- The paper proposes a pluggable full-duplex control module that decouples dialogue generation from speech processing, achieving a 7.6% improvement in turn-taking accuracy.
- The methodology employs an explicit Idle state and adaptive sliding window to reduce noise interference by 24.9% and lower conditional perplexity scores by up to 35.3%.
- Experimental evaluations on English and Chinese datasets demonstrate enhanced dialogue quality and efficient interaction dynamics in real-world scenarios.
FlexDuo: Enabling Full-Duplex Capabilities in Dialogue Systems
Introduction
The development of fluid, human-like communication in speech dialogue systems represents a significant advancement in human-machine interaction. Traditional systems predominately operate on a half-duplex basis, limiting bidirectional communication to only sequential exchanges, thus diverging from the simultaneous listening and speaking found in human interactions. Full-Duplex Speech Dialogue Systems (Full-Duplex SDS) endeavor to overcome these limitations but frequently encounter challenges related to module optimization and noise interference, stemming from their tightly integrated architectures. The paper "FlexDuo: A Pluggable System for Enabling Full-Duplex Capabilities in Speech Dialogue Systems" (2502.13472) proposes an innovative solution featuring a decoupled, plug-and-play architectural design, augmented by an explicit Idle state to optimize dialogue quality and reduce interruptions.
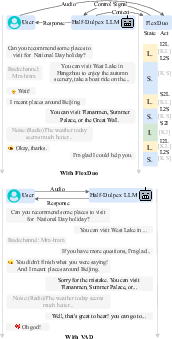
Figure 1: Performance of the half-duplex dialogue system with FlexDuo and VAD in real-world dialogue scenarios.
Methodology
FlexDuo introduces a pluggable full-duplex control module that can integrate seamlessly with half-duplex systems, thus promoting modularity and flexibility. The key novelty lies in decoupling the duplex control from dialogue generation and speech processing, facilitated by a unique dialogue state model incorporating the Listen, Speak, and Idle states. The Idle state is particularly noteworthy for its role in filtering non-essential audio inputs, thereby preserving the integrity of dialogue contexts and reducing false interruptions by 24.9%.
The control module functions through collaborative interaction with a half-duplex LLM, as depicted in the illustrated workflow (Figure 2). The system efficiently processes user audio alongside LLM responses, issuing control signals and delivering filtered audio data to the LLM. Through this mechanism, FlexDuo exhibits improvements in both turn-taking accuracy and response accuracy, as demonstrated by a 7.6% increase compared to existing full-duplex solutions.
Figure 2: FlexDuo Workflow and Framework for Interaction with half-duplex LLMs.
The state manager employs a finely tuned finite state machine (FSM) for dialogue strategy prediction, ensuring optimal response timing based on contextual cues from past dialogues. Additionally, the introduction of a sliding window enhances semantic understanding by adapting its size according to the current dialogue state. The empirical validation of FlexDuo against VAD-controlled systems further underscores its capacity to balance interaction dynamics and maintain context clarity.
Experimental Evaluation
Extensive testing using the Fisher corpus for English and Chinese dialogues confirms FlexDuo's superior performance in real-world scenarios (Table 1). The evaluation metrics underscore significant improvements in both interaction capability and dialogue quality, with conditional perplexity scores reduced by 35.3% and 19% for English and Chinese datasets, respectively (Table 2). These results reflect effective management of turn-taking and context filtering, illustrating robust adaptability to complex dialogue interactions.
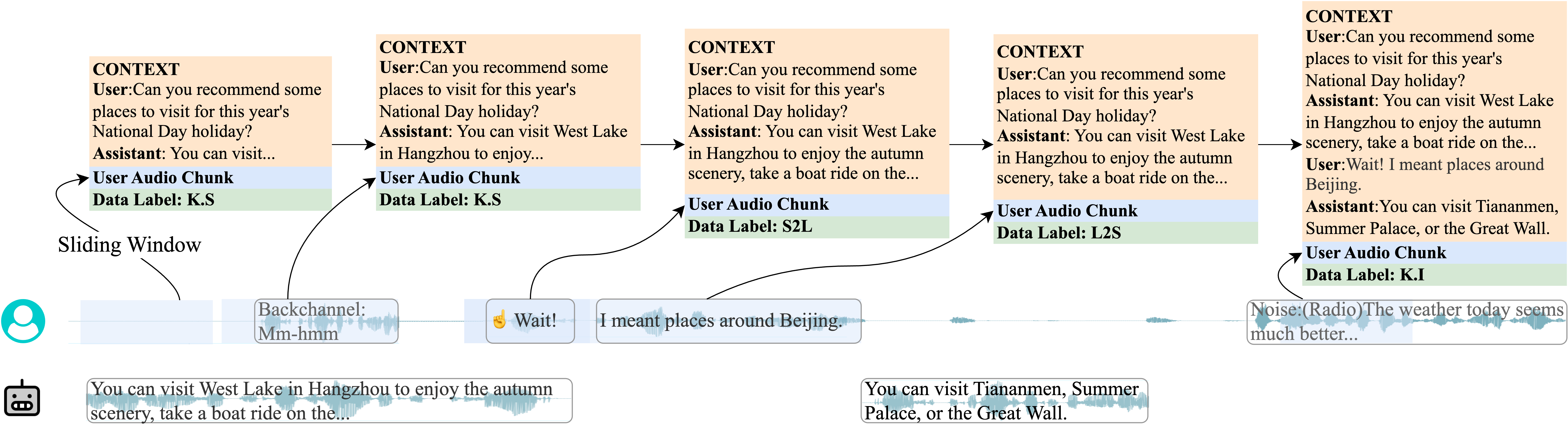
Figure 3: An example of training data construction.
An ablation study examining the impact of the explicit Idle state revealed notable enhancements in system performance, evidencing its critical role in noise filtration and semantic clarity (Table 3). Further analysis of sliding window size (Table 4) provided insights into the trade-off between real-time responsiveness and comprehensive contextual modeling, reinforcing the design choices within FlexDuo.
Future Directions
Future research avenues for FlexDuo include integrating multimodal signals, like gestures and facial expressions, to bolster full-duplex dialogue control capabilities. Another promising direction lies in modeling user dialogue states to create more comprehensive strategies that could incorporate reinforcement learning for adaptive interaction improvements.
Conclusion
FlexDuo represents a significant step forward in the development of flexible, full-duplex dialogue systems, effectively addressing issues of high module coupling and noise interference. Its modular architecture and state-based model set the stage for future innovations, offering a pathway for natural, efficient human-machine communication. As speech dialogue systems continue to evolve, FlexDuo's design principles provide valuable insights and foundations for subsequent developments in the field.