- The paper introduces PromptSan, a prompt-level defense framework that leverages NSFW classifiers to sanitize harmful semantic tokens in text-to-image prompts.
- It employs two techniques—PromptSan-Modify for inference-time token editing and PromptSan-Suffix for adding trainable safe suffixes—to efficiently remove NSFW content.
- Experimental results on I2P and COCO-30k benchmarks demonstrate that PromptSan achieves superior NSFW removal rates while preserving image quality and semantic alignment.
NSFW-Classifier Guided Prompt Sanitization for Safe Text-to-Image Generation
Introduction
The proliferation of text-to-image (T2I) diffusion models, exemplified by Stable Diffusion, has enabled high-fidelity image synthesis from natural language prompts. However, these models are susceptible to misuse, particularly for generating NSFW (not safe for work) or otherwise harmful content, due to the presence of such material in their large-scale training datasets. Existing mitigation strategies—data cleansing, model fine-tuning, and post-generation filtering—either incur significant computational overhead, degrade generative quality, or are easily circumvented. This paper introduces PromptSan, a prompt-level defense framework that leverages NSFW classifiers to sanitize user prompts, thereby reducing the risk of harmful content generation without modifying the underlying diffusion model.
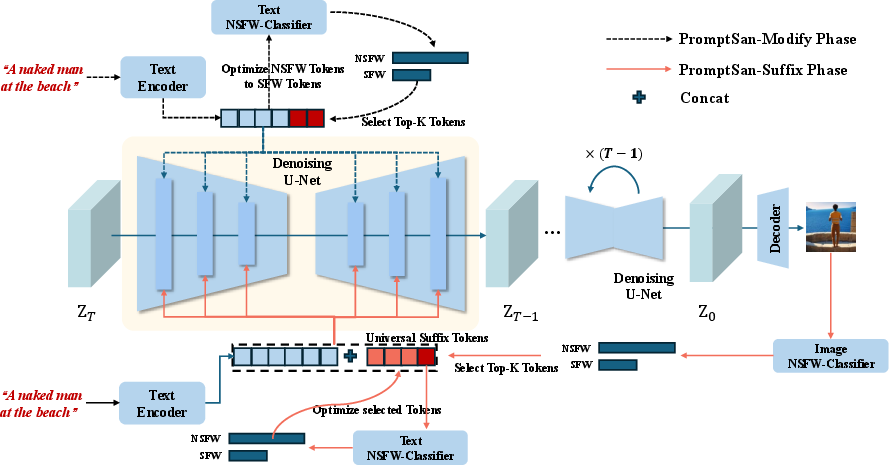
Figure 1: Overview of the PromptSan framework, illustrating PromptSan-Modify (inference-time token editing) and PromptSan-Suffix (trainable safe suffix insertion) for prompt purification.
Methodology
PromptSan-Modify: Inference-Time Token Editing
PromptSan-Modify operates during inference by identifying and modifying harmful semantic tokens in the input prompt. The process involves:
- Extracting token embeddings from the prompt using the model's text encoder.
- Passing these embeddings through a text-based NSFW classifier to compute a harmfulness probability.
- If the prompt is flagged as harmful, computing the gradient of the classifier's loss with respect to each token embedding.
- Selecting the top-p most sensitive tokens (by gradient norm) and iteratively updating their embeddings in the direction that reduces the classifier's harmfulness score, while masking unaffected tokens.
- Terminating the process when the prompt is classified as safe or after a fixed number of iterations.
This approach enables targeted prompt purification, preserving semantic coherence while neutralizing harmful intent.
PromptSan-Suffix: Trainable Safe Suffix
PromptSan-Suffix is a trainable sequence of tokens (the "safe suffix") appended to any prompt classified as harmful. The suffix is optimized offline using a two-stage process:
- For a batch of malicious prompts, concatenate the suffix and generate images using the frozen T2I model.
- Use an image-based NSFW classifier to select candidate suffix tokens that minimize harmfulness in the generated images.
- Refine the suffix using the text-based NSFW classifier to ensure the concatenated prompt is also textually safe.
The suffix is trained end-to-end, and during inference, is simply appended to any prompt flagged as unsafe, providing a lightweight and efficient defense.
Experimental Results
Quantitative Evaluation
PromptSan was evaluated on the I2P benchmark (4,703 inappropriate prompts) and the MS-COCO validation set (30,000 safe prompts). NSFW removal efficacy was measured using the NudeNet detector, while image quality and semantic alignment were assessed via FID and CLIP scores.
Qualitative Analysis
PromptSan variants consistently removed harmful concepts (e.g., nudity, violence) from generated images while maintaining visual fidelity. Notably, PromptSan-Suffix provided more thorough NSFW concept removal compared to direct token editing.
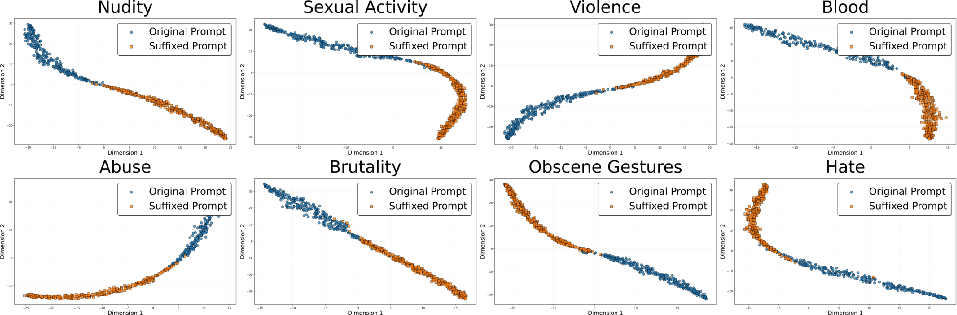
Figure 3: 2D t-SNE visualization of prompt embeddings before and after suffix insertion, showing clear separation and effective semantic migration to the safe region.
Ablation Studies
Diffusion Timestep
Applying PromptSan at different diffusion timesteps revealed that T=80 (out of 100 DDIM steps) achieves the optimal trade-off between NSFW concept removal and image detail preservation.

