- The paper shows that rescaling full-sequence token probabilities outperforms prompt-based confidence measures for reliable Text-to-SQL generation.
- It evaluates methods like temperature scaling and isotonic regression using benchmarks such as Spider and BIRD to improve calibration error metrics.
- The findings imply enhanced operational efficiency and reduced human oversight, with potential applications beyond SQL query generation.
Calibration Techniques for Text-to-SQL Systems
This essay examines "Text-to-SQL Calibration: No Need to Ask -- Just Rescale Model Probabilities," a study focusing on calibration methodologies within the Text-to-SQL domain, applicable to various LLMs. The paper argues the importance of calibration in ensuring accuracy when converting natural language queries into SQL for databases and evaluates multiple approaches to enhance confidence measurement of generated SQL queries.
Calibration Techniques Explored
The calibration of LLMs specifically for Text-to-SQL tasks is imperative due to the generation complexity and domain variability. Calibration aims to quantify the uncertainty in a model's prediction, ensuring higher reliability. A traditional calibration approach is temperature scaling, which modifies probability distributions without altering model predictions, alongside isotonic regression which adjusts probability scores through non-decreasing step-wise functions. The paper contrasts these methods with prompting techniques that verify confidence post-generation through supplementary queries or verbalized probabilities.
A notable finding from this study is the superior performance of straightforward model-derived confidence scores based on full-sequence token probabilities. This method surpasses newer prompt-based strategies, which often utilize follow-up queries probing the model for confidence statements. Methods like the minimum token probability approach, suggested for determining sequence-level confidence, also receive detailed evaluation.
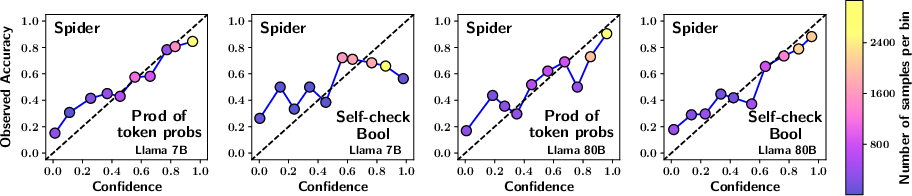
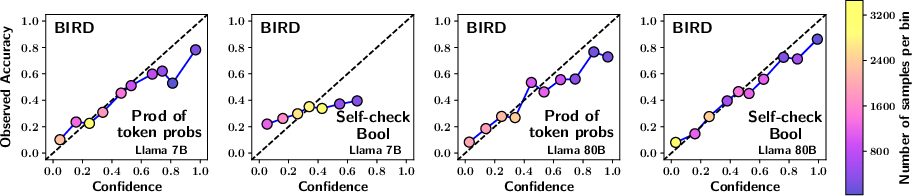
Figure 1: The reliability plots compare calibration across different methods and models. The top four plots use predictions from the Spider dataset and bottom four from the BIRD dataset. Plots have been generated with uniform binning and isotonic scaling. A well-calibrated plot aligns closely with the x=y line. Each point is color-coded based on the number of samples in the bin, as indicated by the colorbar on the right.
Evaluation and Results
The study performs extensive evaluations using two prominent benchmarks, Spider and BIRD, across a variety of LLM architectures, including models like GPT-4 and CodeS. Various calibration methods are statistically assessed by calibration error metrics such as the Brier score, AUC, and expected calibration error (ECE). In particular, the authors highlight that temperature-scaled pooled full-sequence probabilities yield improved calibration performance compared to other token aggregation strategies such as geometric mean, arithmetic mean, or minimum-based approaches.
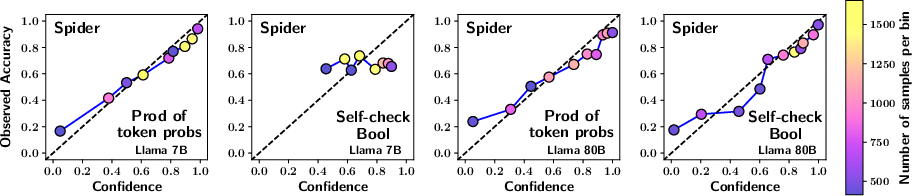
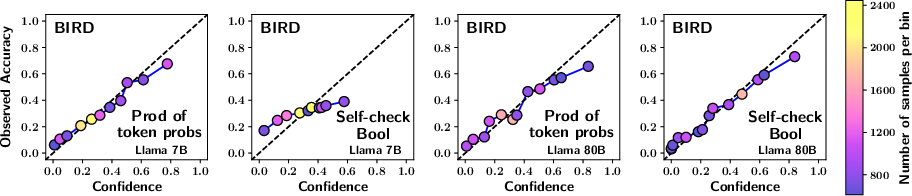
Figure 2: The plots have been generated using Monotonic binning in place of Uniform binning used in Figure 1.
Implications and Future Directions
The implications of this research are significant for enterprises employing Text-to-SQL systems. Improved calibration for SQL generation can allow automatic model execution with minimal human intervention, thereby optimizing operational efficiency and reducing human oversight costs. Future investigations might explore schema-specific calibration models, tailoring probabilistic adjustments based on domain-specific SQL tasks which could provide enhanced performance metrics across diverse database architectures.
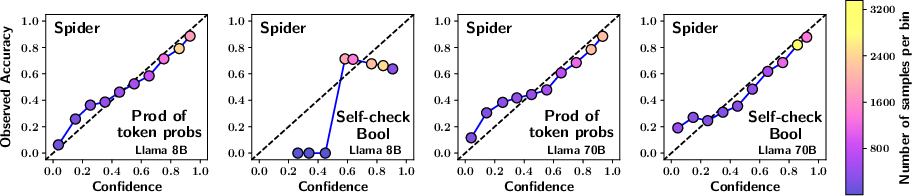
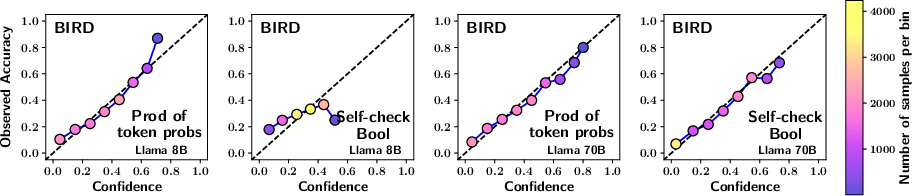
Figure 3: The plots have been generated using Platt scaling in place of isotonic scaling used in Figure 1.
The study also hints at broader applications of calibration methodologies beyond the Text-to-SQL domain, suggesting potential applicability in automatic code generation for languages like Python and C++. These areas could similarly benefit from the robust calibration measures highlighted in this research.
Conclusion
The research provides compelling evidence that simple rescaling of model probabilities can effectively calibrate Text-to-SQL outputs, outperforming recent prompt-based confidence measures. By leveraging systematic token-level probabilities rather than supplementary confidence querying, models can achieve higher reliability in SQL generation, ensuring trustworthiness within commercial database systems. Future work might explore cross-domain adaptation of these findings to broader NLP applications.