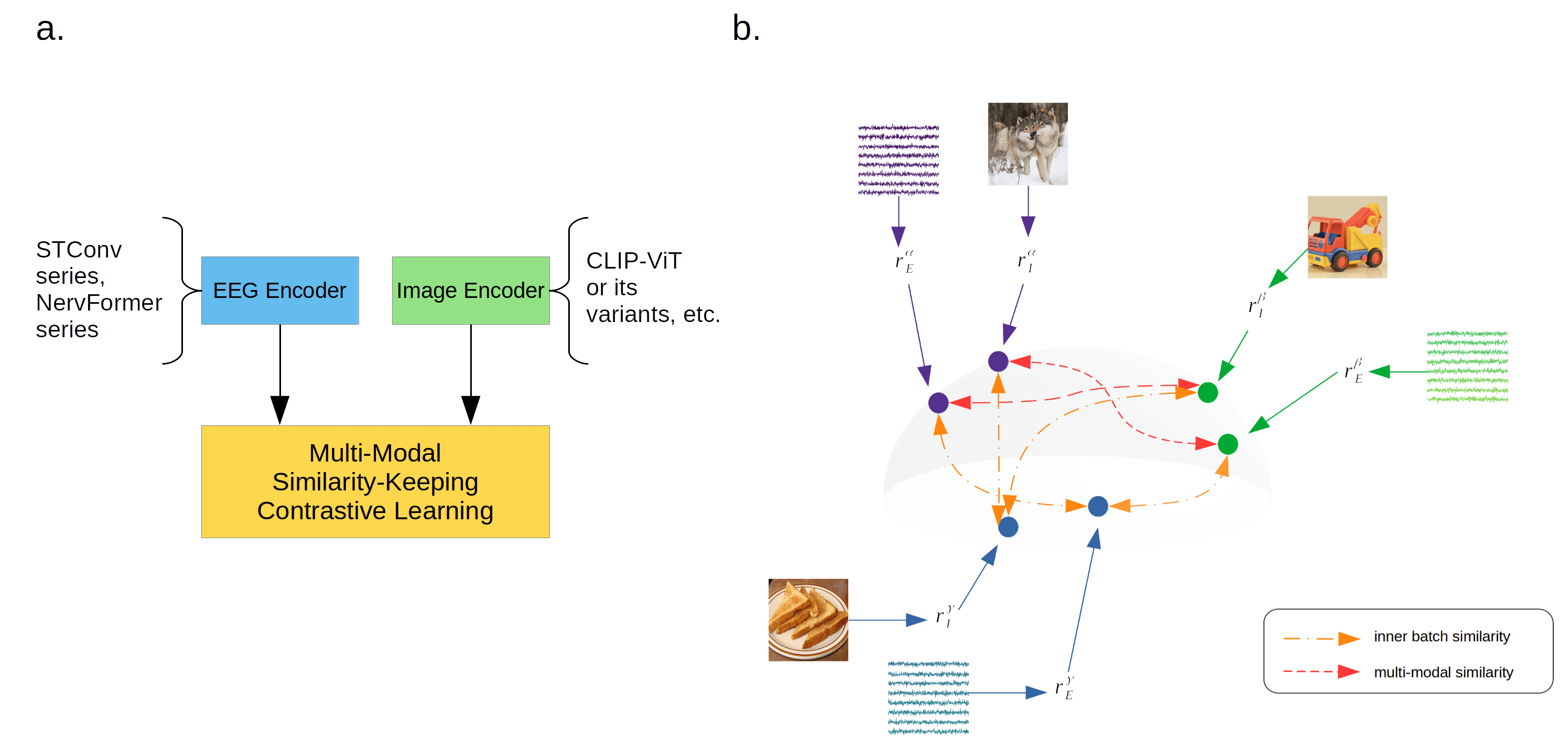
Figure 2: Illustration of MUSE’s feature space, enforcing both multimodal similarity and intra-batch relationship retention.
The similarity-keeping loss is defined as:
LSK=1−E[S(SE,E,SI,I)]
where SE,E and SI,I represent inner-batch similarity matrices for EEG and image samples, respectively. This mechanism regularizes the MUSE models to better emulate the relational structure observed in neurobiological responses to visual stimuli.
