- The paper introduces LegalBench.PT, the first benchmark designed to evaluate LLMs on 31 distinct Portuguese legal domains.
- The paper details a comprehensive methodology that converts law school exam questions into multiple-choice, true/false, and matching formats using GPT-4o, with rigorous filtering and expert validation.
- The paper demonstrates that leading LLMs like GPT-4o and Claude-3.5-Sonnet approach high performance on structured legal queries while struggling with ambiguous questions.
LegalBench.PT: A Benchmark for Portuguese Law
Introduction
"LegalBench.PT" (2502.16357) introduces the first benchmark tailored for the Portuguese legal system, designed to evaluate the performance of LLMs across diverse fields of Portuguese law. LegalBench.PT provides a comprehensive assessment mechanism for LLMs, employing synthetically generated questions derived from law school exams at a leading Portuguese law school. Utilizing GPT-4o, these exams, initially composed of long-form analytical exercises, are converted into multiple-choice, true/false, and matching question formats, optimizing them for machine evaluation.
Full Taxonomy of Portuguese Law
The benchmark is organized around a detailed taxonomy of Portuguese law, encompassing 31 distinct areas across five primary domains: Public Law, Private Law, Public-Private Law, Public International Law, and EU and Community Law (Figure 1). This systematic categorization serves as the foundational structure for developing and evaluating LLM proficiency within specific legal domains.
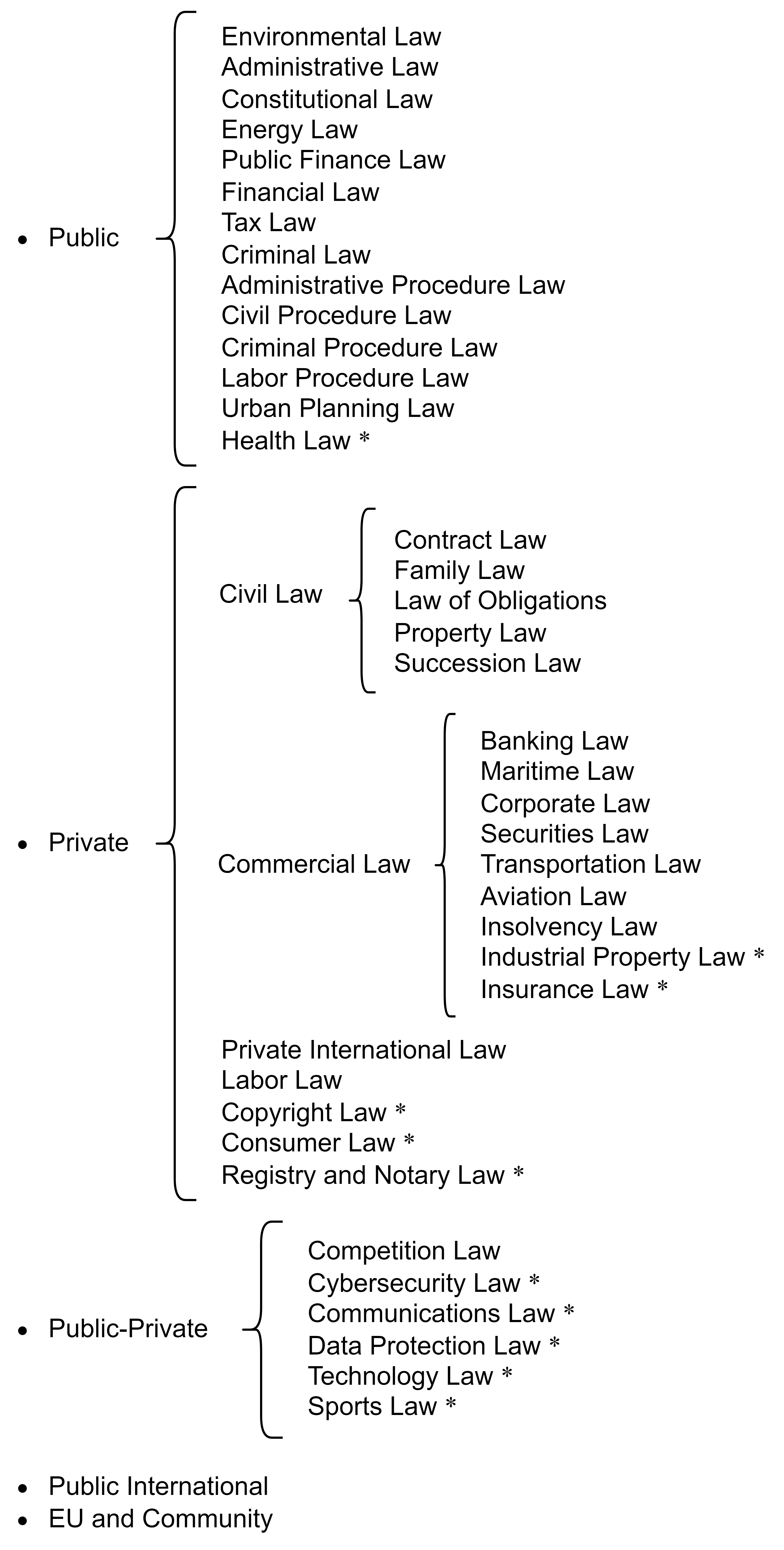
Figure 1: Full taxonomy of the Portuguese law adopted. Names marked with *
are not included in the benchmark due to lack of source data.*
Methodology
The creation of LegalBench.PT involved generating a robust dataset of 4,723 questions. The workflow for generating these questions included several key phases:
- Data Collection and Processing: Legal exams from the University of Lisbon were manually collected, providing the basis for question generation. These exams were methodically parsed to extract relevant question-answer pairs.
- Question Generation: GPT-4o was employed to transform open-ended questions into more structured formats suitable for LLM evaluation. The generation process involved synthesizing 31 legal areas into multiple-choice, true/false, and matching questions.
- Quality Control and Filtering: Rigorous filtering processes were implemented to eliminate duplicates and irrelevant content, ensuring the relevance and accuracy of the benchmark.
- Validation: Legal professionals reviewed subsets of the generated questions to ensure their legal pertinence and syntactical accuracy, revealing that 12% of answers were incorrect and 15% required rephrasing for optimal legal terminology.
Figure 2: LegalBench.PT construction pipeline.
Evaluation
The benchmark's efficacy was evaluated using several leading LLMs, including GPT-4o, GPT-4o-mini, Claude-3.5-Sonnet, and Llama-3.1-405B, among others. The assessment revealed that GPT-4o and Claude-3.5-Sonnet achieved the highest performance scores, closely followed by Llama-3.1-405B. The comparison with human performance on a subset of questions established that the benchmark accurately reflects model proficiency in legal reasoning, though it highlighted areas where model performance lagged behind intricate human judgment.
The results demonstrated that while LLMs excel in structured legal knowledge recall and rule application, they are often challenged by ambiguous question framing and contextual interpretation, which human participants better navigated.
Implications and Future Work
LegalBench.PT offers a pivotal resource for advancing the development of legally adept LLMs, particularly in jurisdictions using the Portuguese legal system. Future research could extend the benchmark to cover less represented legal areas, improve the accuracy of synthetically generated questions, and explore tasks that evaluate beyond legal knowledge, such as real-time legal process transcription and decision rationale generation.
Conclusion
LegalBench.PT sets a precedent for specialized LLM evaluation tools in legal contexts, emphasizing the importance of region-specific benchmarks. This initiative opens avenues for refining how LLMs are trained and tested in understanding complex legal systems, encouraging further advancements and adaptations in the scope of legal AI research.
