- The paper demonstrates that LLMs blend numeric and string properties, revealing a dual representation of numbers.
- Similarity judgments using Levenshtein and Log-Linear distances show discrepancies in numeric fidelity versus string alignment.
- Latent embedding probes with affine transformations highlight representational mixing, emphasizing the need for refined numeric reasoning.
Exploring Number Representations in LLMs
LLMs have become integral to various domains, yet understanding how they represent numerical data remains pertinent. This paper examines the dual representational roles numbers possess as both numeric entities and strings within LLMs. To study these representations, a sequence of experiments using similarity-based prompting techniques from cognitive science were conducted, uncovering the underlying tension between number and string representations in LLMs.
Introduction
The capacity of LLMs to discern numbers is essential as these models increasingly find applications in areas requiring quantitative reasoning. The paper explores the duality between numeric and string representations, revealing that LLMs blur these boundaries, resulting in entangled interpretations reflected through similarity judgments. Using prompting techniques derived from cognitive science, the study uncovers representational spaces that blend numerical and string-like characteristics. These findings highlight challenges in LLMs as they navigate contexts where digit sequences, like '911', may represent either numbers or strings.
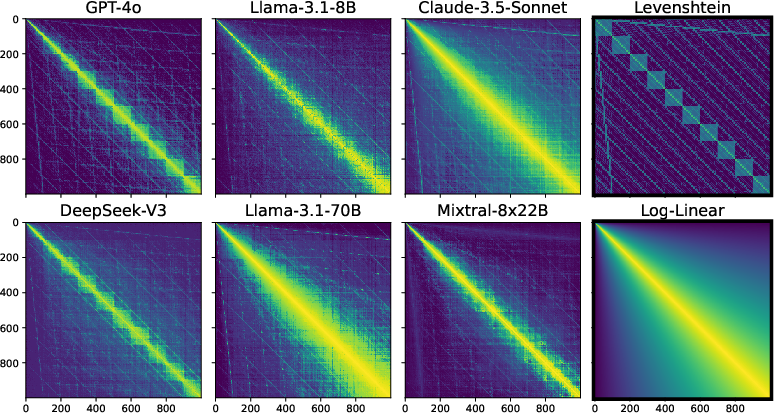
Figure 1: LLM number similarity matrices (symmetrized) over all integer pairs in the range 0-999, along with two theoretical similarity matrices derived from a Levenshtein string edit distance and a psychological Log-Linear numerical distance (highlighted in black).
Methodology
The methodology hinges on eliciting similarity judgments from modern LLMs across integers and simulating realistic scenarios. For instance, context effects via int() and str() specifications were instrumental in emphasizing representational tensions: int() focusing numerical properties and str() emphasizing string-like qualities. These contexts modulate the influence of Levenshtein and Log-Linear distances, revealing how much grounding LLMs have on number perception.
Further probing into internal representations was executed using affine transformations akin to classical probing techniques, determining how latent embeddings encode numerical distances.
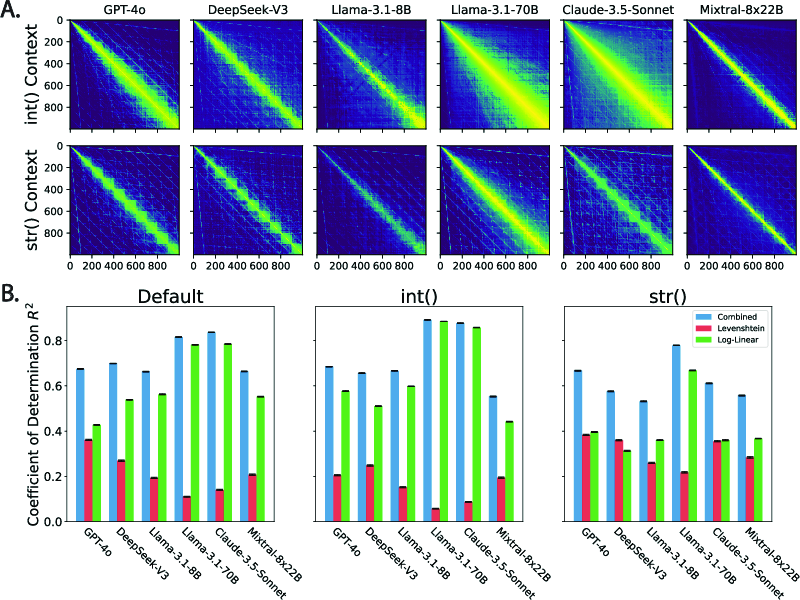
Figure 2: Context effects on LLM-elicited number similarity matrices and their decomposition. A. LLM similarity matrices under the effect of type specification: int() vs. str().
