- The paper introduces ReFoRCE, a novel Text-to-SQL agent that uses self-refinement, consensus enforcement, and column exploration to effectively handle complex enterprise schemas.
- It presents innovative techniques like table compression and strict CSV-style format enforcement to mitigate long-context limitations and ensure consistent output.
- ReFoRCE achieves execution accuracies of 26.69% and 24.50% on Spider 2.0 benchmarks, demonstrating its potential for robust real-world data querying applications.
ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Consensus Enforcement, and Column Exploration
Introduction
The paper "ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Consensus Enforcement, and Column Exploration" tackles the challenge of retrieving structured data from vast databases via natural language queries. Current approaches struggle significantly with complex enterprise schemas exceeding 3000 columns and require detailed comprehension of varying SQL dialects and advanced query handling. The ReFoRCE methodology extends the capabilities of Text-to-SQL systems by introducing innovative techniques including table compression, format restriction, column exploration, and a rigorous self-refinement workflow to enhance performance on the Spider 2.0 benchmark.
Core Methodological Innovations
ReFoRCE addresses long-context limitations inherent to LLMs by implementing table compression, which merges tables with similar prefixes or suffixes. This strategy significantly reduces the size of contextual data presented to LLMs, effectively handling large database information and circumventing context window constraints.
To ensure strict adherence to expected output formats, ReFoRCE enforces a predefined answer schema restricting results to CSV-style outputs with explicitly defined columns. This guarantees the accuracy and consistency of results across varied cases, as seen in complex datasets.
Iterative Column Exploration
The agent employs an exploration strategy to dynamically generate SQL queries to comprehend database structures progressively. This process involves systematically querying potential columns, parsing execution feedback, and using this data to refine SQL generation adaptively.
Self-Refinement Workflow
ReFoRCE introduces a robust self-refinement workflow enhanced by CTE-based iterative refinement. This approach allows for dissecting complex SQL queries into simpler, manageable segments, fostering error diagnosis, and stepwise correction, improving overall query accuracy.
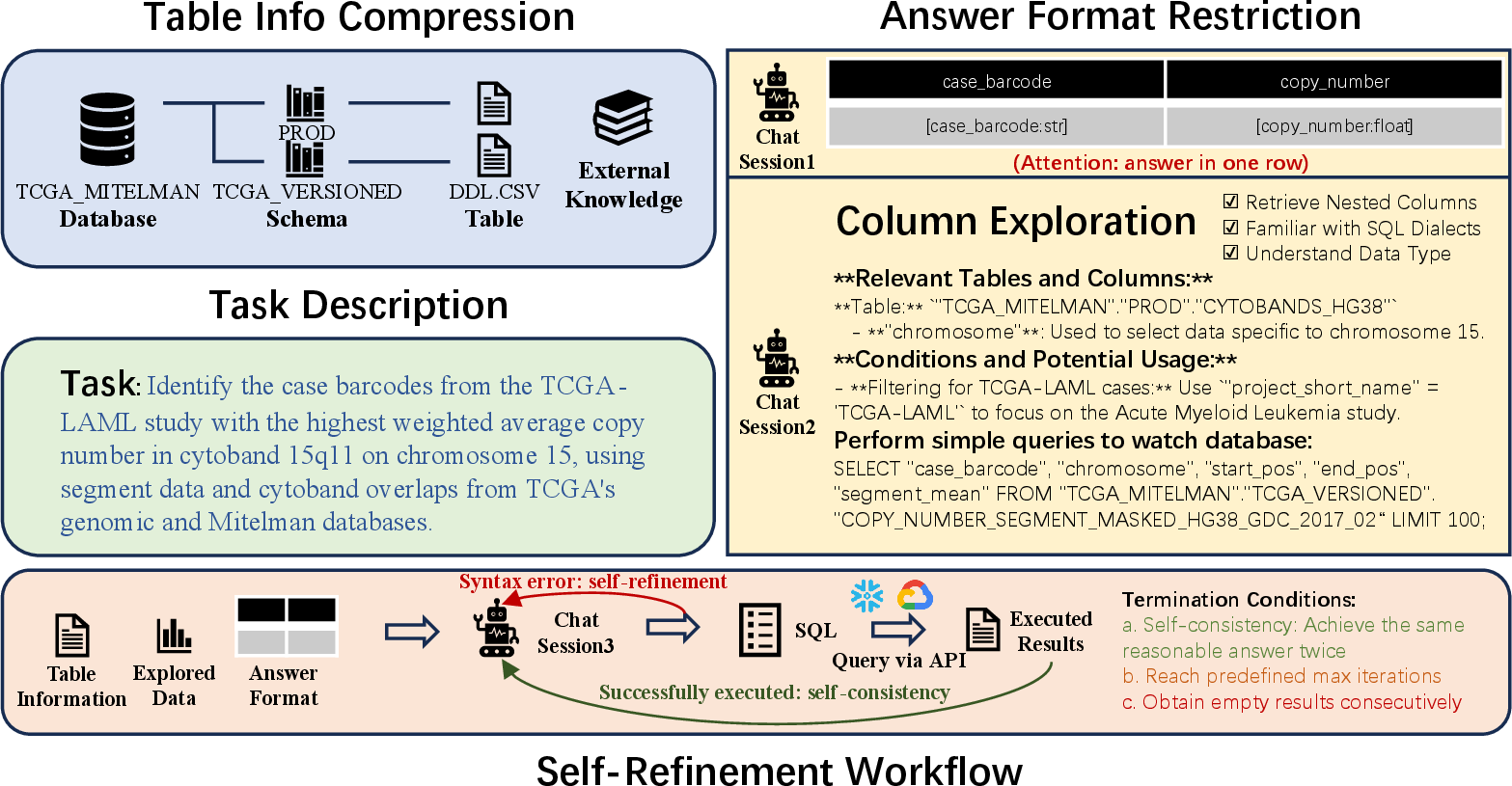
Figure 1: An overview of our Self-Refinement Agent with Format Restriction and Column Exploration (ReFoRCE) workflow.
Evaluations on the Spider 2.0 dataset, particularly its subsets Spider 2.0-Snow and Spider 2.0-Lite, underscore ReFoRCE's effectiveness. With execution accuracies of 26.69% and 24.50% respectively, ReFoRCE notably outperforms Spider-Agent and other baselines, marking a substantial advancement in text-to-SQL parsing in real-world simulations involving complex SQL dialects and nested data structures.
Future Implications
ReFoRCE demonstrates significant potential for practical applications in enterprise environments where accessing and interfacing with large-scale databases is critical. Future work might involve integrating advanced schema-linking capabilities and enhanced reasoning strategies, potentially utilizing MCTS or RL techniques, to address ambiguities and improve generalization across diverse database types.
Conclusion
ReFoRCE establishes itself as a leading framework in the field of Text-to-SQL systems, effectively bridging linguistic processing and database management through its innovative methodologies and refinement strategies. Its contributions leverage enhanced SQL dialect support, enabling robust interactions with multifaceted database contexts, paving the way for future advancements in AI-driven data querying systems.