- The paper presents an empirical study evaluating 20 open-source small language models on five code generation benchmarks, revealing performance differences grouped by model size.
- It employs a unified zero-shot experimental setup to measure accuracy, VRAM usage, and inference time, thereby quantifying efficiency trade-offs.
- The study finds that optimized smaller models can rival larger ones, offering significant benefits for resource-constrained coding environments.
An Empirical Study of Small LLMs for Code Generation
Introduction
The paper "Assessing Small LLMs for Code Generation: An Empirical Study with Benchmarks" (2507.03160) presents a comprehensive empirical analysis of Small LLMs (SLMs) within the context of code generation tasks. With the growing utilization of lightweight models due to their efficiency, this study evaluates 20 open-source SLMs, each ranging from 0.4 billion to 10 billion parameters, across five diverse code-related benchmarks. This research aims to understand the balance between performance and memory efficiency offered by these models.
Methodology
The methodological approach comprises a structured evaluation pipeline divided into three phases: model and benchmark selection, unified experimental setup, and systematic data analysis.
Model and Benchmark Selection
The study includes 20 open-source decoder-only SLMs, selected based on criteria such as release timeline, community engagement, and open-source licensing. These models are divided into three groups by parameter size for direct comparison:
- Group 1: Up to 1.5B parameters
- Group 2: More than 1.5B to 3B parameters
- Group 3: More than 3B to 10B parameters
Five benchmarks were chosen based on their ability to cover a wide scope of code generation tasks and support multiple programming languages. These include HumanEval, MBPP, Mercury, CodeXGLUE, and HumanEvalPack.
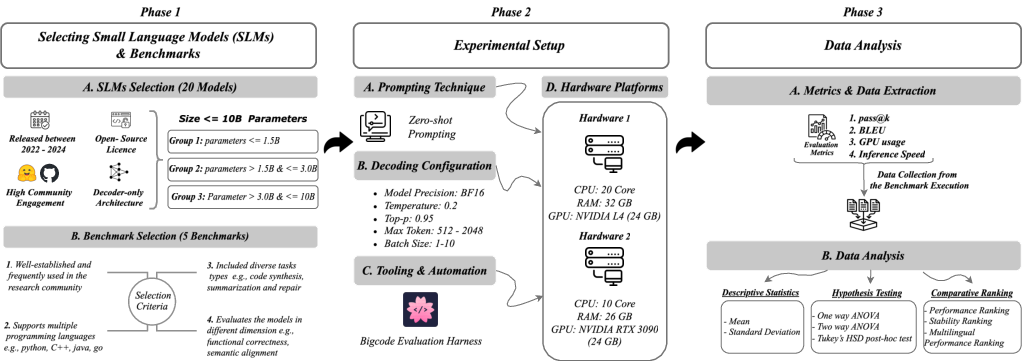
Figure 1: Overview of the research design and evaluation workflow.
Experimental Setup
The study employs a zero-shot prompting technique to assess model performance devoid of prior context, under specified decoding configurations. Two distinct hardware platforms with compatible VRAM and CPUs were used to ensure comprehensive evaluation of VRAM usage and inference time, managed by an evaluation framework for consistency.
Experimental Results
The experimental evaluation provides insight into the performance, efficiency, and multilingual capabilities of SLMs.
The results indicate that the largest models typically exhibit superior functional correctness. However, several smaller SLMs from Groups 1 and 2 achieve competitive accuracy, underscoring that robust design and optimization can compensate for smaller parameter counts. The study concludes that model size significantly influences performance across the three major coding benchmarks without being heavily dependent on benchmark variability.
