- The paper presents an intelligent assistant framework (AssistRAG) that enhances LLMs by integrating tool usage, action execution, and memory management.
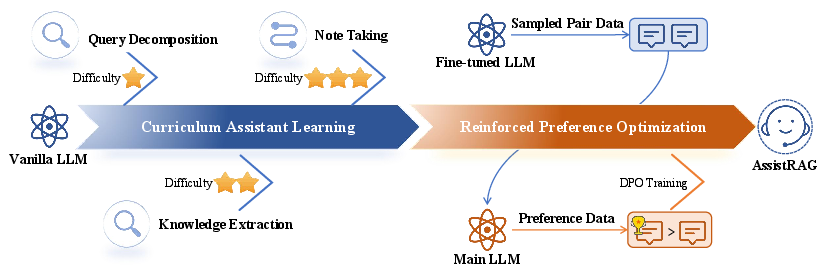
- It uses a two-phase training strategy—Curriculum Assistant Learning and Reinforced Preference Optimization—to optimize context retrieval and improve output accuracy.
- Experimental results on datasets like HotpotQA show substantial improvements in reasoning abilities and efficiency while reducing computational costs.
Introduction
The paper "AssistRAG: Boosting the Potential of LLMs with an Intelligent Information Assistant" introduces AssistRAG, an innovative framework designed to improve the capabilities of LLMs by incorporating an intelligent information assistant. Traditional retrieval-augmented generation (RAG) methods, such as "Retrieve-Read," struggled with complex reasoning tasks. AssistRAG addresses these limitations by integrating key tools for memory and knowledge management through a two-phase training approach: Curriculum Assistant Learning and Reinforced Preference Optimization.
AssistRAG Overview
The AssistRAG framework is developed to enhance LLM capabilities, particularly in reasoning and accuracy, by engaging an intelligent information assistant to support comprehensive data retrieval and processing.
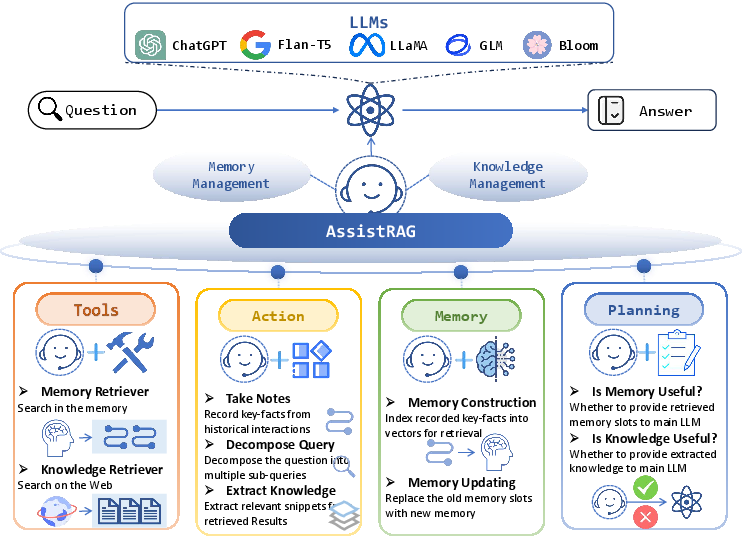
Figure 1: Overview of AssistRAG. AssistRAG enhances LLMs by providing an intelligent information assistant. Endowed with the ability of tool usage, action execution, memory building, and plan specification, it can achieve effective memory and knowledge management.
This framework distinguishes itself by utilizing a trainable assistant alongside a static main LLM. The assistant is responsible for memory and knowledge management, empowered through four core capabilities: tool usage, action execution, memory building, and plan specification. These capabilities ensure AssistRAG manages and provides the main LLM with pertinent information to facilitate complex task handling.
Methodology and Training
AssistRAG's training is executed in two phases:
- Curriculum Assistant Learning:
- This phase enhances the assistant's skills in note-taking, question decomposition, and knowledge extraction through progressively complex tasks, improving proficiency over time.
- Reinforced Preference Optimization:
Throughout the training, the assistant engages with specific actions, tools, and plans to ensure that the main LLM receives only the most relevant data, effectively supporting answer generation.
