- The paper presents a theoretical analysis of training nonlinear Transformers to perform chain-of-thought inference with quantified sample complexity.
- It reveals that chain-of-thought outperforms traditional in-context learning under specific conditions related to context accuracy and attention dynamics.
- Numerical experiments confirm that attention mechanisms prioritize relevant context examples, offering actionable insights for optimizing multi-step reasoning tasks.
Introduction
The paper "Training Nonlinear Transformers for Chain-of-Thought Inference: A Theoretical Generalization Analysis" (2410.02167) undertakes a rigorous theoretical exploration into the training process of Transformers with nonlinear attention mechanisms for achieving Chain-of-Thought (CoT) inference capabilities. This study is pivotal as it provides a first-of-its-kind theoretical understanding of how Transformers can generalize CoT abilities, allowing them to adapt to unseen tasks through examples. The implications of accurately modeling the dynamics of CoT promise substantial advancements in the adaptability and reasoning capabilities of LLMs, which can revolutionize their practical applications across diverse domains, including natural language processing, multimodal learning, and beyond.
Chain-of-Thought Methodology
The CoT method involves augmenting a query with multiple reasoning examples that include intermediate steps. This method allows pre-trained models to infer K steps of reasoning without fine-tuning, and it surpasses the capabilities of traditional one-step In-Context Learning (ICL). Here, training involves supervised learning on CoT prompts and labels, aimed at allowing the Transformer models to develop reasoning abilities intrinsically through data-driven, gradient-based techniques.
The study addresses critical gaps by quantifying sample requirements for training a Transformer towards CoT abilities. It further demonstrates the CoT method's ability to generalize on multi-step reasoning tasks, even when examples include noise or are partially inaccurate. This ensures that the Transformer, once trained, can seamlessly extend its reasoning capabilities to previously unseen tasks.
Theoretical Results and Contributions
This work introduces several major contributions to the field:
- Training Dynamics of Transformers: The paper provides a quantitative analysis of the training dynamics on a single-head, one-layer Transformer aimed at achieving CoT abilities. It investigates required sample sizes, contextual examples, and training iterations, discovering that attention values of the trained model concentrate effectively on context examples sharing similar input patterns with the query (Proposition \ref{prpst: attn}).
- CoT vs. ICL in Generalization: A fundamental contribution is the theoretical characterization of conditions under which CoT outperforms ICL. Notably, successful ICL is contingent upon context examples having dominant correct input-label pairs (Condition 1), which is not a requirement for CoT.
- Guaranteed CoT Generalization: To achieve zero error in CoT using the trained model, the paper establishes that the number of context examples required is proportional to (α′τfρf)−2, where α′ is the fraction of similar input examples, and τf and ρf represent accuracy consistency and step-wise reasoning reliability, respectively.
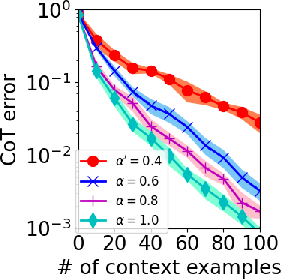
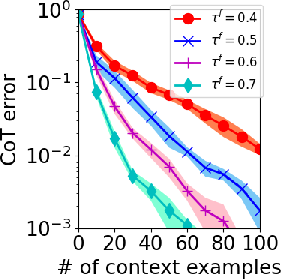
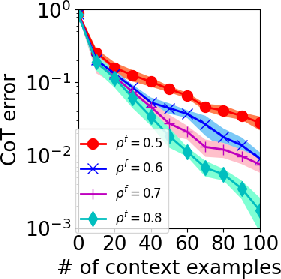
Figure 1: CoT testing error with different (A) α′ (B) τf (C) ρ<sup>f.</sup></p></p><p>ThesefindingsdelineateaclearpathwayforoptimizingCoTimplementations,ensuringrobusttrainingevenundervaryingcontextualaccuraciesorsampleinconsistencies.</p><h3class=′paper−heading′id=′numerical−experiments′>NumericalExperiments</h3><p>Thepaperincludescomprehensivenumericalexperimentsdesignedtovalidatethetheoreticalfindings.Syntheticdatabasedonwell−definedtheoreticalconstructsaffirmsthelowerboundsestablishedforsamplecomplexityanditerationrequirements,illustratingtheeffectsofmodifyingparameterslike\alpha',\tau_o^f,and\rho_o^f(Figure2).<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2410−02167/icl−alpha.png"alt="Figure2"title=""class="markdown−image"loading="lazy"></p><p><imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2410−02167/icl−tau.png"alt="Figure2"title=""class="markdown−image"loading="lazy"></p><p><imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2410−02167/icl−rho.png"alt="Figure2"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure2:ICLtestingerrorwithdifferent(A)\alpha'(B)\tau_o^f(C)\rho_of.
Additionally, training dynamics were explored, with focus on the attention mechanism's evolution throughout the training process. Results show models effectively prioritize context examples with relevant positional encoding and reasoning steps, as outlined in Figure 3.
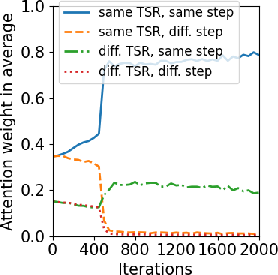
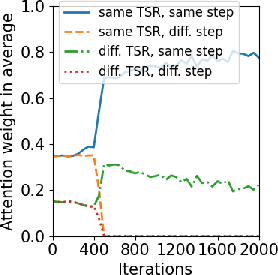
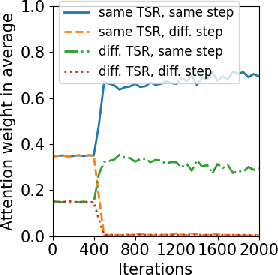
Figure 3: Training dynamics of Transformers. (A) Layer 1, Head 2 (B) Layer 2 Head 2 (C) Layer 3 Head 2.
Conclusion
This study exemplifies a groundbreaking effort to demystify and theoretically quantify the CoT inference within nonlinear Transformer models. While this paper primarily focuses on simplified single-layer architectures, its insights are broadly applicable, offering a compelling case for the operational efficiency of Transformers trained with CoT methodology. Future work could extend these findings into practical, multi-layer architectures, integrate more complex data models, or explore context-driven task generation, further enhancing the capabilities and accuracy of AI-driven reasoning systems.