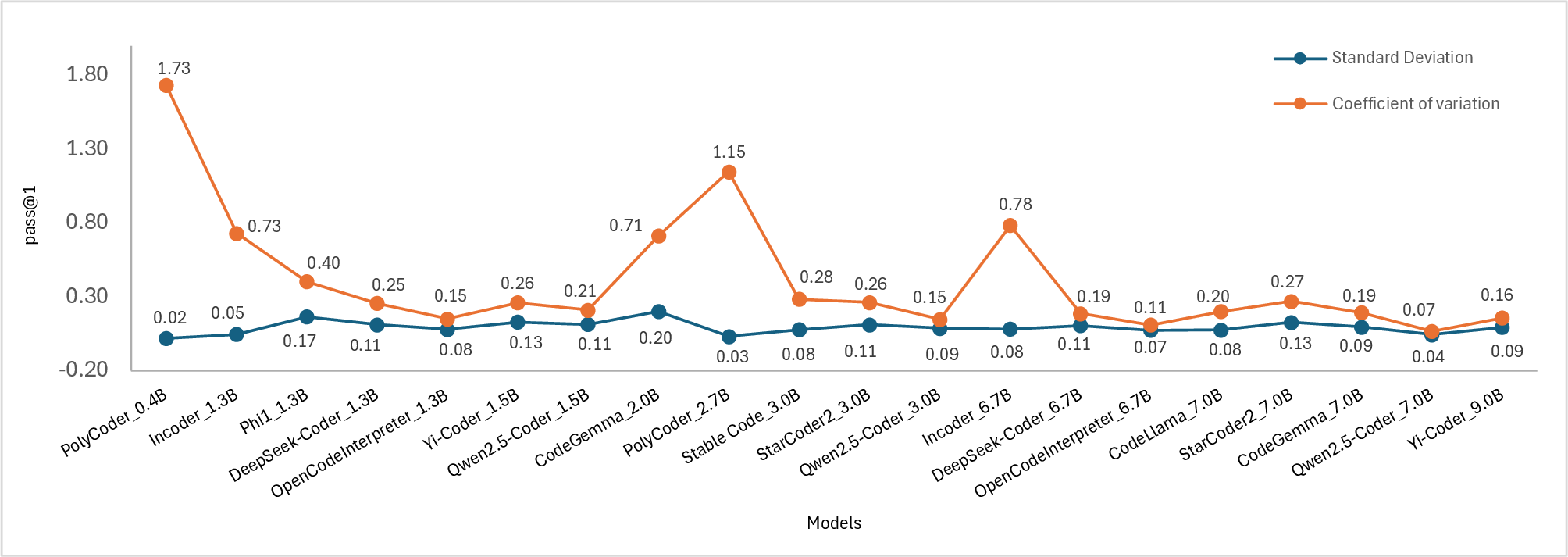
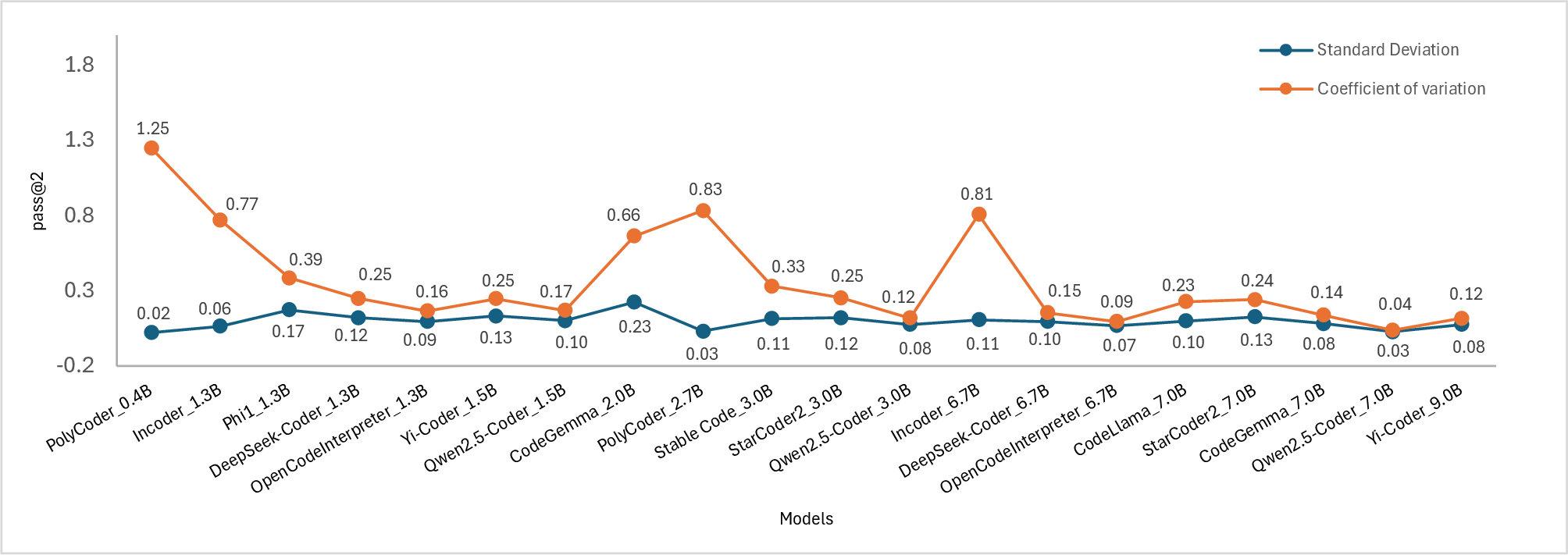
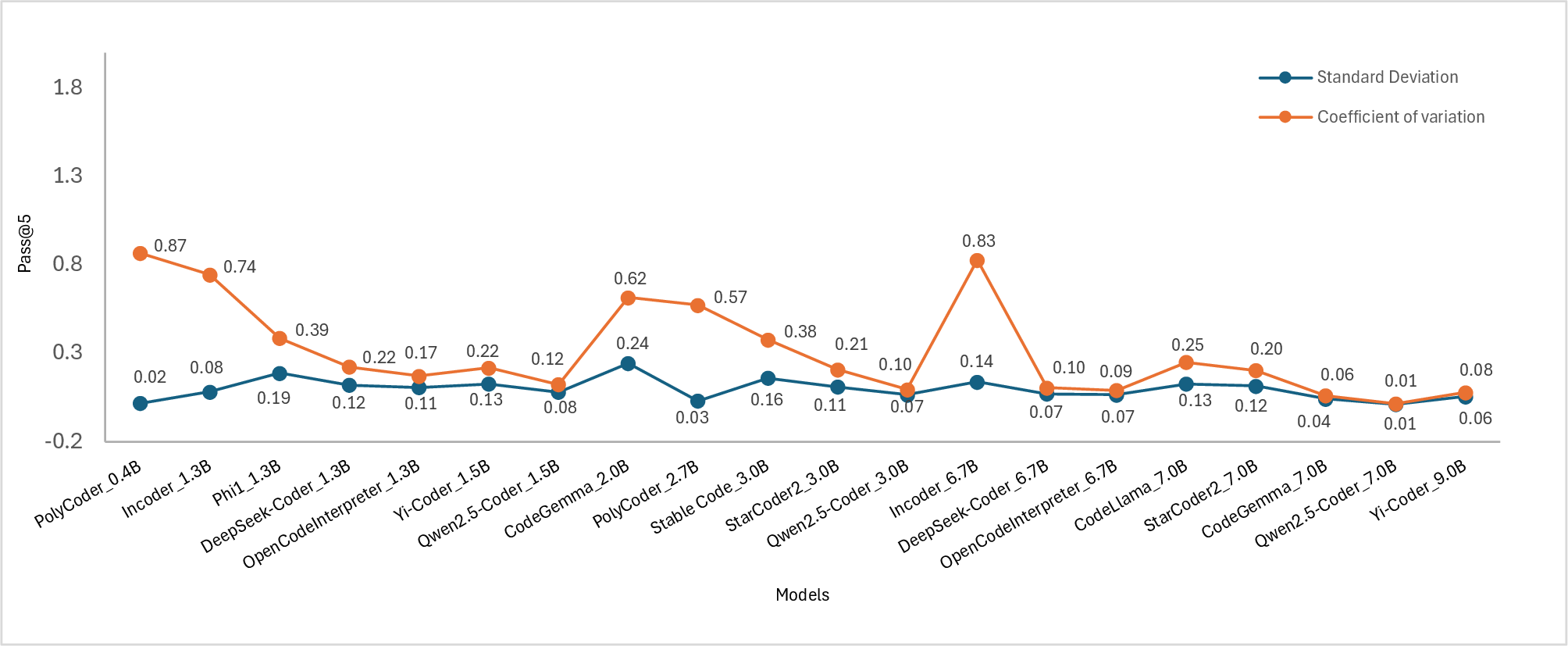
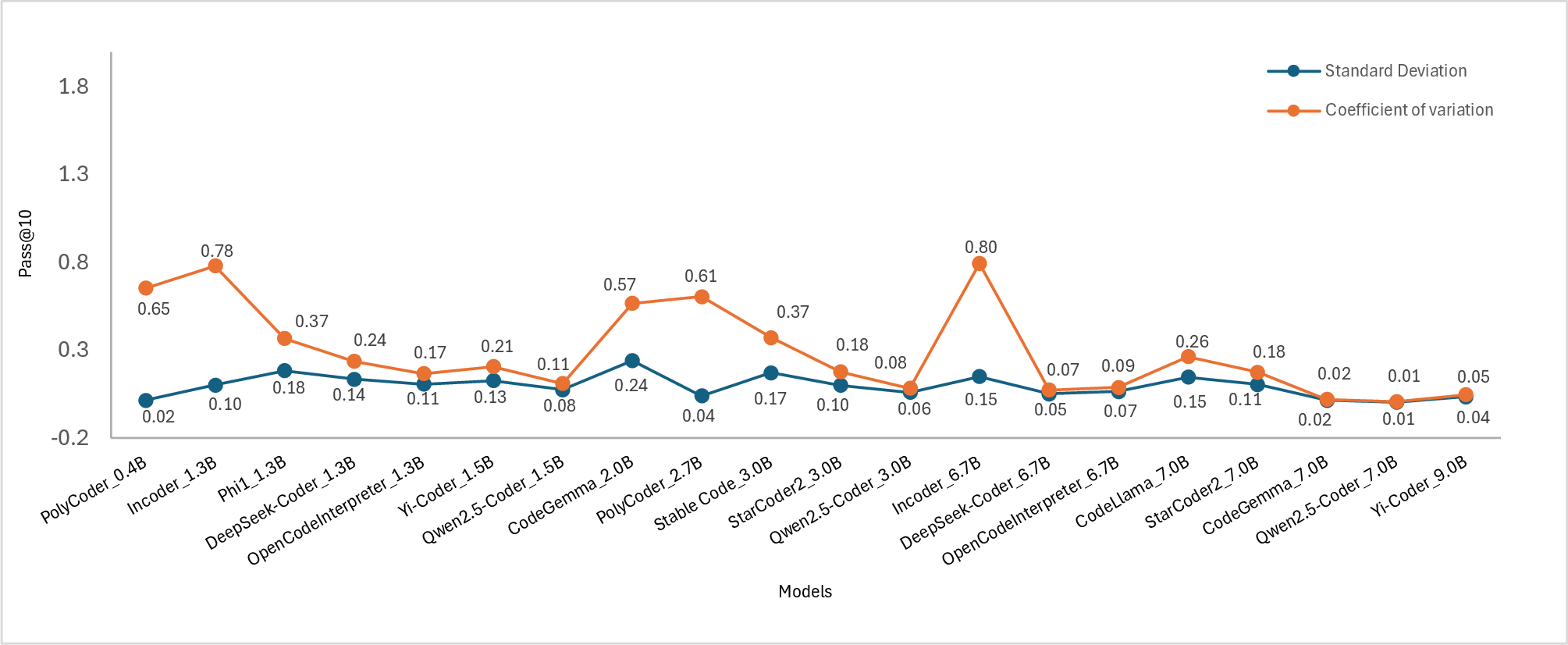
Figure 2: Standard deviation(SD) and coefficient of variation(COV) of the