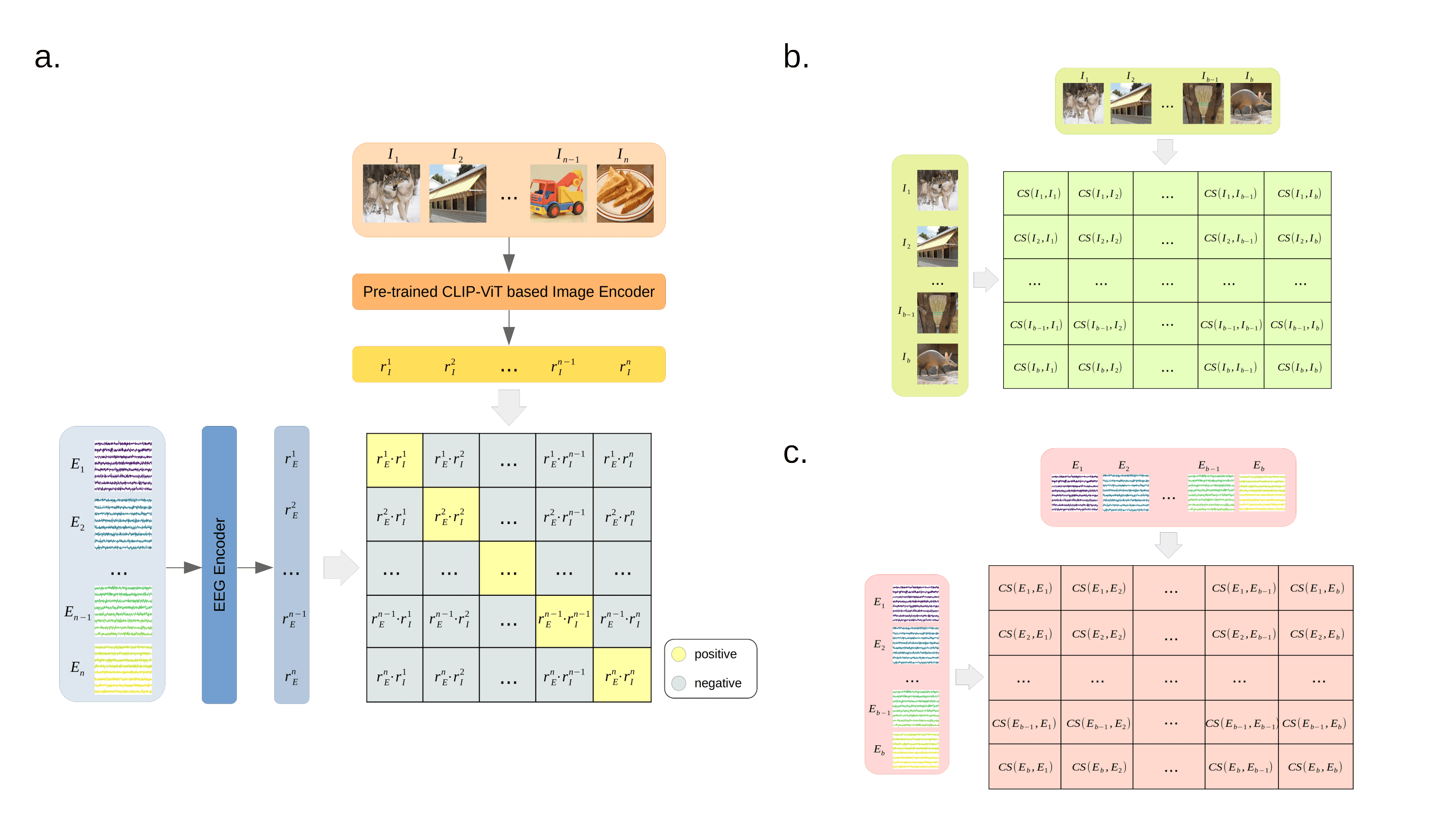
Figure 3: Depiction of contrastive loss and similarity-keeping regularization within the MUSE framework, highlighting modality-specific encoders and loss components.
Neural Encoding Architectures and Ablation
The study investigates several EEG encoder architectures. STConv employs data-driven spatial filtering for denoising and feature extraction. NervFormer, integrating graph attention networks, models inter-electrode relationships and hierarchical temporal dynamics, offering improved robustness against noise and enhanced representation learning.
