- The paper presents a circuit discovery methodology that isolates content-independent syllogistic reasoning in transformer models.
- It demonstrates phase transitions in GPT-2 sizes, revealing distinct reasoning phases through targeted ablation studies.
- The results underscore the interplay between intrinsic reasoning mechanisms and world knowledge, informing future AI interpretability.
Reasoning Circuits in LLMs: A Mechanistic Interpretation of Syllogistic Inference
Introduction
The paper "Reasoning Circuits in LLMs: A Mechanistic Interpretation of Syllogistic Inference" (2408.08590) explores the internal functioning of transformer-based LLMs, particularly in syllogistic reasoning tasks. The authors present a mechanistic interpretation that distinguishes between content-independent reasoning mechanisms and those influenced by world knowledge acquired during pre-training. Through circuit discovery methodologies, the study reveals the internal circuitry responsible for content-independent syllogistic reasoning and explores how belief biases affect logical inference.
Methodology
The research employs various techniques to dissect the syllogistic reasoning mechanisms in auto-regressive LLMs. A crucial component of this study is the syllogism completion task, which tests a model's ability to derive valid conclusions from given premises. The authors implement a circuit discovery pipeline using Activation Patching and Logit Lens analyses to identify and interpret core reasoning mechanisms across symbolic and non-symbolic datasets.
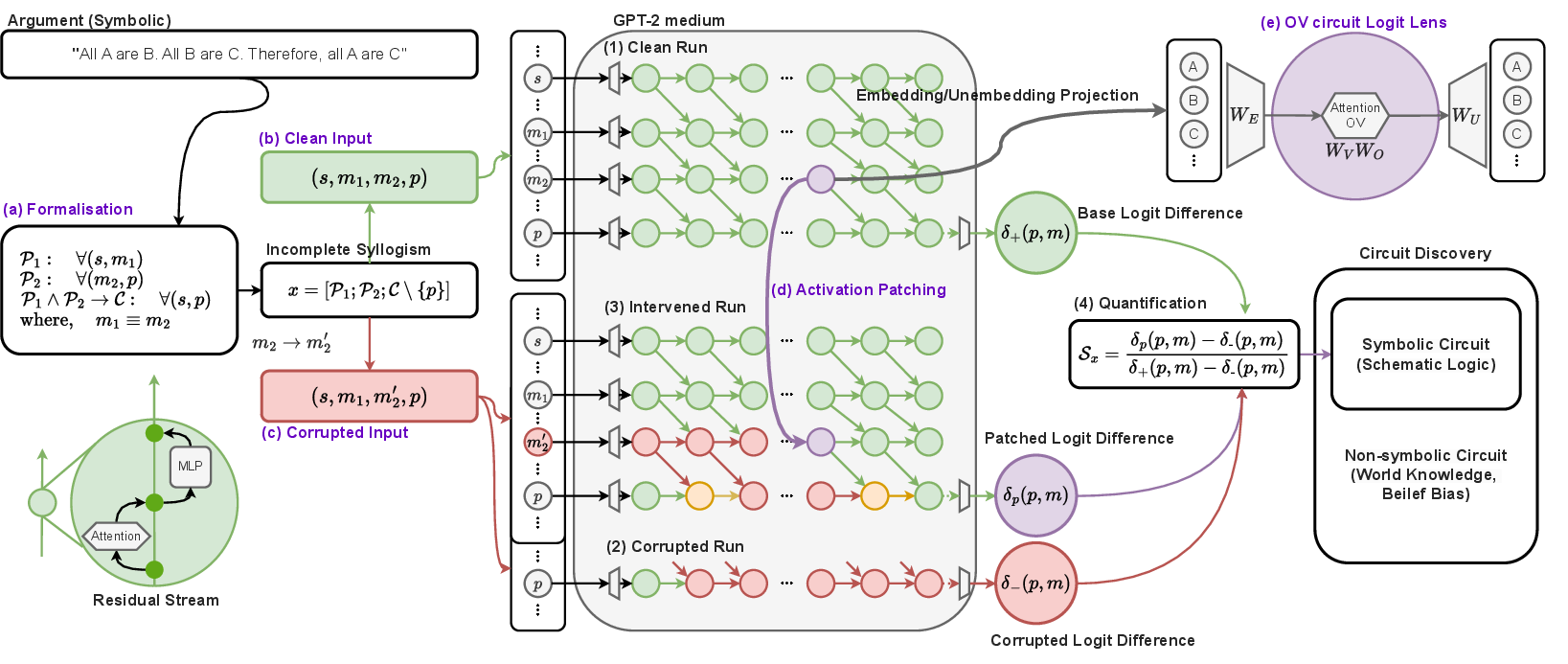
Figure 1: The conceptual pipeline of the symbolic circuit analysis on the syllogism completion task.
The paper outlines interventions such as middle-term corruption and all-term corruption, designed to isolate reasoning mechanisms from specific token information flow. These interventions are critical for understanding the latent transitive reasoning mechanisms and information propagation within models.