models. Subplots show the scores for (a) pass@1, (b) pass@2, (c) pass@5, and (d) pass@10.
The analysis reveals a non-linear relationship between model size and VRAM usage, highlighting the scalability challenges larger models face in resource-constrained environments. Significantly, some smaller SLMs demonstrate a favorable balance between accuracy and computational efficiency, making them ideal for memory-limited applications.
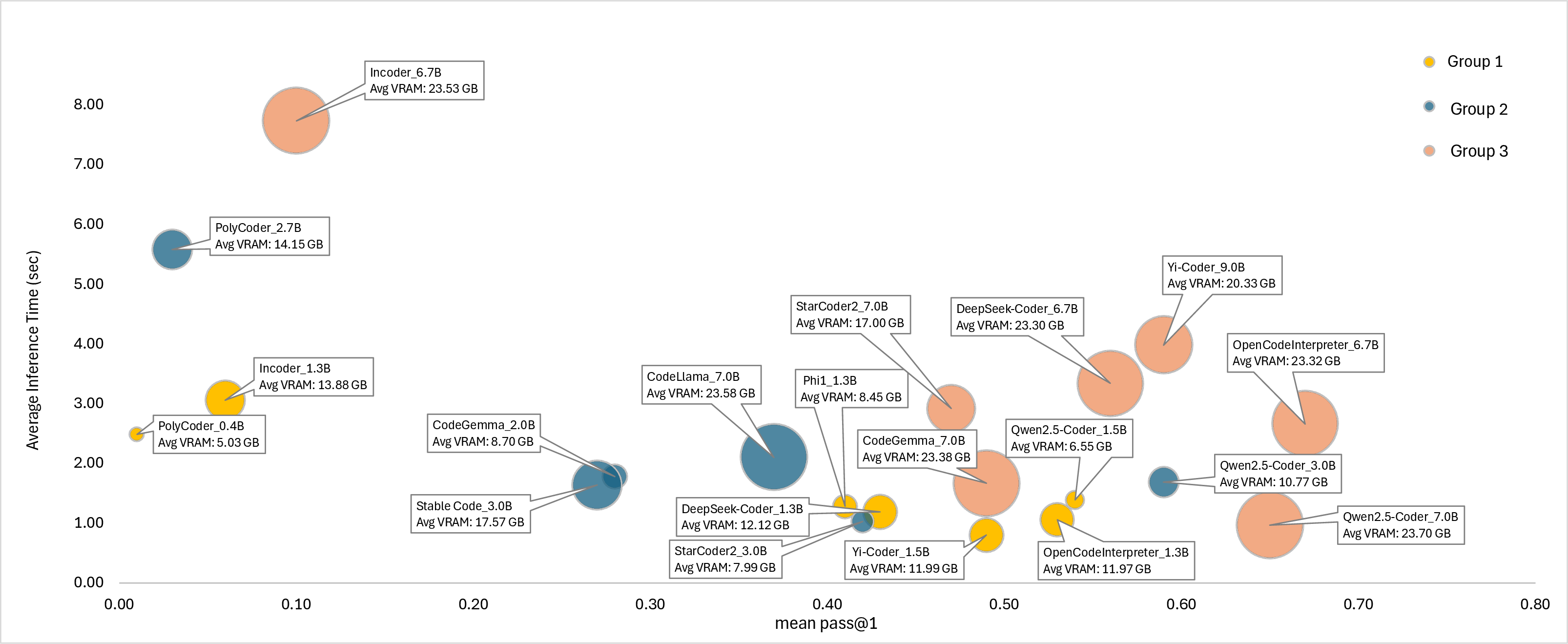
