- The paper introduces a pseudo-label scorer to filter mismatched pseudo-labels, significantly improving ASQP self-training.
- It employs ranking-based objectives and conditional likelihood in a generative model to assess and rerank candidate labels.
- Experiments demonstrate that AI-generated annotations match human quality, paving the way for scalable data augmentation.
Self-Training with Pseudo-Label Scorer for Aspect Sentiment Quad Prediction
Introduction to ASQP and Pseudo-Label Scorers
Aspect Sentiment Quad Prediction (ASQP) is a crucial task in Aspect-Based Sentiment Analysis (ABSA), requiring the prediction of quadruples (aspect term, category, opinion term, sentiment polarity) from reviews. The challenge of limited labeled data in ASQP constrains existing models' performance. To address this, the authors propose a novel self-training framework utilizing a pseudo-label scorer to enhance self-training efficacy by filtering mismatched pseudo-labels from synthesized samples. The effectiveness of this scorer critically depends on the quality of the training dataset and its model architecture, achieved by creating a human-annotated comparison dataset and training a generative model with ranking-based objectives. The authors also explore AI-driven annotations using LLMs as a substitute for human annotators.

Figure 1: Illustration of our pseudo-label scorer.
Methodology and Scorer Design
Scorer Implementation
The proposed scorer assesses review-pseudo-label matches, leveraging conditional likelihoods from a generative model to evaluate quality. This approach integrates token-by-token likelihood consideration, providing a comprehensive score for pseudo-labels. The scorer's training employs a novel ranking-based objective with both positive and negative labels derived from human or AI-annotated comparison datasets. Additional positive labels from the original ASQP dataset further improve scorer training.
Data Filtering and Integration
The self-training framework integrates confidence-based and scorer-based data filtering mechanisms, ensuring high-quality data augmentation. Pseudo-labels with low confidence or scores are filtered out, retaining samples with scores between set thresholds. Reranking of candidate labels during inference is implemented using the pseudo-label scorer for further performance optimization.
Experimental Results
Experiments conducted on public ASQP datasets demonstrate that the proposed pseudo-label scorer substantially improves self-training effectiveness. Integration into two typical ASQP methods, GAS and MUL, showed consistent improvements, reflecting the robust performance of the scorer-enhanced framework. Using AI annotations was shown to be on par with human annotations, demonstrating the feasibility of replacing human annotators with AI for generating comparison datasets.
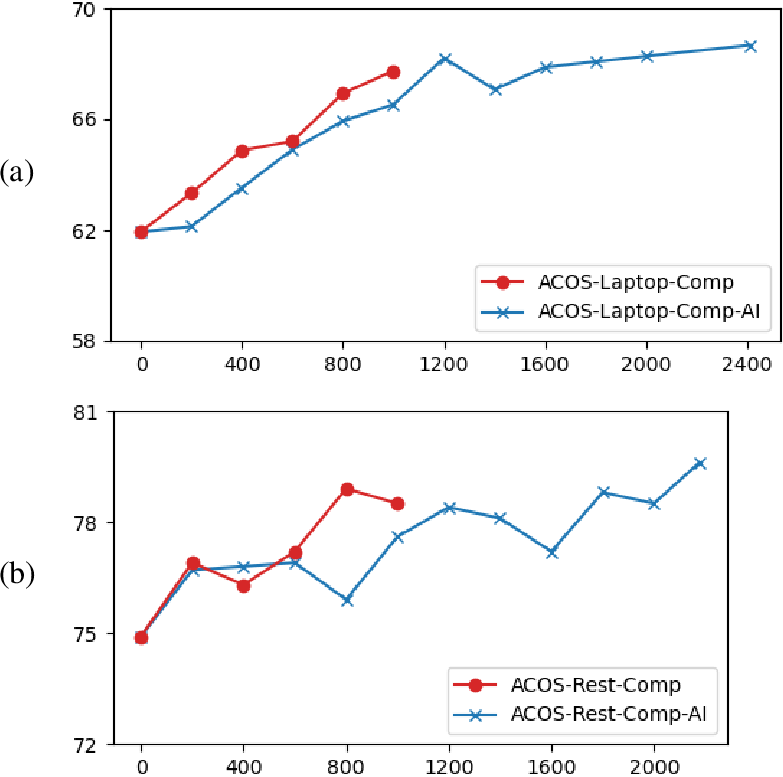
Figure 2: Performance trends of comparison data with increasing data quantity (accuracy, \%): (a) results on ACOS-Laptop; (b) results on ACOS-Rest.
Future Implications and Developments
The results indicate a promising direction for leveraging AI for dataset annotation, enhancing both efficiency and scalability. The study opens avenues for further exploration in balancing data synthesis and quality control in data augmentation frameworks. With performance gains evident across the evaluated datasets, the research underscores the importance of improving training datasets and model architectures for pseudo-label scorers. Future work could focus on optimizing scorer performance further and refining integration methods for broader ASQP applications.