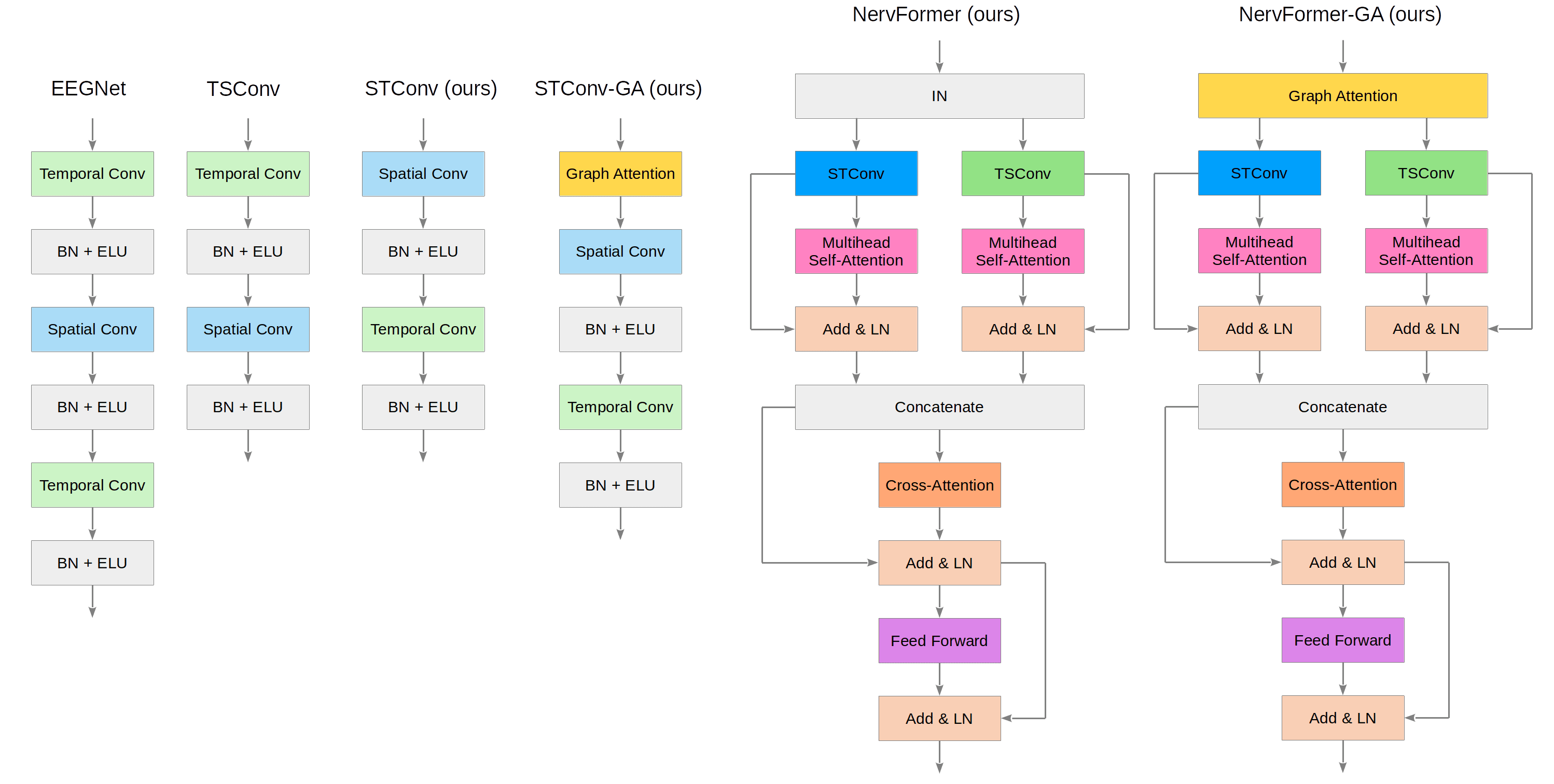
Figure 4: Model structure comparisons for EEG encoders, emphasizing normalization and graph-based attention mechanisms.
Ablation studies confirm the effectiveness of both similarity-keeping and graph attention enhancements. Specifically, MUSE-SK-Nerv-GA achieves superior individual subject accuracy, validating the synergistic effects of SK regularization and graph-based architectures.