Empirical Evaluation
In their empirical evaluation, the authors analyze various sizes of GPT-2 models to gauge syllogistic reasoning capabilities. Notably, a phase transition is observed with performance improvements between small and medium models, emphasizing the scalability of reasoning capabilities.
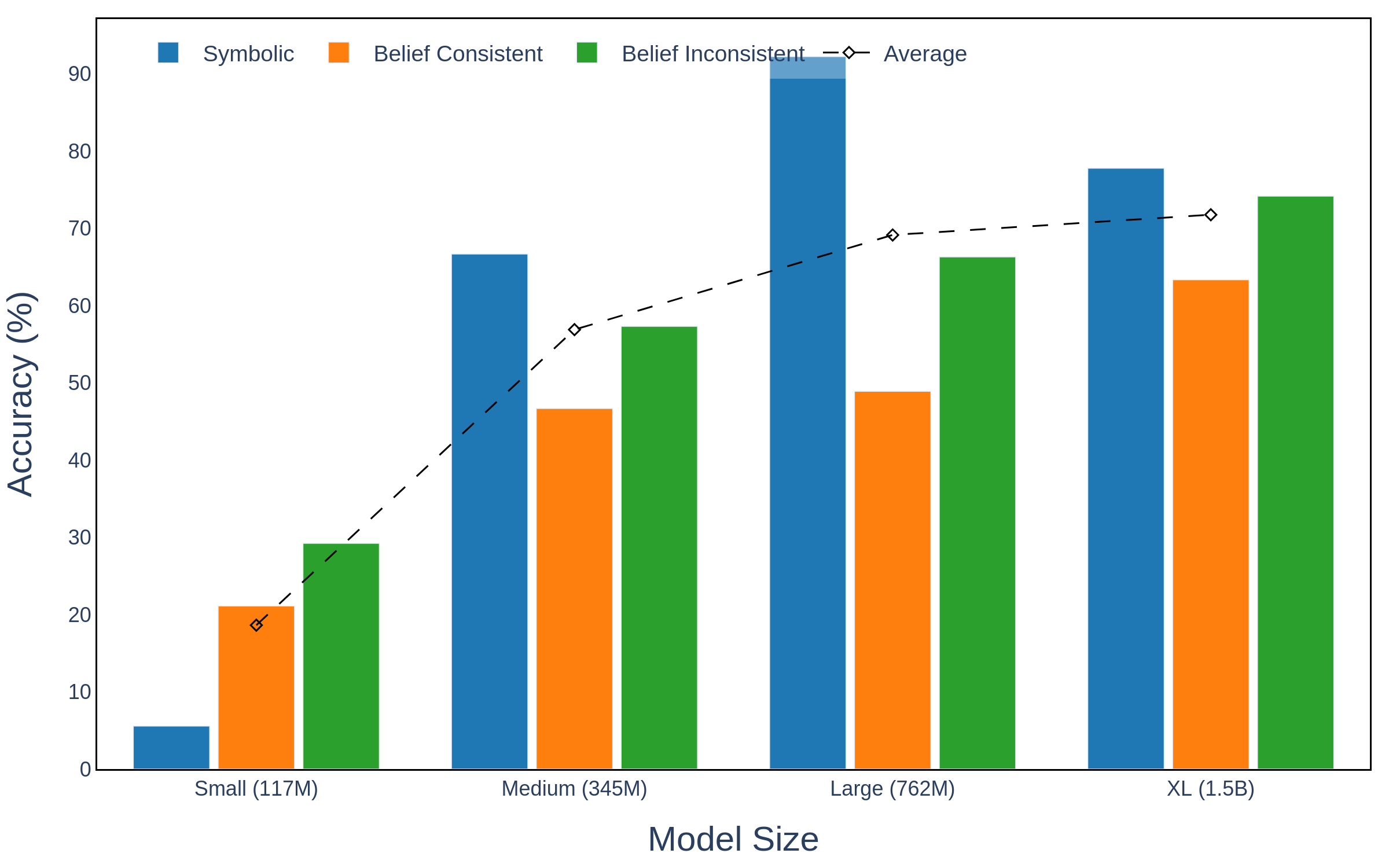
Figure 2: Accuracy on the syllogism completion task across all scales of GPT-2.
The symbolic circuit analysis reveals distinct phases in the reasoning process, including Long Induction, Duplication, Suppression, and Mover mechanisms. Each phase represents a unique aspect of the inference process, culminating in a prediction shift from the incorrect to the correct conclusion. This is facilitated by attention heads that aggregate, suppress, and move specific token information to the end token position.
Circuit Evaluation
The evaluation process involves circuit ablation studies to test the necessity and sufficiency of identified heads. The symbolic circuit is found to be essential for both symbolic and non-symbolic syllogistic arguments, though belief-inconsistent scenarios reveal limitations in exclusively symbolic reasoning mechanisms.