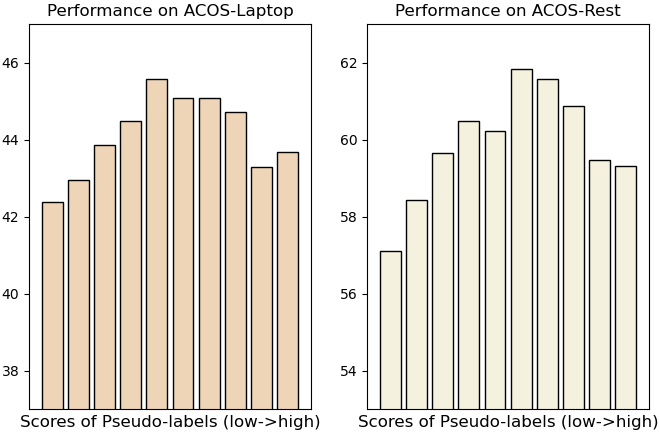
Figure 3: Performance of GAS on the augmented dataset under different match scores (F_1-score, \%).
Conclusion
The paper successfully introduces a pseudo-label scorer for the ASQP task, significantly enhancing self-training by effectively handling mismatches in data augmentation. The integration of this scorer in ASQP tasks proves its utility and demonstrates a substantial step forward in leveraging both human and AI-generated annotations for improving sentiment analysis models. Future research will benefit from further advancements in data synthesis methodologies and exploring scorer-based frameworks as independent ASQP models.
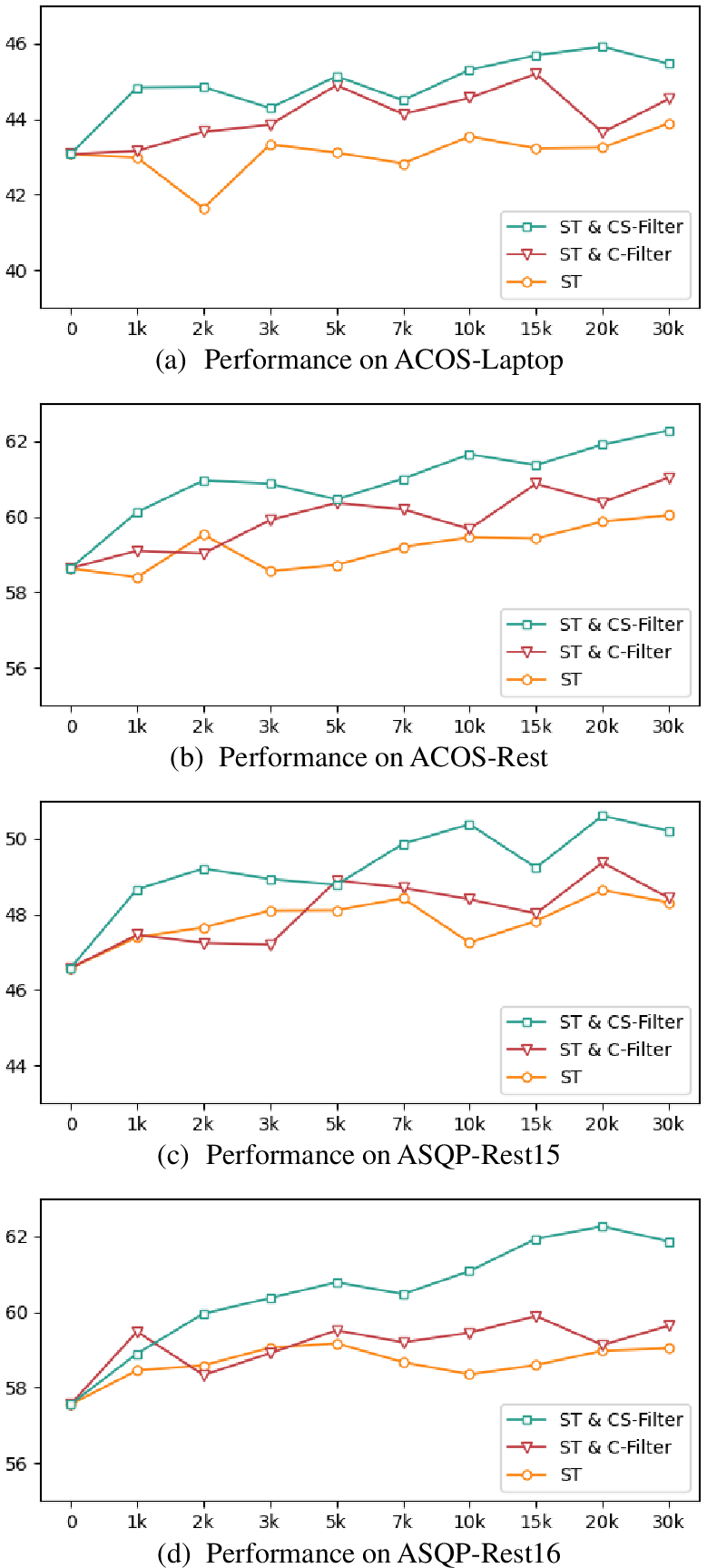
Figure 4: Performance of GAS under different numbers of augmented samples (F_1-score, \%).