Using the ThingsEEG dataset (16,740 images, 10 subjects, 64-channel EEG), models were trained and tested in a subject-dependent fashion. Extensive baselines—including NICE, NICE-GA, and BraVL—were evaluated. MUSE-SK attained the highest average top-1 accuracy (19.3%) and MUSE the top-5 accuracy (48.9%) in 200-way zero-shot classification, with all MUSE derivatives significantly outperforming prior benchmarks (p<0.01).
Figure 5: Top-1 zero-shot accuracy across all models, demonstrating the superiority of MUSE-based approaches.
Model Interpretation and Neurophysiological Relevance
Grad-CAM visualization elucidates the temporal and regional focus of the models: optimal variants (MUSE-SK, MUSE-SK-GA) concentrate on EEG segments corresponding to 100–500 ms post-stimulus, aligning with classic stages of the visual hierarchy (V1–V4, inferotemporal cortex). The emphasis on occipital and parietal regions recapitulates established neuroanatomical pathways for visual processing.
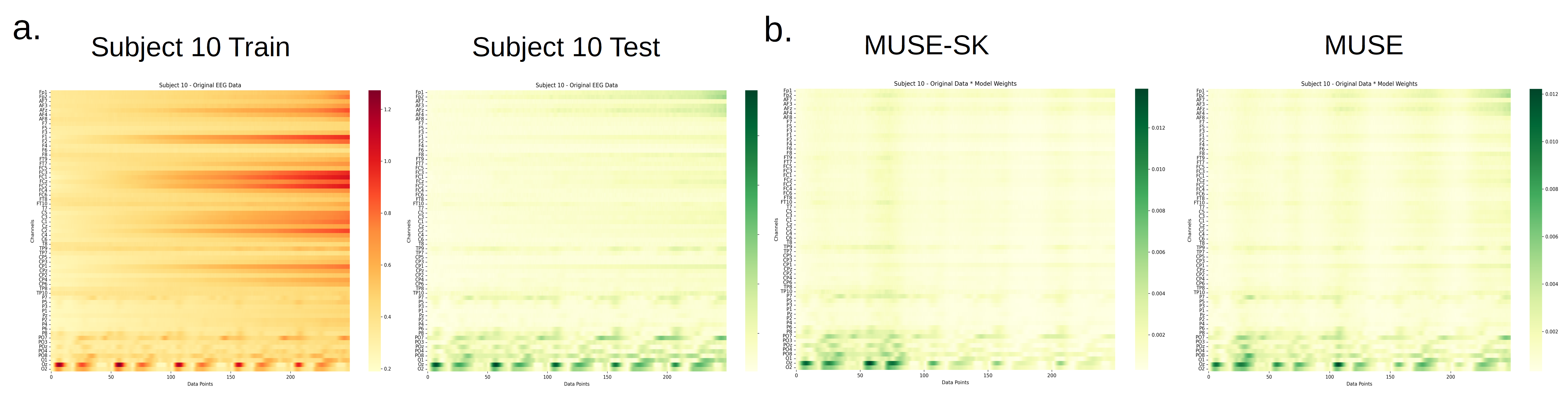
Figure 6: Grad-CAM visualizations indicating MUSE-SK’s heightened sensitivity to occipital lobe activity within critical EEG windows.
