- The paper demonstrates a novel data synthesis framework for text-to-SQL that generates SynSQL-2.5M with minimal human intervention.
- It uses LLMs to create complex, diverse databases and queries incorporating advanced SQL functions and chain-of-thought explanations.
- The OmniSQL open-source model, trained on the synthesized dataset, surpasses existing approaches on benchmark evaluations.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
The paper "OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale" proposes a novel framework for synthesizing large-scale text-to-SQL data. Addressing limitations in existing text-to-SQL approaches, the framework automatically creates highly diverse and realistic datasets without requiring extensive human intervention. This process culminates in the creation of SynSQL-2.5M, the first million-scale text-to-SQL dataset. The paper further presents OmniSQL, an open-source model achieving state-of-the-art text-to-SQL performance.
Introduction
Text-to-SQL systems translate natural language queries into SQL databases, allowing non-experts intuitive interaction with complex database schemas. There are two primary approaches: prompting-based methods using LLM APIs and fine-tuning methods on text-to-SQL datasets like Spider and BIRD. Prompting-based methods suffer from cost and privacy issues, while fine-tuning methods lack generalizability.
To address these limitations, the paper introduces an innovative framework that synthesizes datasets automatically. This introduces SynSQL-2.5M, a vast dataset encompassing 2.5 million samples derived from 16,000 synthetic databases. All samples are structured around a database, an SQL query, a natural language question, and a CoT solution. With this dataset, OmniSQL matches or surpasses the performance of major proprietary LLMs despite having significantly fewer parameters.
Data Synthesis Framework
The framework comprises several sequential steps, each leveraging LLMs to ensure data quality and diversity while minimizing human intervention.
- Web Table-driven Database Synthesis: Leveraging abundant web tables, the framework infers business scenarios and synthesizes realistic databases. Each synthetic database consists of multiple relational tables with key relationships and metadata such as descriptions and example data rows. Following initial generation, the framework enhances these databases to ensure complexity and completeness. This includes adding columns and completing missing relationships.
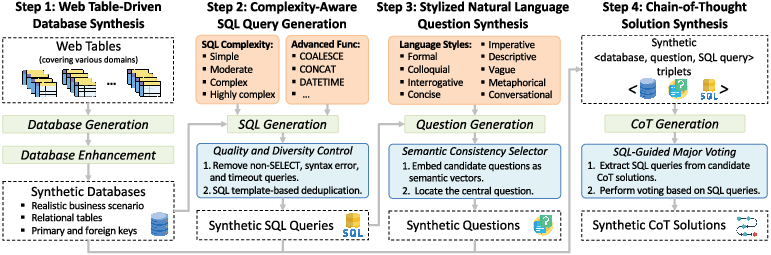
Figure 1: Pipeline for synthesizing text-to-SQL data from web tables through database generation and enhancement.
- Complexity-Aware SQL Query Generation: LLMs generate SQL queries of varied complexity, using provided advanced SQL functions and database values for context. The queries undergo post-processing to ensure quality, keeping only the diverse and syntactically correct queries.
- Stylized NL Question Synthesis: SQL queries are translated into diverse natural language styles, aligning with real-world usage scenarios. Nine language styles are defined, covering formal to metaphorical expression styles and simulating multi-turn dialogues.
- Chain-of-Thought Solution Synthesis: Inspired by CoT prompting, each data sample includes a step-by-step reasoning process that aids interpretability and SQL query accuracy.
SynSQL-2.5M Dataset
SynSQL-2.5M is a significant advance in text-to-SQL datasets, offering scale and diversity unmatched by previous efforts.
- Overall Statistics: Thousands of databases and SQL queries across a multitude of styles and domains characterize SynSQL-2.5M, enabling a comprehensive evaluation of text-to-SQL models.
- Database Diversity: Visualization of database domains indicates broad coverage and diversification compared to benchmarks.
Figure 2: t-SNE visualization of database domains and question styles.
- SQL Complexity and Diversity: SynSQL-2.5M supports sophisticated SQL features such as window functions and CTEs, ensuring realistic query patterns.
- Data Quality: Both automated and human evaluations confirm the high-quality nature of SynSQL-2.5M, underscoring its potential for training robust models.
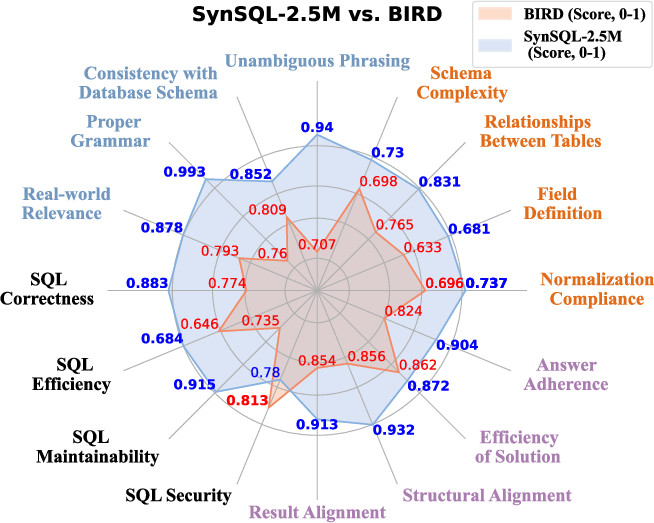
Figure 3: Quality evaluation of datasets judged by GPT-4o.
OmniSQL Model
The OmniSQL model, available in 7B, 14B, and 32B scales, leverages SynSQL-2.5M for training, making significant strides in text-to-SQL performance and generalization.
- Supervised Fine-Tuning: The model optimizes a conditional next-token prediction loss, using sequences enriched by CoT solutions.
- Experimental Results: OmniSQL demonstrates competitive performance across standard, domain-specific, and robustness benchmarks, surpassing similarly sized open-source models and proprietary alternatives.
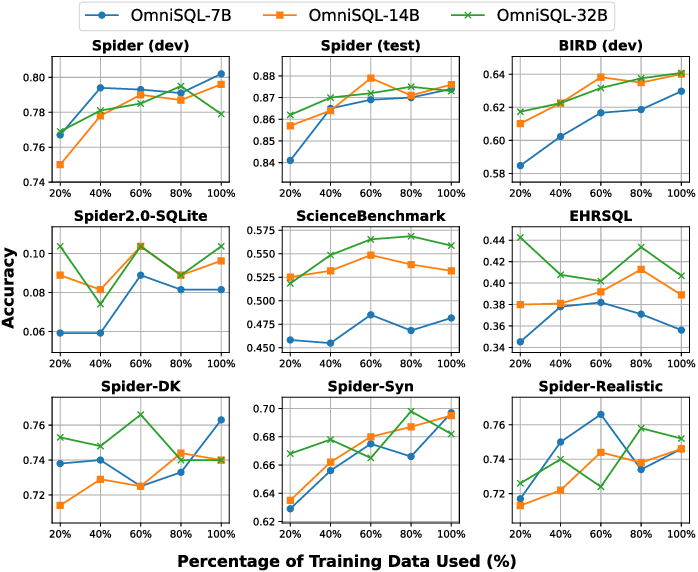
Figure 4: Performance improvement with increased training data.
Conclusion
OmniSQL's strategy in synthesizing diverse and extensive text-to-SQL data marks a pivotal shift in developing robust, generalizable database interaction systems. As an open-source initiative, it offers essential resources to advance text-to-SQL research, fulfilling the need for scalable, secure, and adaptable database querying solutions.