- The paper introduces ALTA, a compiler-based framework that maps symbolic ALTA programs to Transformer weights, enhancing expressivity for dynamic control tasks.
- It outlines a structured execution pipeline mimicking Transformer forward passes, which aids in systematic debugging and model interpretability.
- Empirical evaluations on parity and compositional tasks show that ALTA improves generalization and algorithmic learning through symbolic supervision.
Introduction
This paper presents ALTA, a novel framework leveraging a bespoke programming language designed to provide a finer understanding of how Transformer models can express certain tasks. Expanding upon prior efforts like RASP and Tracr, ALTA allows for the interpretation and mapping of symbolic programs directly onto Transformer weights, aimed primarily at improving our grasp of the expressivity and learnability of such models. With ALTA, the emphasis is on the ability to express dynamic control operations, like loops, within the structure of Transformers, especially Universal Transformers. By employing a more structured and symbolic approach to parsing and representation, ALTA endeavors to bridge the dissonance between what Transformers theoretically can represent and what they successfully learn from end-to-end training.

Figure 1: Overview of ALTA. We propose a new programming language called ALTA, and a ``compiler'' that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by \citet{weiss2021thinking}.
Framework
Structure of ALTA Programs
ALTA programs are structured around variables, attention heads, and an MLP function specification. Variables are symbolic, with types including categorical or numerical, and embody the core state elements within the model, analogous to the residual stream in standard Transformers. Attention heads manage information flow across these variables, while the MLP function dictates how states transition based on predefined conditions, expressed as a series of sparse transition rules.

Figure 2: Generalization by length and number of ones for different parity programs in various settings. The training set consists of inputs of up to length 20 (and therefore up to 20 ``ones'') while the test set consists of inputs with lengths 21 to 40.
Execution and Compilation
Execution within ALTA is divided into the Initialization, Encoder Loop, Self-Attention, and MLP Function stages. The execution mimics the forward pass of Transformers, where the main divergence is in compiling these operations symbolically rather than numerically. This approach helps expose the interpretability of model actions at each layer, shedding light on computation tracebacks pertinent for debugging expressivity concerns or identifying learning gaps.
Expressibility and Learnability
The intersection of expressivity with practical learnability forms the crux of ALTA's approach. While ALTA expands expressivity via symbolic definitions and variable interactions, its true potential lies in promoting models that can generalize from data more effectively when informed by, or grounded on, symbolic intermediate supervision traces gathered during training.

