- The paper introduces HiddenGuard, an interpretable framework that extracts NSFW features from T2I model hidden states for enhanced prompt detection.
- It employs Linear Discriminant Analysis to project hidden representations, achieving over 95% detection accuracy and robustness against adversarial attacks.
- The framework provides dual-modal interpretability, offering token-level text analysis and visual NSFW content attenuation for comprehensive insights.
Detecting and Interpreting NSFW Prompts in Text-to-Image Models through Uncovering Harmful Semantics
Introduction
The proliferation of text-to-image (T2I) models such as Stable Diffusion and DALL·E has introduced significant ethical concerns, especially in the generation of Not-Safe-for-Work (NSFW) content. Existing detection methods often face challenges with accuracy and efficiency. This study introduces HiddenGuard, an interpretable framework that leverages the hidden states of T2I models to detect and interpret NSFW prompts efficiently.
Framework Design
The core innovation in HiddenGuard is its ability to extract NSFW features directly from the hidden states of a T2I model's text encoder. These features are used to detect NSFW prompts by analyzing the separably encoded semantics, offering a more robust and interpretable solution compared to existing prompt and embedding-based methods.
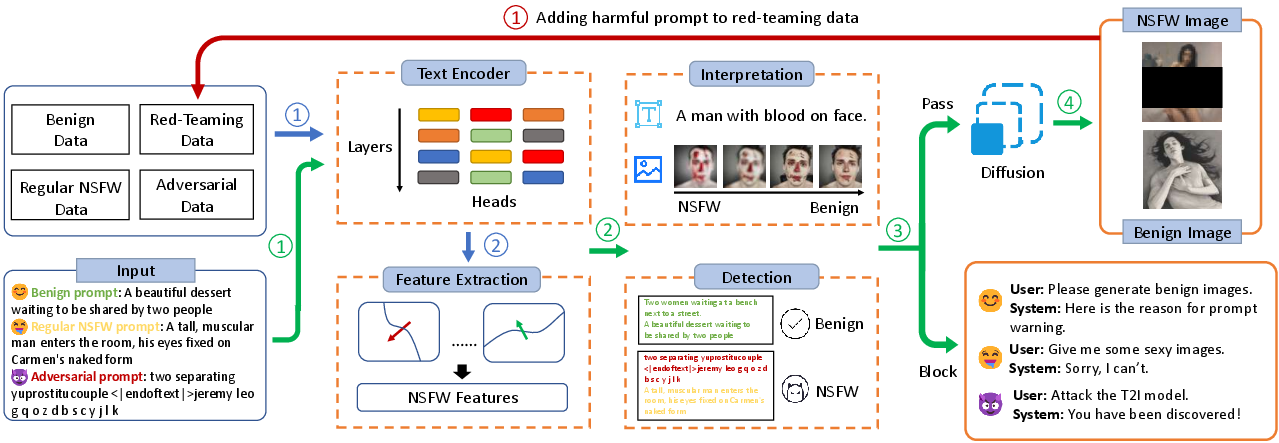
Figure 1: The overall framework of HiddenGuard, indicating the processes of training, inference, and data augmentation.
HiddenGuard operates through three main components: NSFW feature extraction, prompt detection, and interpretation. These components allow it to not only detect unsafe prompts but also provide real-time interpretation of the results, enhancing transparency and user understanding.
Feature Extraction and Prompt Detection
NSFW semantics often form linearly separable clusters within the internal representations of a model's layers and attention heads. HiddenGuard exploits this by identifying directional features within these hidden states that encapsulate NSFW semantics. This capability is achieved by projecting the representations onto NSFW feature directions, calculated through Linear Discriminant Analysis (LDA).
For practical deployment, NSFW scores are computed based on the response of these projections across layers and heads. The aggregate score determines whether a prompt is likely to generate NSFW content.
Figure 2: PCA maps of hidden states from different layers and different heads.
Interpretability and Real-Time Interventions
A critical aspect of the HiddenGuard framework is its dual-modal interpretability, which offers insights into both text and image domains.
Textual Interpretation: HiddenGuard identifies the specific tokens within a prompt contributing to NSFW content by examining attention weights and the alignment of token representations with NSFW directions.