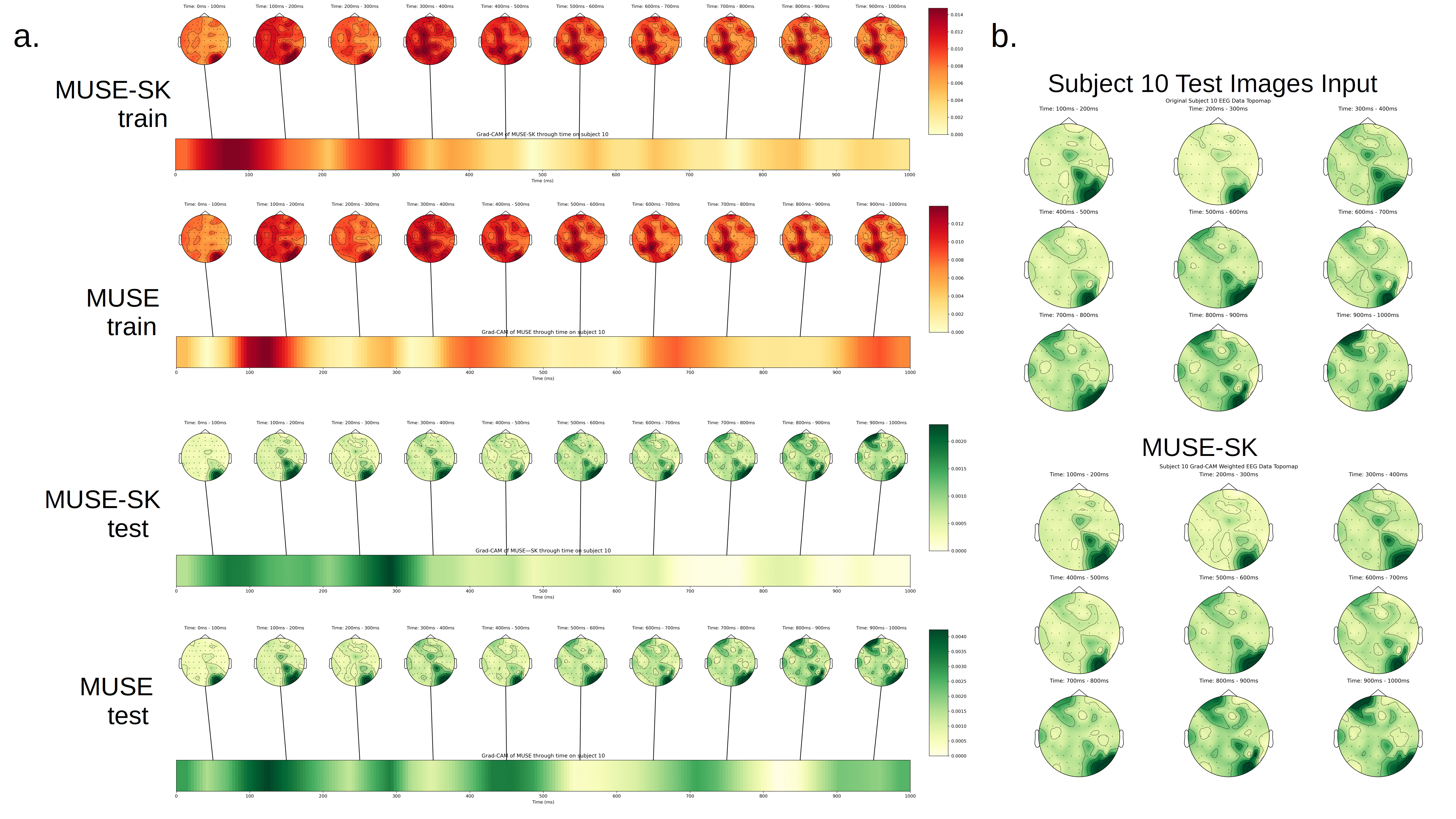
Figure 7: Topomap analysis demonstrates model focus on occipital and temporal cortex during the visual recognition window.
Further time-frequency analysis substantiates the biological plausibility of the learned representations, with alpha and gamma bands (known correlates of attention and recognition) prominently featured in high-performing models.
Implications and Future Prospects
The MUSE framework establishes a new state-of-the-art benchmark for zero-shot EEG-based image classification by seamlessly marrying contrastive learning with biologically inspired regularization. The retention of intra-batch relational structure and the incorporation of graph attention mechanisms enhance the fidelity and generalizability of neural representations. Practically, these advances pave the way for robust non-invasive BCI systems capable of scalable semantic decoding. Theoretically, the approach bridges computational principles with neuroscientific findings, informing future studies of cross-modal representation learning and neural decoding.
Future developments may include leveraging more powerful image encoders, extending to multi-subject generalization, and transferring these techniques to other sensory modalities or task domains such as motor imagery or auditory decoding. Continuous integration of neurophysiological knowledge will likely yield further gains in representation robustness and model interpretability.
Conclusion
The presented multimodal similarity-keeping contrastive learning framework (MUSE) delivers a substantive amplification in zero-shot EEG-based image classification performance. By embedding neuroscientific priors in the learning objective and modeling intra-batch sample similarity, MUSE produces meaningful, generalizable neural representations. The clarity and anatomical alignment of model attention maps reinforce both the practical utility and scientific validity of the framework, marking a significant step toward explainable, brain-inspired multimodal AI.