Figure 3: Accuracy by length and number of ones for Transformers trained with trace supervision vs. standard, end-to-end supervision.
Experiments and Results
Parity and Compositional Tasks
The parity task showcases ALTA's utility by illustrating how sequence-based and algorithmic tasks previously challenging for Transformers can be symbolically encoded. Expressive strength is shown notably in tasks of determining sequence parity or handling conditional logic. The empirical evaluation underscores the need for attentive optimization on the symbolically rooted compilation strategies inherent in program design.
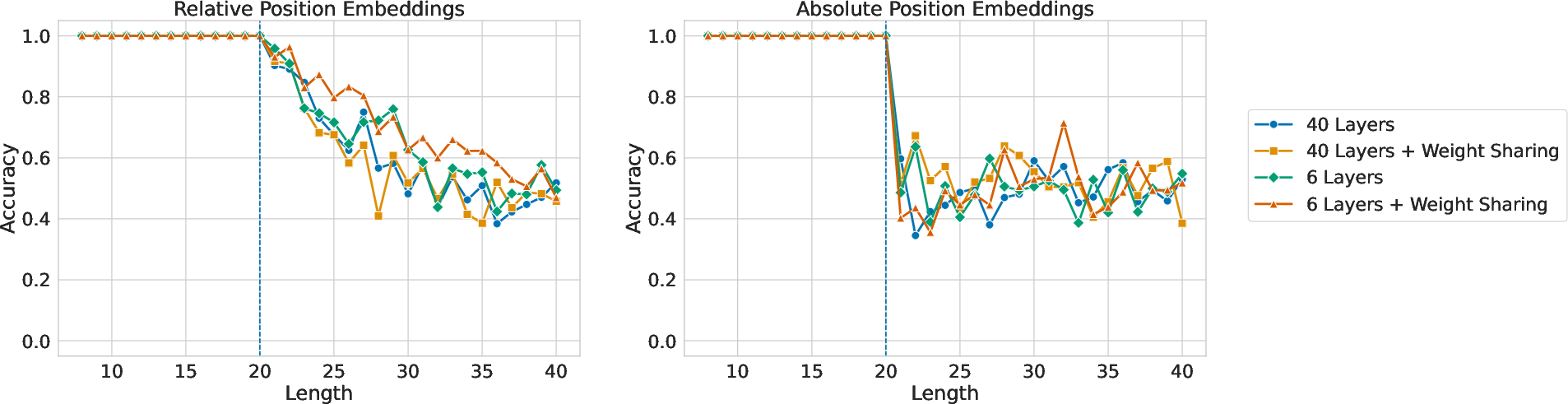
Figure 4: Accuracy by length for Transformers trained with standard supervision. There is some length generalization with relative position embeddings (left), but none with absolute (right).
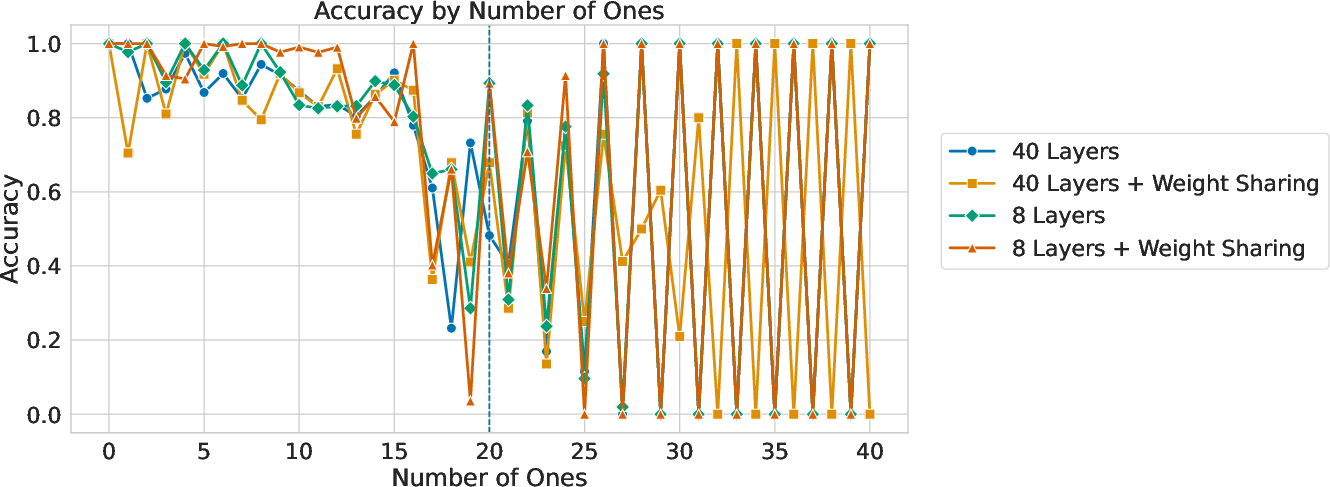
Figure 5: Accuracy by number of ones for Transformers trained with standard supervision using relative position embeddings. There is no generalization beyond 20 ones, which is the maximum number seen during training.
Discussion and Conclusion
ALTA evidences a dual role, both as a tool for assessment and a guide for systematic program cementation in Transformer architectures. By bridging the experimental findings with theoretical insights into model expressivity and learnability, ALTA enforces a structured methodology. This methodology highlights critical capabilities required for Transformer models to better learn algorithms from examples directly corresponding to real-world tasks.
In conclusion, ALTA lays the groundwork for future work wherein integration with larger models or further exploration across diverse task domains could open new avenues for enhancing model interpretability and heuristic generalization. The community is likely to find these strategies critical for fine-tuning both model design and deployment in practical AI implementations.