Figure 3: Performance-Efficiency Trade-offs: pass@1 vs. Inference Time with VRAM Usage.
Multilingual Consistency
Language-specific evaluations using benchmarks such as HumanEvalPack show better performance for languages like Python, Java, and PHP, whereas languages like C++ and Ruby present more challenges due to their syntactic complexity. Nonetheless, statistical analyses confirm that these performance variations across languages are generally insignificant.
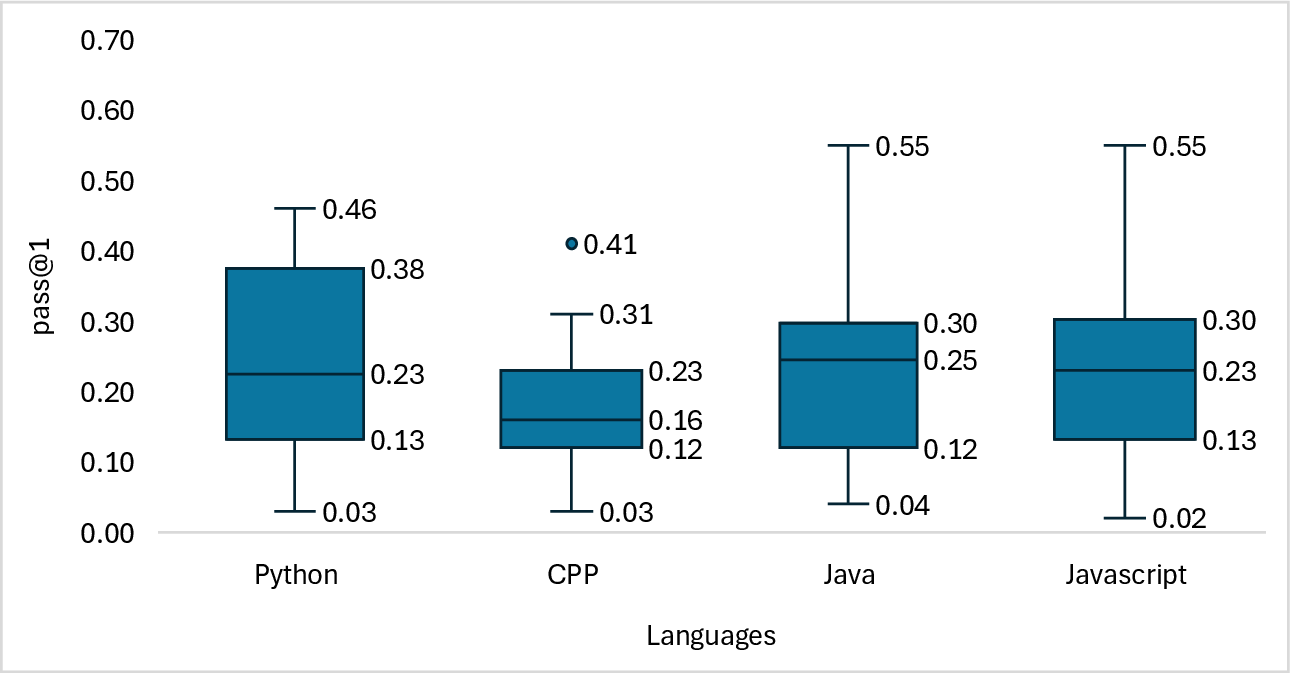
