- The paper demonstrates that small language models (1-8B parameters) can match or exceed larger models by leveraging advanced training techniques and modular architectures.
- It details innovative approaches like knowledge distillation, progressive learning, and ensemble methods to optimize SLM performance and efficiency.
- The study highlights post-training strategies, including quantization and pruning, to enable effective deployment in resource-constrained settings.
Small LLMs (SLMs) Can Still Pack a Punch: A Survey
Introduction
The landscape of language modeling has been dominated by the quest for ever-larger models, driven by the belief that increasing the number of parameters yields superior performance. However, "Small LLMs (SLMs) Can Still Pack a Punch: A survey" (2501.05465) challenges this paradigm by highlighting the capabilities of models with 1 to 8 billion parameters. This survey provides a comprehensive overview of SLMs, illustrating their ability to match or even exceed the performance of larger models across various tasks. It categorizes SLMs into task-agnostic, task-specific, and domain-specific models and explores the techniques employed to optimize their performance while maintaining efficiency and cost-effectiveness.
Types of Small LLMs
Task-Agnostic SLMs: These models are designed to perform a wide range of tasks without specific tuning. Examples include TinyLlama, which, despite its 1.1B parameters, challenges LLMs in benchmarks like BoolQ and MMLU, and Mistral 7B, which leverages innovative attention mechanisms to outperform Llama models on reasoning tasks. The Llama series, especially Llama 2 and 3, serves as a benchmark for SLM performance, offering 7B to 405B parameter variants with notable success in multilingual tasks and reduced resource consumption.
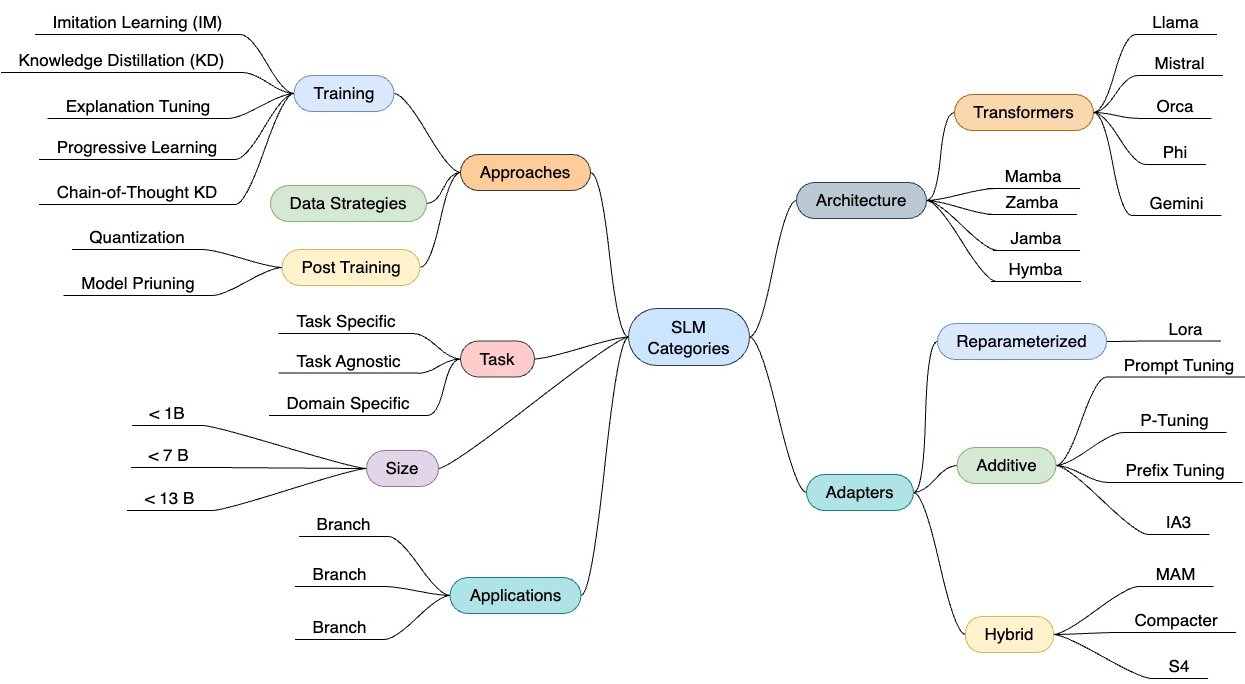
Figure 1: Mind map of topics covered in the paper.
Task-Specific SLMs: These models excel in particular domains by adopting specialized training strategies. WizardMath and Code Llama are noteworthy examples in mathematical reasoning and code generation, respectively, where they surpass much larger models like Llama 2 70B. Task-specific SLMs often employ techniques such as Chain-of-Thought (CoT) and knowledge distillation to bolster reasoning capabilities, as seen in WizardMath 7B's impressive performance on GSM8k.
