- The paper introduces a duplex S2S system that simultaneously processes user speech and agent responses, enhancing real-time turn-taking and barge-in capabilities.
- The model leverages a personalized codec and streaming speech encoder to achieve low latency (0.69 sec) and a high barge-in success rate (over 94.5%).
- The approach removes the need for initial speech pretraining, simplifying integration with LLM backbones and enabling efficient, dynamic dialogue systems.
SALM-Duplex: Efficient and Direct Duplex Modeling for Speech-to-Speech LLM
Introduction
"SALM-Duplex: Efficient and Direct Duplex Modeling for Speech-to-Speech LLM" (2505.15670) introduces a novel approach in human-computer interaction through a duplex Speech-to-Speech (S2S) architecture. This model seamlessly integrates simultaneous user inputs and agent outputs, enhancing capabilities such as turn-taking and barge-in, which are essential for real-time adaptability in spoken dialogue systems. This work distinguishes itself by eliminating the need for initial speech pretraining, thereby simplifying the integration of any given LLM backbone, and significantly lowering the bar for constructing duplex models.
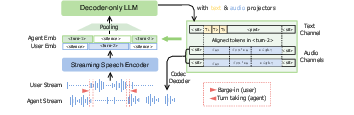
Figure 1: The proposed duplex S2S model without requiring speech-text pretraining. Our model includes a streaming speech encoder, a personalized codec, and an LLM. The model is trained to predict both text and audio channels in parallel with turn-level alignments.
Model Architecture
The duplex architecture relies on a tandem input of agent speech and text, processed through a pretrained streaming encoder. The model capitalizes on this encoder's capability, along with a personalized codec, which reduces the computational overhead typically required in speech-text training. The joint input is subsequently processed through an LLM to foster synchrony between the user's continuous speech and the agent's responses, thereby ensuring the duplex nature of the model. This architecture promotes codec fine-tuning for superior voice quality in agent outputs while utilizing a lower bitrate of 0.6 kbps, thereby maximizing efficiency without compromising audio quality.
Training and Data Preparation
The training methodology introduces a sophisticated data preparation strategy featuring a duplex format that incorporates separate threads for user and agent dialogues. This is particularly effective in managing multi-turn conversations and barge-in scenarios (Figure 2 and Figure 3). The comprehensive conversational datasets are constructed by synthesizing speech through multi-speaker TTS from a diverse set of data sources, ensuring robustness in interaction types ranging from simple queries to complex multi-turn dialogues.
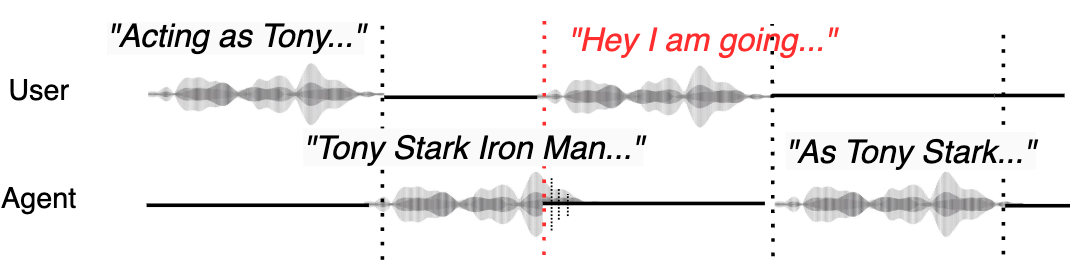
Figure 2: Duplex training data format. Our duplex data consists of separate user and agent streams including turn taking and barge-in behavior. Here, the user barges in at the second turn.
Evaluation and Results
The model's evaluation demonstrates superior performance across several dimensions of interactive behavior. Metrics highlight its prowess in maintaining responsiveness to barge-ins, with a low latency average of just 0.69 seconds and a barge-in success rate of over 94.5% (Table 1). The architecture's ability to merge low-latency, real-time processing with high-quality speech codec personalization is reflected in the high UTMOS ratings, which show significant improvements over prior models like Moshi.
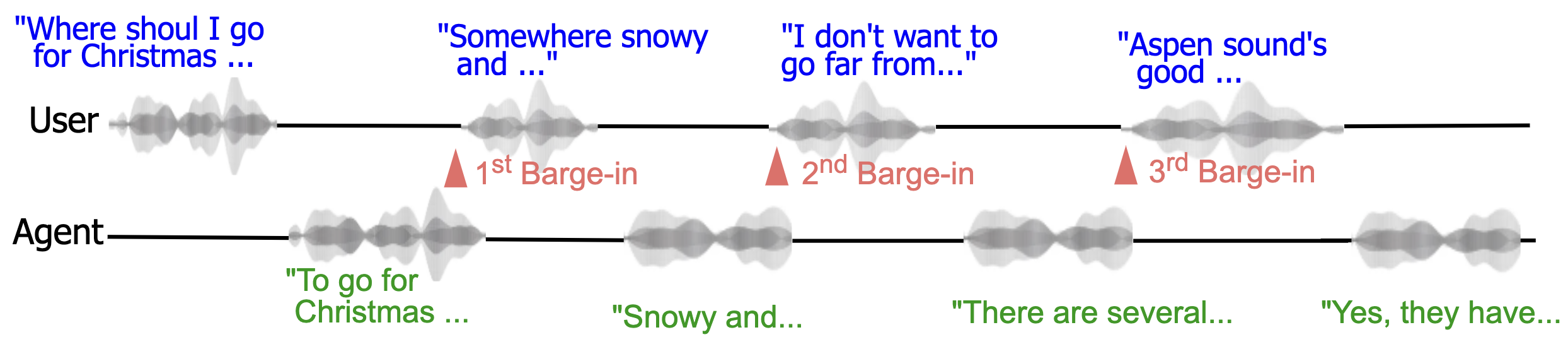
Figure 3: Multi-turn conversation with frequent barge-in.
Moreover, reasoning capabilities evaluated through GPT scores indicate competitive, often superior, results compared to both prior full-duplex systems and optimal cascaded setups. Future work should focus on refining turn-taking and interaction latency times and further exploring end-to-end reasoning enhancements.
Conclusion
The SALM-Duplex model represents a significant advancement in the development of duplex S2S systems. By removing the obligatory speech pretraining phase, this model simplifies the process of developing speech-based interactive systems while enabling richer, more dynamic dialogues. The open-source availability of both training and inference code will undoubtedly serve as a fertile ground for further innovation and research in efficient duplex communication.