Results and Analysis
Through probing number similarities across integer pairs, an intermix of Levenshtein distance (string similarity) and Log-Linear distance (number similarity) is observable. The innate ambivalence in LLMs was notable across different contexts, denoting a split between numeric fidelity and string alignment.
A critical insight emerged when extending similarity analyses to alternate number bases. The persistence of Levenshtein patterns underscores the string representation's robustness across less common numeric systems—indicative of an entrenched string bias despite apparent numeric contexts.
Additionally, probing latent embeddings using linear transformations revealed that internal representations also reflect the external similarity judgments’ blend, affirming dual representational influences.
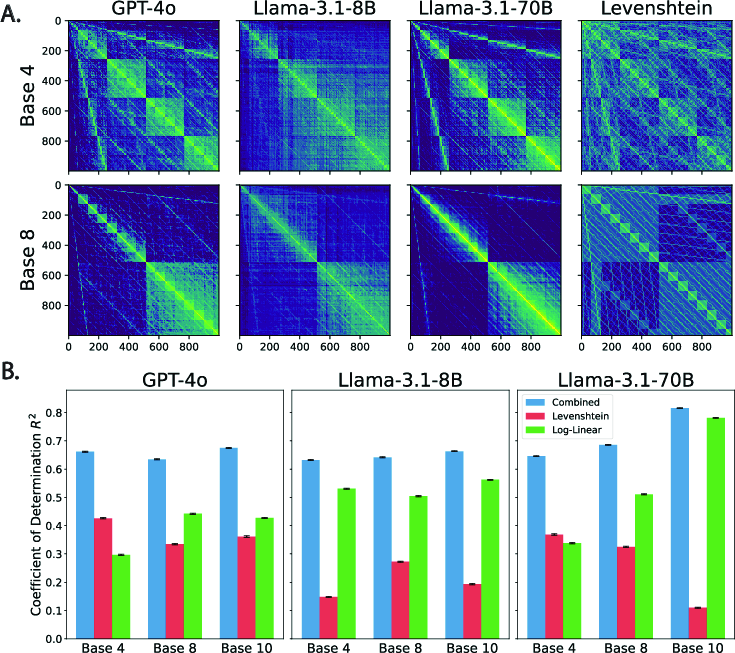
Figure 3: The effect of other number bases on elicited similarity. A. LLM similarity matrices over all integer pairs in the range 0-999 represented in base 4 and 8 along with the corresponding Levenshtein distance measures.
Discussion
The study revealed that when faced with numeric data, LLMs exhibit dual tendencies rooted in both string and numerically grounded interpretations—a tension that becomes pronounced in realistic scenarios. This tension cues potential biases when LLMs encounter numeric reasoning tasks, with discrepancies in choosing the most 'similar' numeric outcomes based on numeric versus string properties. Such phenomena might influence practical applications where quantitative accuracy is crucial.
These representational challenges prompt considerations for further refinement of LLMs, especially in contexts requiring precise numeric understanding. Advances in probing and training methodologies could mitigate the observed biases and enhance numeric reasoning capabilities.
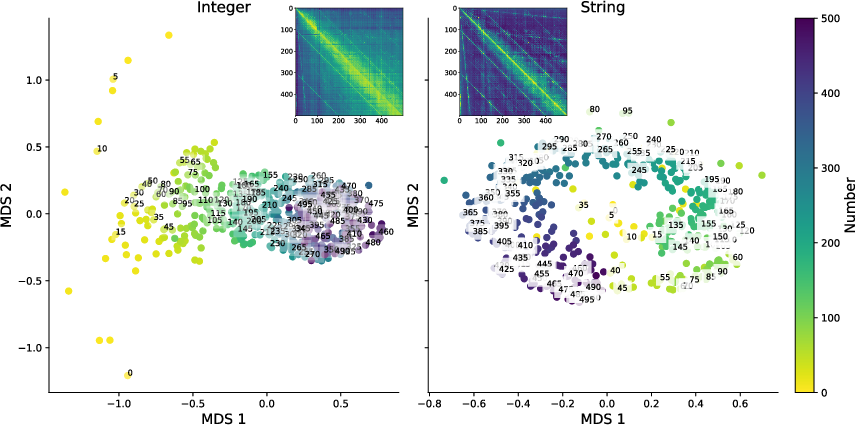
Figure 4: Decoded string and integer subspaces from Llama-3.1-8b using linear probes.
Conclusion
Understanding numerical representations within LLMs is imperative as AI systems increasingly affect decision-making contexts. This paper contributes insights into representational dynamics within LLMs, indicating profound string-numeric entanglement. Such findings underscore the importance of refining model training techniques and probing strategies to foster accurate numeric comprehension and application in everyday scenarios.
Future explorations should aim at disentangling these representations, fostering robust numeric reasoning frameworks in LLMs. As AI continues to bridge human-like intelligence with machine capabilities, the clarity of numeric representations becomes crucial for integration into intricate decision-making infrastructures.