- The paper introduces new reasoning-focused legal retrieval benchmarks, Bar Exam QA and Housing Statute QA, that address low lexical overlap challenges.
- It employs structured query expansion and dense embedding models to achieve significant recall improvements on multi-hop legal reasoning tasks.
- The study underscores the need for advanced legal AI systems that integrate reasoning capabilities to improve retrieval-augmented language models.
A Reasoning-Focused Legal Retrieval Benchmark
Introduction
The paper "A Reasoning-Focused Legal Retrieval Benchmark" introduces novel benchmark datasets, Bar Exam QA and Housing Statute QA, designed to evaluate retrieval-augmented LLMs (RAG systems) in legal contexts. These benchmarks address the lack of realistic legal RAG benchmarks that capture the complexity of legal document retrieval and downstream legal QA tasks. The new benchmarks focus on reasoning-intensive tasks that require identifying relevant documents with low lexical overlap with queries.
Datasets
- Bar Exam QA: Modeled after reasoning-intensive bar exam questions, it involves Q&A pairs requiring legal reasoning with judicial opinions as supporting documents. This dataset emphasizes multi-hop and analogical reasoning, which is essential in real-world legal research.
- Housing Statute QA: Comprising questions about housing law across jurisdictions, this dataset involves reasoning over statutes to answer yes/no questions. It is derived from the Legal Services Corporation Eviction Laws Database and focuses on statutory interpretation.
These datasets differ significantly from conventional retrieval tasks by emphasizing low lexical similarity between queries and documents, necessitating advanced reasoning capabilities in retrieval models.
Dataset Construction
The datasets were constructed through an annotation process simulating legal research. Queries were hand-annotated by law students and legal experts, ensuring high-quality, realistic legal tasks. This approach deviates from extractive constructions used in previous benchmarks, providing substantive legal questions and expert-annotated supporting law passages.
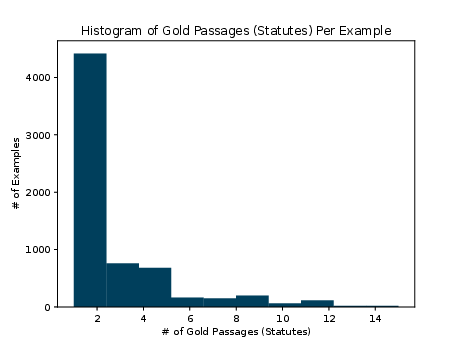
Figure 1: Histogram of number of gold passages (statutes) per example in the Housing Statute QA dataset.
Methodology
The paper evaluates several retrieval models, including BM25 and the E5 family of dense embedding models. The authors also explore generative query expansion techniques, leveraging structured reasoning rollouts to improve retrieval performance.
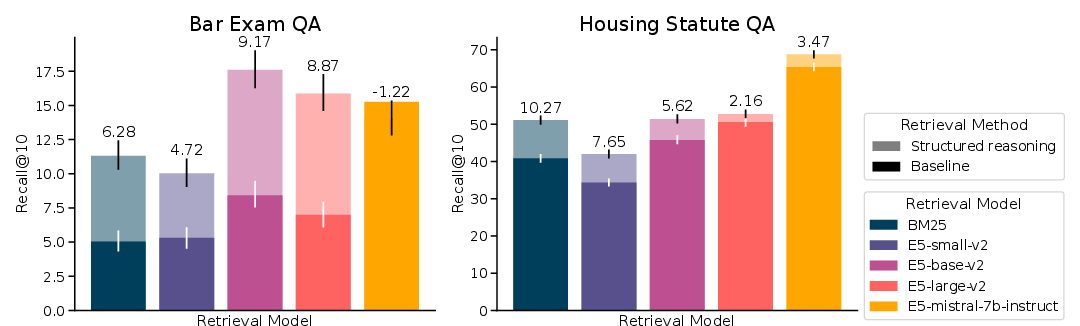
Figure 2: Recall of baseline and structured reasoning rollout query expansion retrieval for lexical (BM25) and dense models (E5 family), evaluated on legal retrieval benchmark tasks.
Evaluation
Baseline retrieval performance was assessed across different datasets, with Bar Exam QA and Housing Statute QA showing lower recall for traditional models like BM25 due to the low lexical similarity nature of the tasks. Structured reasoning rollouts yielded significant recall improvements, particularly benefiting lexically-focused retrievers.
Discussion
The results highlight the challenges of legal retrieval tasks that require reasoning over lexically diverse legal texts. The study underscores the need for retrieval models that can incorporate legal reasoning, suggesting structured query expansions as a promising approach.
Implications and Future Work
Legal retrieval-augmented LLMs must evolve to handle reasoning-focused tasks effectively. Future work should focus on enhancing the reasoning capabilities of retrievers and improving the ability of downstream models to process retrieved legal documents. The benchmarks introduced in this study serve as a significant step towards evaluating and improving legal AI systems' performance in retrieval-augmented scenarios.
Conclusion
This benchmark provides a challenging testbed for legal retrieval systems, emphasizing reasoning over lexical overlap. The structured reasoning approach offers a pathway for enhancing retrieval models, contributing to the development of more sophisticated legal AI applications. These datasets and evaluations highlight the critical role of reasoning in legal retrieval tasks, necessitating advancements in both retrieval and reasoning capabilities in AI systems.