Domain-Specific SLMs: SLMs tailored for specific industries or domains provide enhanced contextual accuracy. In the medical field, BioGPT, fine-tuned on PubMedQA, outperforms GPT-4 in some tasks despite its smaller size. Similarly, FinGPT addresses financial applications, and legal domain models like Lawyer LLaMA optimize legal text processing. These models illustrate the impact of domain-specific tuning in maximizing SLM utility.
Approaches to Creating SLMs
Training Techniques: The success of SLMs often hinges on innovative training methodologies. Imitation learning, progressive learning, and knowledge distillation are pivotal in transferring capabilities from larger models to SLMs. Explanation tuning, as demonstrated by Orca 1 and 2, enhances reasoning by capturing complex thought processes from LLMs like GPT-4. Such techniques allow SLMs to achieve competitive performance with far fewer parameters.
Modularized Training Techniques: Recent strategies involve combining multiple smaller models to mimic or exceed the capabilities of a single large model. Blended ensembles merge outputs from several SLMs, while Mixture of Experts (MoE) architectures, exemplified by Mixtral, optimize resource use by activating only parts of the model per task. These modular approaches enhance flexibility and efficiency.
Data Strategies: The quality of training data is crucial for SLM effectiveness. Synthetic datasets, like TinyStories for narrative tasks or TinyGSM for math problems, provide high-quality, targeted training material. This data-driven approach underscores the importance of curating diverse and representative datasets to exploit SLM potential fully.
Post-Training Optimizations
Quantization and Pruning: Techniques such as SmoothQuant and model pruning reduce computational requirements while preserving accuracy. These optimizations are essential in ensuring that SLMs can operate effectively in resource-constrained environments, like mobile devices or edge computing platforms.
SLMs as Draft Models: Speculative decoding employs SLMs to generate preliminary text sequences, reducing LLM inference costs. This method exemplifies SLMs' role in enhancing language processing efficiency, particularly when integrated into larger, multi-stage systems employing LLMs for final verification.
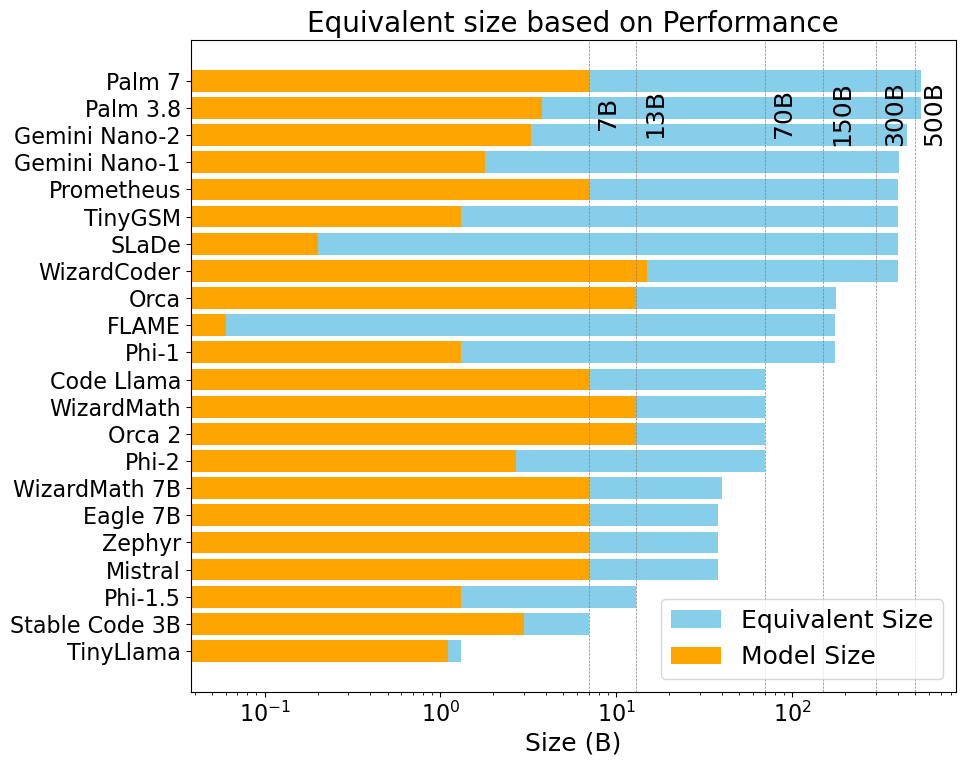
Figure 2: Equivalent sizes of SLMs based on performance benchmarks; more details in Table \ref{tab:model-specs}.
Conclusion
The survey illustrates that Small LLMs (SLMs) hold considerable promise for both general-purpose and specialized applications. Through state-of-the-art training techniques and optimizations, SLMs deliver performance on par with much larger models, challenging conventional scaling laws and emphasizing the value of data quality. As research progresses, further advancements in training, architecture, and deployment strategies are likely to enhance SLM performance even more, offering efficient solutions for a wide array of language processing tasks. The potential for SLMs to transform practical applications, especially in environments with limited computational resources, remains vast and largely untapped.
 Can Still Pack a Punch: A survey")