Figure 4: The effect of PromptSan injection at various diffusion timesteps, with T=80 yielding the best balance between safety and fidelity.
Sampling Thresholds
- For PromptSan-Modify, a nucleus sampling threshold of p=0.1 was optimal, as most NSFW prompts contain only a few critical tokens.
- For PromptSan-Suffix, a top-k value of 10 for suffix token selection provided the best generalization across prompt types.
Generalization to Multiple NSFW Concepts
PromptSan-Suffix was effective across diverse NSFW categories (blood, ghost, shocking, violence), consistently outperforming baselines in both harmful content removal and benign content preservation.

Figure 5: NSFW concept erasure for multiple harmful categories, with PromptSan-Suffix demonstrating robust removal capabilities.

Figure 6: Preservation of benign image content when PromptSan-Suffix is applied to safe prompts.
Integration Strategies
Combining PromptSan-Modify and PromptSan-Suffix (Modify-then-Suffix) provided slightly lower efficacy than using each method independently, while Suffix-then-Modify was less effective, likely due to interference in classifier interpretation.

Figure 7: Comparison of original, PromptSan-Suffix, Modify-then-Suffix, and Suffix-then-Modify outputs, highlighting the relative effectiveness of each integration strategy.
Prefix vs. Suffix
Training a safe prefix instead of a suffix yielded comparable NSFW removal performance, indicating that the position of the intervention (prefix or suffix) is not critical.
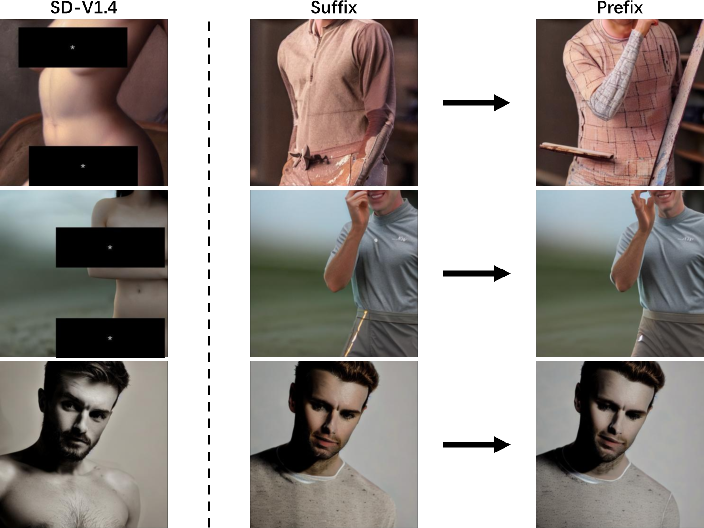
Figure 8: Nudity concept removal using both prefix and suffix, with similar effectiveness in eliminating NSFW content.
Implementation Considerations
- Classifier Design: The text NSFW classifier is a lightweight binary neural network (1.1M parameters) operating on 768-dimensional CLIP embeddings, supporting real-time inference. Separate classifiers are trained for each NSFW category.
- Training: Suffixes are optimized using AdamW, with 100 steps for the text classifier and 15 for the image classifier per iteration. Suffix length is fixed at 20 tokens.
- Inference: PromptSan-Modify uses 10 AdamW steps with a learning rate of 0.03; PromptSan-Suffix appends the pre-trained suffix based on detected NSFW category.
- Resource Requirements: The approach is computationally lightweight, requiring no model fine-tuning or retraining, and is compatible with existing T2I pipelines.
Limitations and Future Directions
PromptSan's efficacy varies by concept type, with weaker performance observed for violence-related prompts compared to nudity. Composite or multi-concept prompts may partially evade purification. Future work should focus on joint optimization of PromptSan-Modify and PromptSan-Suffix, as well as improved multi-concept classifier integration for more robust defense against complex harmful prompts.
Conclusion
PromptSan introduces a classifier-guided, prompt-level defense for T2I models, providing state-of-the-art NSFW mitigation without compromising generative quality or requiring model modification. Both inference-time token editing and trainable suffix insertion are effective, lightweight, and easily deployable. The approach generalizes across harmful concept types and preserves benign content, offering a practical solution for safe text-to-image generation. Further research is warranted to address multi-concept prompts and to refine cooperative strategies between prompt modification and suffix insertion.