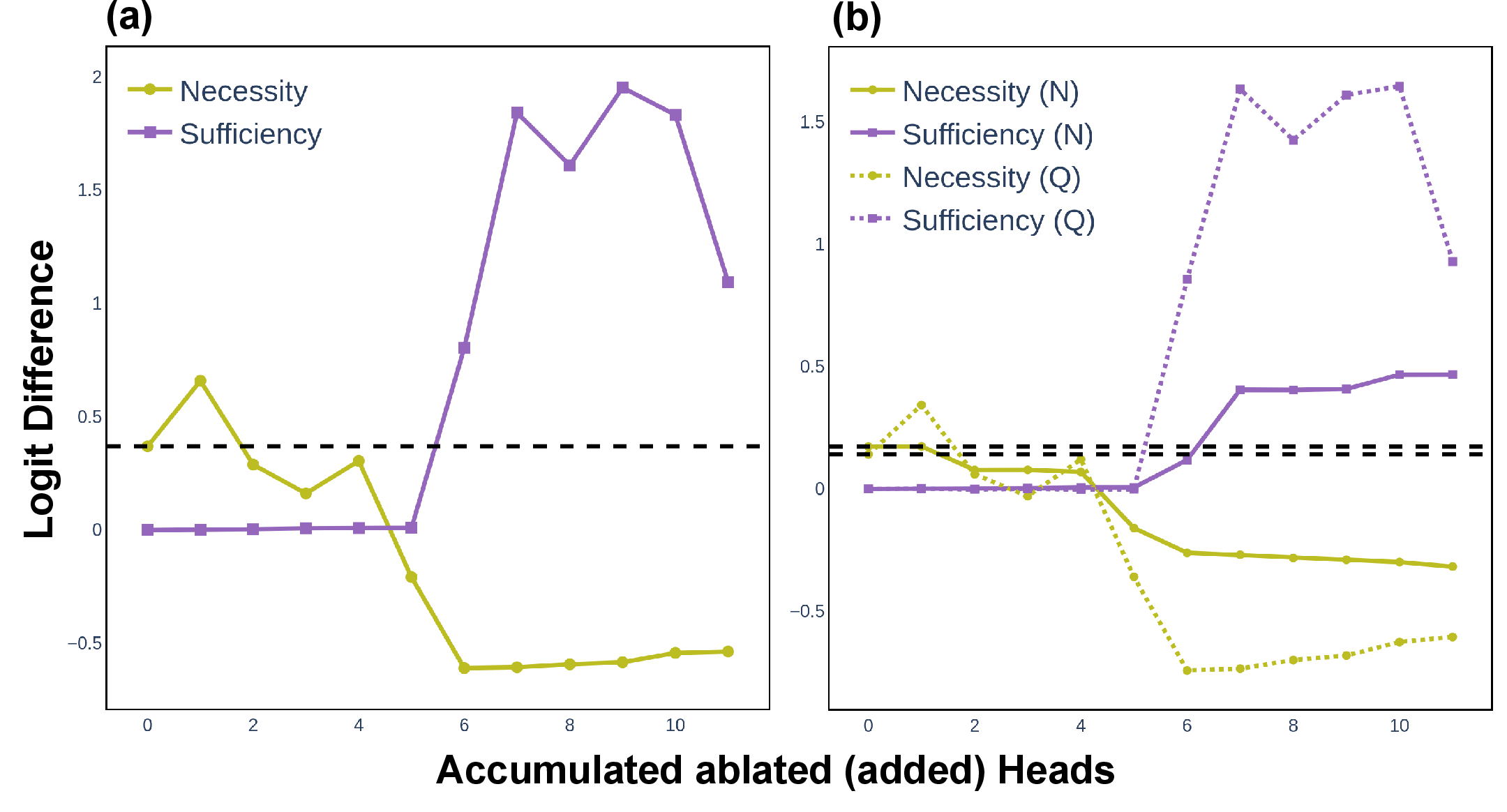
Figure 3: Circuit ablation results for correctness and robustness on the symbolic dataset.
Generalization Across Schemes and Model Sizes
The authors extend their analysis to various unconditionally valid syllogistic schemes, confirming that the symbolic circuit generalizes well across different form combinations. Moreover, the study examines the adaptability of these circuits across various GPT-2 model sizes, finding consistent suppression mechanisms and information flow.
Implications and Future Directions
The findings offer significant implications for understanding reasoning in LLMs. The ability to discern content-independent reasoning mechanisms intrinsically tied to models' interpretability and reliability. The study's results prompt further exploration into mechanisms that account for complex reasoning tasks and real-world application scenarios. Future work may focus on enhancing the disentanglement between reasoning and world knowledge to improve logical inference accuracy and robustness.
Conclusion
The paper successfully provides a mechanistic understanding of syllogistic reasoning in LLMs, highlighting transferable content-independent mechanisms overshadowed by world knowledge. Despite limitations in the scope of reasoning dynamics considered and computational constraints, the research lays a foundational framework for exploring interpretability and reasoning abilities in AI systems. These contributions are pivotal in advancing transparency and efficacy in LLM applications.