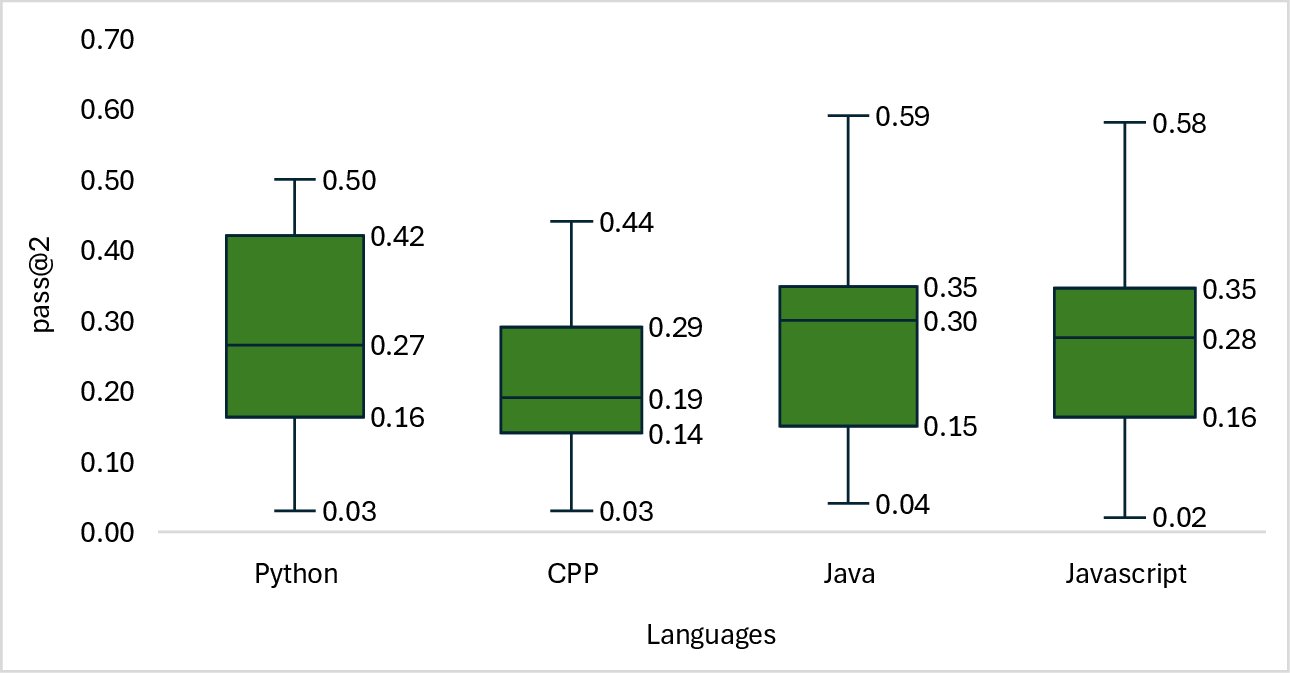
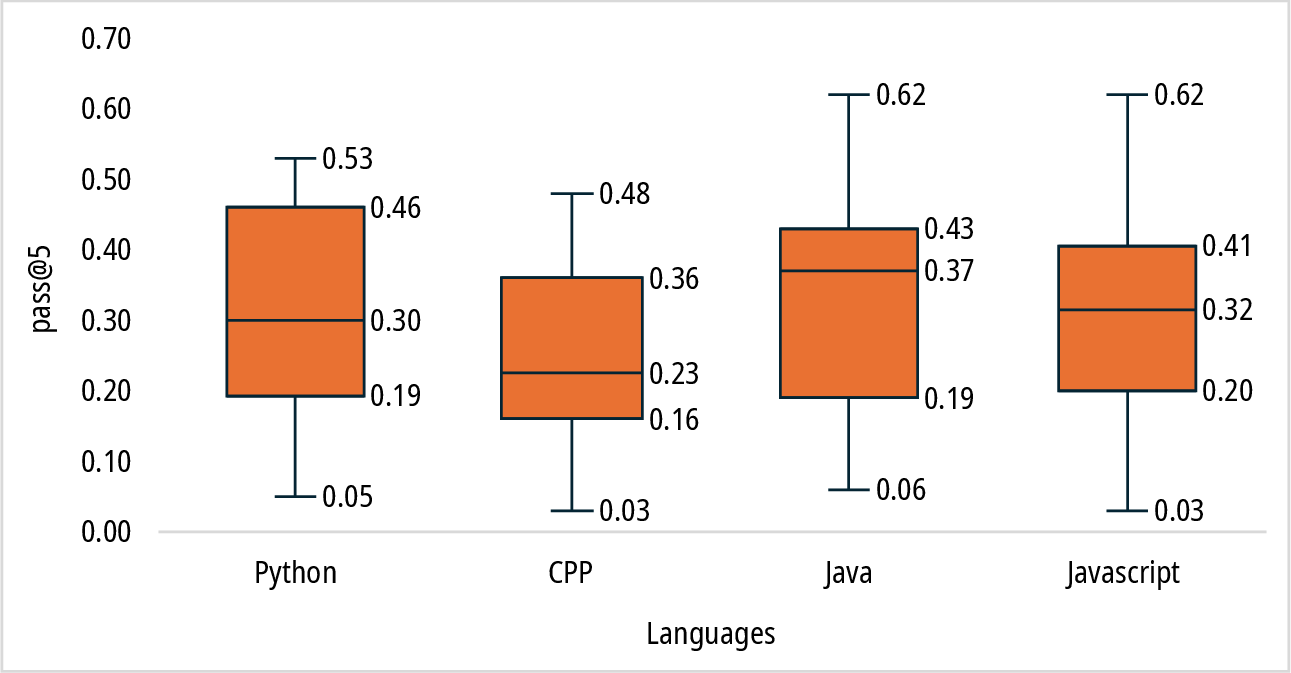
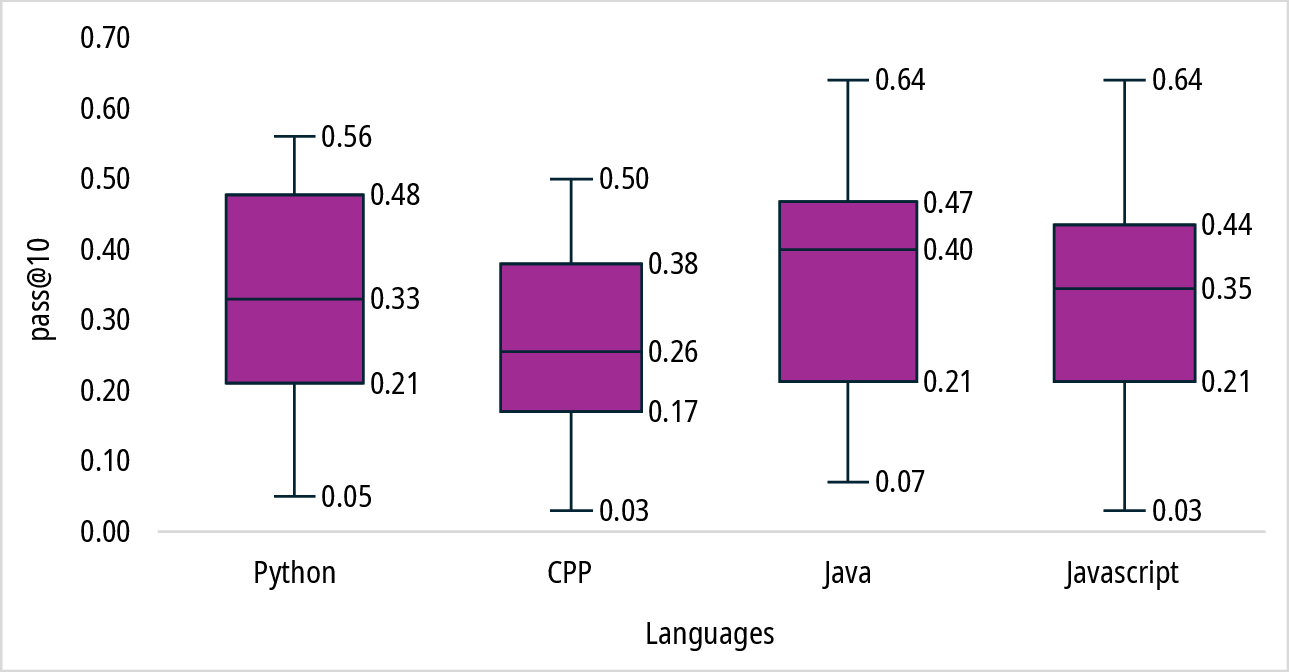
Figure 4: Distribution of pass@k scores across programming languages in the HumanEvalPack benchmark.