Experimental Results
AssistRAG was evaluated using datasets like HotpotQA, demonstrating significant performance improvements across complex question-answering tasks.
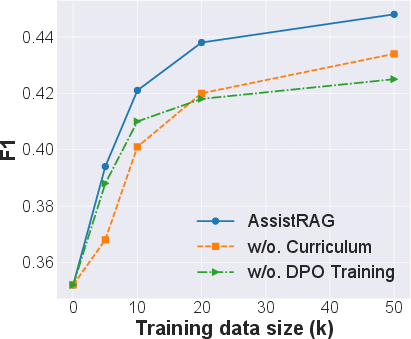
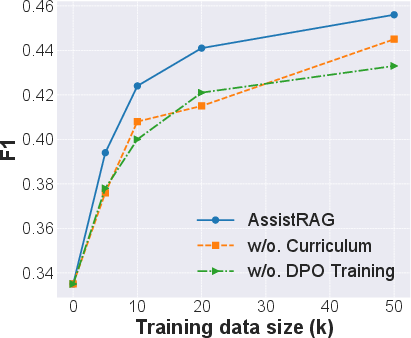
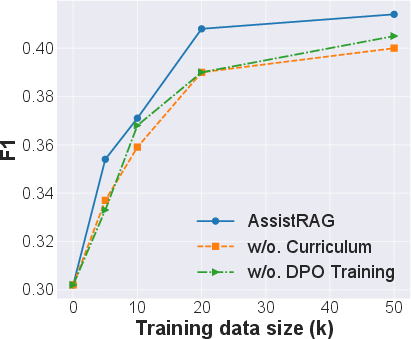
Figure 3: Performance evaluation on the HotpotQA dataset.
The experimental outcomes highlight AssistRAG's superior reasoning capabilities, showing marked improvements over existing benchmarks. Importantly, the benefits are notably pronounced in less advanced LLMs, accentuating AssistRAG's role in leveling the playing field between newer and older models.
Efficiency and Cost Analysis
In evaluating the efficiency of AssistRAG, comparisons were drawn against other RAG techniques. AssistRAG exhibits optimal balance in inference time, cost, and accuracy, showcasing its capability to provide accurate results with reduced token usage.
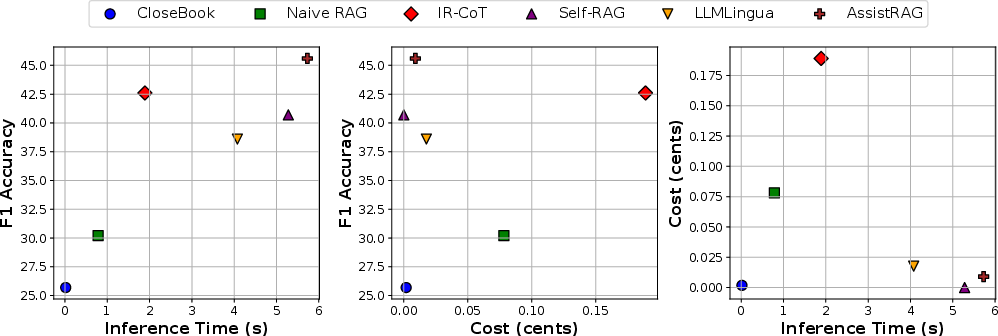
Figure 4: The relationships between inference time, cost, and F1 accuracy for different methods.
AssistRAG stands out by optimizing the use of computational resources, delivering consistent improvements in LLM outputs while managing computational expenses efficiently.
Conclusion
AssistRAG represents a significant advancement in integrating intelligent information retrieval with LLMs, markedly enhancing their ability to conduct complex reasoning tasks. Through a comprehensive training approach and efficient execution strategies, AssistRAG sets a new standard for retrieval-augmented LLMs. Future developments could extend its capabilities to incorporate long-text processing and personalized assistance, further broadening its application scope in AI.
The findings underscore AssistRAG's potential in refining LLM-supported applications, promising more accurate, context-aware generative outputs across diverse domains.