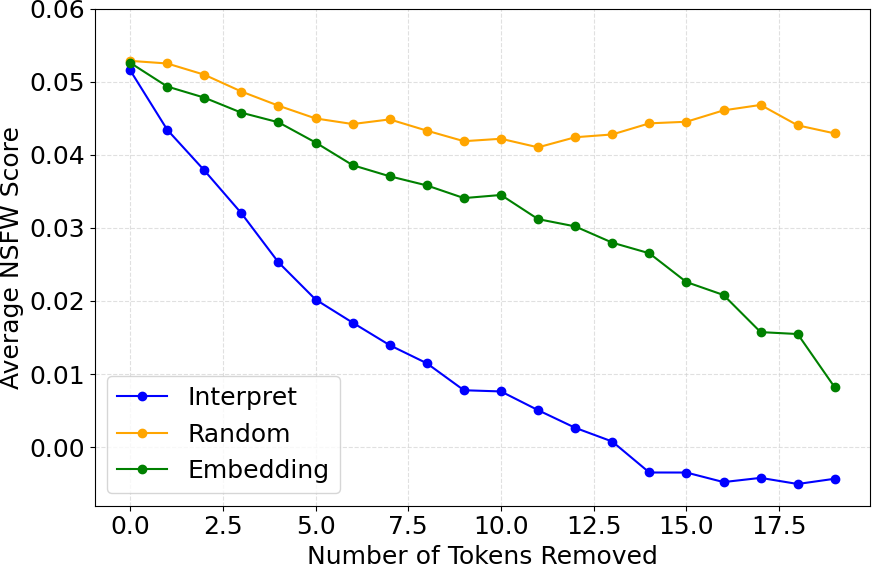
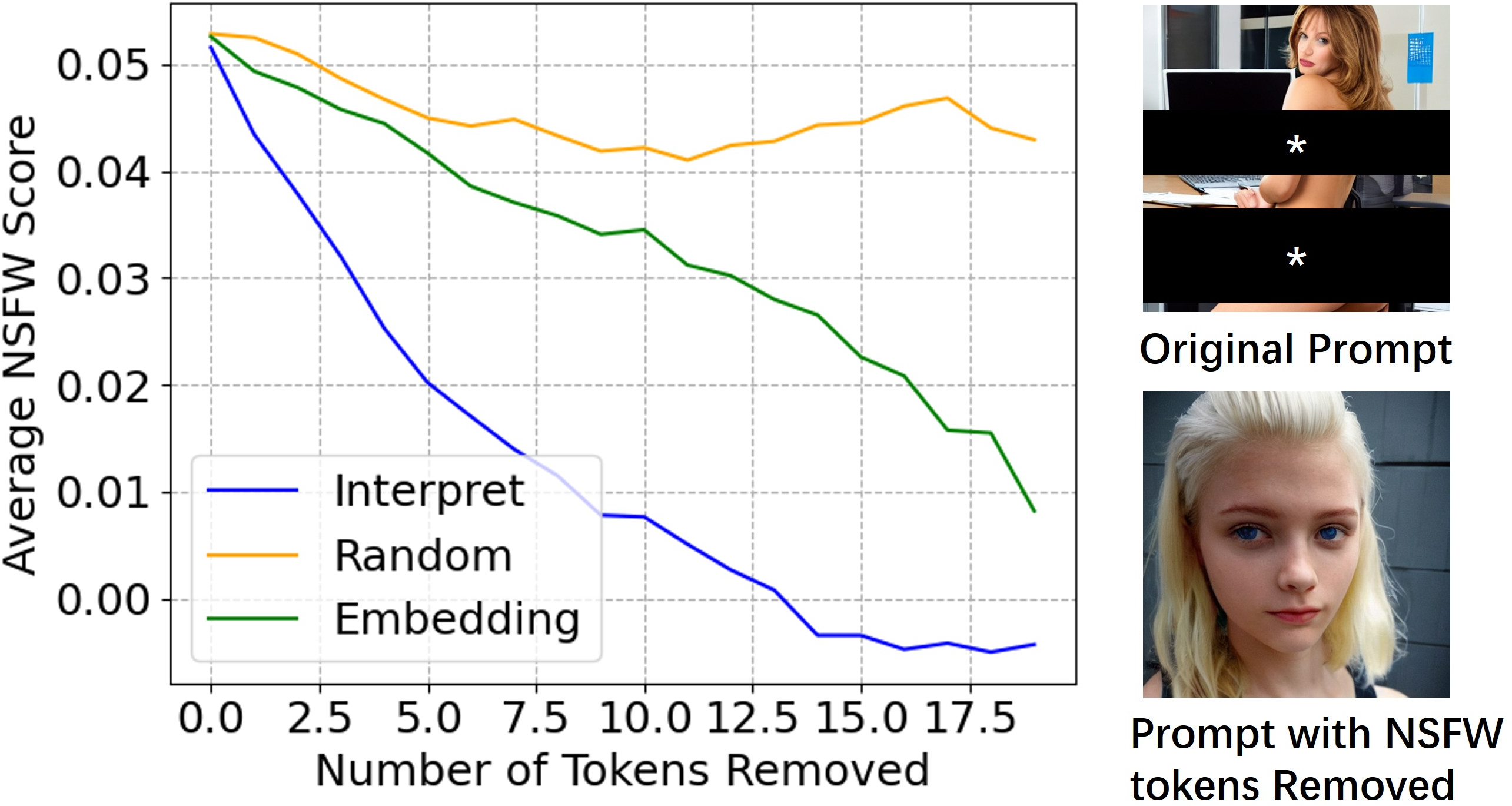
Figure 3: Text-based interpretation showcases token contributions to NSFW semantics.
Image Interpretation: By progressively attenuating NSFW semantics within the embeddings, HiddenGuard generates a series of images that transition from potentially unsafe to benign. This provides visual cues into how the perception of NSFW content changes as associated semantic features are diminished.

Figure 4: Image-based interpretation with Stable Diffusion v1.4 demonstrates removal of NSFW semantics.
Experimental Results
Experiments demonstrate that HiddenGuard surpasses existing commercial and open-source moderation tools, achieving over 95% accuracy across several datasets. The framework remains robust against known adversarial and unknown adaptive attacks, maintaining high performance even in few-shot and multilabel settings.
Conclusion
HiddenGuard presents a significant advancement in the detection and interpretation of NSFW prompts in T2I models. By leveraging hidden state representations and providing comprehensive interpretability, it addresses critical gaps in existing moderation methodologies. Future research could explore the extraction of other semantic concepts from hidden states, further enhancing model transparency and robustness.