- The paper presents Spider 2.0, a benchmark that evaluates language models on challenging enterprise-grade text-to-SQL workflows.
- It introduces real-world complexities such as vast schemas, diverse SQL dialects, and interactive codebase integrations to test dynamic reasoning.
- Results indicate that even advanced models struggle with enterprise demands, spurring the development of intelligent autonomous code agents.
Evaluating LLMs on Enterprise Text-to-SQL Workflows
Spider 2.0 is presented as a robust evaluation framework comprised of real-world text-to-SQL workflow issues rooted in enterprise-level database scenarios. These challenges are extracted from actual data applications, with databases often containing over 1,000 columns and supported by local or cloud systems such as BigQuery and Snowflake. Resolving these problems engages models in understanding database metadata, sql dialect documentation, and project-level codebases, requiring an interaction with complex SQL workflow environments. This involves processing extensive contexts, performing intricate reasoning, and generating multiple SQL queries with diverse operations that extend beyond traditional text-to-SQL challenges.
Spider 2.0 asserts a significant deviation from prior benchmarks, highlighting that existing LLMs, despite their remarkable capabilities in code generation, require substantial amelioration to meet real-world enterprise requirements. Critical facets for advancement include the development of intelligent, autonomous code agents for enterprise environments, supported by released codes, baseline models, and data.
Introduction to Text-to-SQL Challenges
Semantic parsing, or text-to-SQL technology, embodies a pivotal interface for data analysts interacting with relational databases, facilitating complex queries and business intelligence tasks. LLMs have optimally transformed natural language questions into SQL queries, especially highlighted by methods utilizing GPT-4 achieving high execution accuracy rates on benchmarks like Spider 1.0 and Bird datasets.
Contrastingly, these models, typically trained on non-industrial databases, lack robustness when handling the complexity of real-world data stored in large-scale schemas with intricate structures across diverse database systems. Real enterprise text-to-SQL workflows necessitate the utilization of codebases, external knowledge, and extensive contexts to construct sophisticated, multi-step SQL queries for data engineering pipelines, underscoring the need for a realistic benchmark reflective of enterprise-level benchmarks.
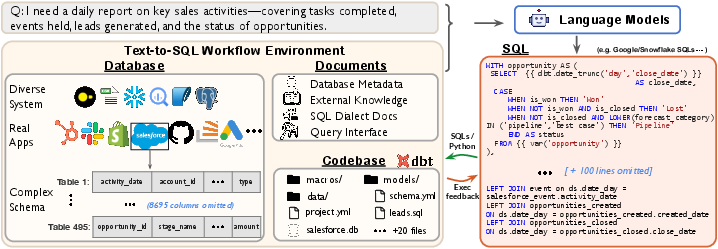
Figure 1: Spider 2.0 aims to evaluate LLMs on real-world enterprise-level text-to-SQL workflows. Solving each task requires understanding database metadata, consulting SQL dialect documentation, handling complex workflows, and performing intricate reasoning to generate diverse SQL queries.
The Benchmark Construction
Spider 2.0 offers a distinct agentic task setting, devoid of pre-prepared inputs or expected outputs, stressing dynamic interaction with codebases and databases. Models are additionally tasked to simulate rigorous real-world data workflows to enable not just query prediction but intricate data transformation and analytical insights extraction using SQL and command-line scripts.
In line with fostering advancements, Spider 2.0-lite and Spider 2.0-snow are introduced as simplified datasets. They present preprocessed database schema and readily available documentation to offer a more manageable scope for current text-to-SQL parsers, setting distinct challenges operational on diverse hosts, emphasizing SQL generation and interaction precision.
Experimental Evaluation
Evaluation on Spider 2.0 surfaces substantial room for model improvement, with the best code agent framework achieving only a marginal success rate. Fluctuations in performance among leading LLM-based methods denote considerable challenges faced in implementing these models within real-world enterprise SQL workflows. These evaluation discrepancies, particularly compared to Spider 1.0 and Bird benchmarks, reflect the elevated complexity and the diverse operational characteristics of databases and SQL queries in Spider 2.0.

Figure 2: Case study of two representative incorrect SQL predictions due to erroneous data analysis. (a): An example of incorrect data calculation, where quantiles were incorrectly divided based on the number of trips, rather than on the trip duration as required. (b): An example of incorrect planning, where the predicted SQL incorrectly sorted data by the number of users, rather than by the required retention ratio. The prerequisite for achieving this is to properly plan a sequence of CTEs. Additional examples of error cases across all categories are available.
Implications and Future Directions
Spider 2.0 boldly outlines the critical challenges and complexity inherent in real-world enterprise-level text-to-SQL benchmarks. Through encouraging a finer adjustment of LLMs adept at data engineering workflows, the framework sets a novel direction for enhancing LLM capabilities in realistic scenarios. These strides are envisaged to translate into the development of autonomous code agents and methodologies that are poised to navigate, explore, and operate within comprehensive and complex data systems dynamically.
As models advance, Spider 2.0 will serve as an invaluable catalyst, bridging the gap between existing academic solutions and their application in enterprise settings, thereby setting a new benchmark for research in text-to-SQL and semantic parsing technologies.
Conclusion
Spider 2.0's introduction reflects a significant advancement towards evaluating LLM capabilities in authentic, enterprise-grade scenarios. As existing models grapple with these workflows, Spider 2.0 illuminates paths for future developments in SQL generation through critical metrics and complexities inherent in real-world databases. The benchmark serves to stimulate progress towards robust, intelligent solutions capable of tackling enterprise-level challenges, effectively contributing to advancing text-to-SQL research landscapes.