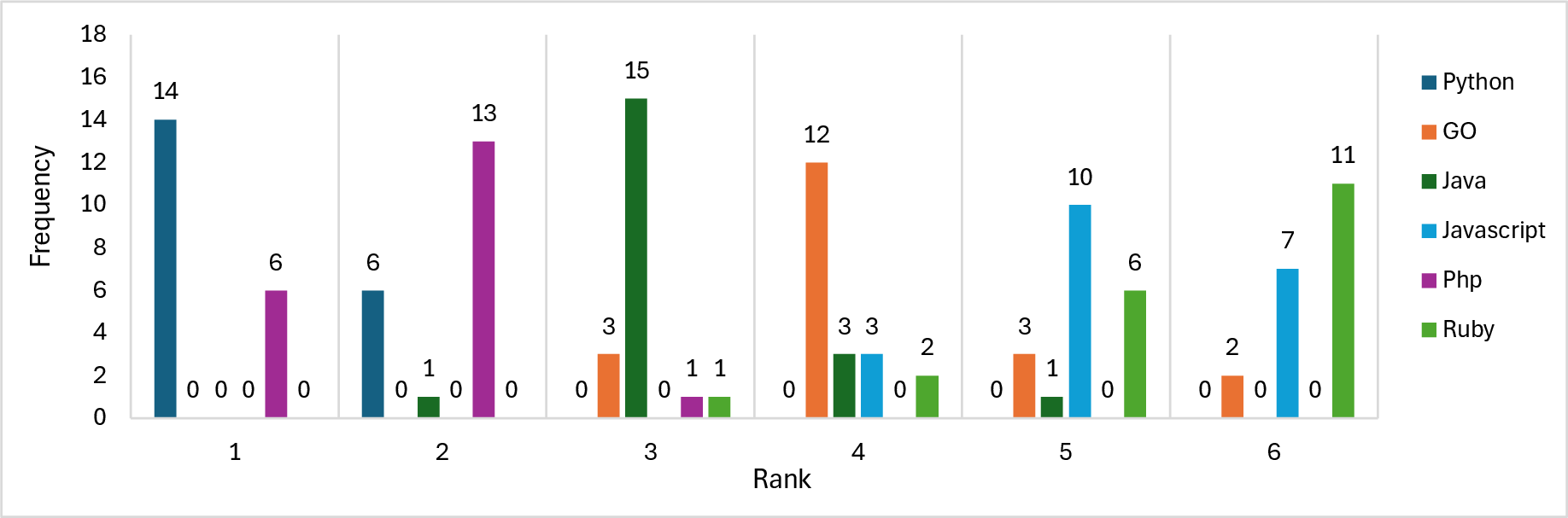
Figure 5: Frequency of programming languages appearing in top BLEU score rankings in the CodeXGLUE Benchmark.
Discussion
The study illuminates several key observations:
- Model Size vs. Performance: Smaller SLMs can approximate the performance of larger models when optimized effectively, suggesting potential benefits of architectural refinements over simple parameter scaling.
- Efficiency Trade-offs: Pragmatic deployment strategies might prioritize models demonstrating an optimal balance between accuracy and memory efficiency, pertinent for environments characterized by resource constraints.
- Multilingual Ambiguities: Although variations exist, the generalization across programming languages is broadly consistent, emphasizing a model's capacity to maintain efficacy in diverse coding environments.
Conclusion
This study advances our understanding of SLMs for code generation, revealing that strategic architectural enhancements and training regimens can achieve high performance even with limited parameters. Future investigations might focus on expanding model robustness and dynamic task adaptability beyond the constraints of current benchmark assessments. These findings underscore the potential of SLMs to reconcile performance, efficiency, and versatility in practical applications.