- The paper introduces LexRAG, a benchmark that evaluates retrieval-augmented generation in multi-turn legal consultations by addressing challenges like context management and legal reasoning.
- It leverages a dataset of 1,013 expert-annotated dialogues and 17,228 legal articles to assess both conversational knowledge retrieval and precise response generation.
- The study reveals that even advanced LLMs with neural retrieval strategies struggle with complex legal reasoning, highlighting significant opportunities for future improvements.
LexRAG: Benchmarking Retrieval-Augmented Generation in Multi-Turn Legal Consultation Conversation
Introduction
The paper introduces LexRAG, a benchmark designed to evaluate Retrieval-Augmented Generation (RAG) systems within multi-turn legal consultation dialogues. RAG has demonstrated enhanced performance in several domains by synergizing information retrieval with language generation. However, its adoption and evaluation within the legal field face significant challenges. Legal dialogues often involve extensive context management, abrupt topic shifts, and complex legal reasoning. LexRAG aims to provide an evaluation framework that addresses these challenges through a specially curated dataset and toolkit.
LexRAG Benchmark
LexRAG consists of 1,013 dialogues, each featuring five turns of interaction, annotated by legal experts. The dataset includes 17,228 legal articles across various domains, challenging the RAG systems to retrieve legally relevant information and generate precise responses. The benchmark focuses on two key tasks: Conversational Knowledge Retrieval and Response Generation. Systems must effectively integrate dialogue context to retrieve relevant articles and generate responses consistent with legal reasoning and logic.

Figure 1: An example of a legal consultation in LexRAG.
The complexity of legal domain RAG lies in managing multi-turn interactions where queries evolve through clarification and topic shifts, often unrelated to lexical similarity. Retrieval systems must reason beyond lexical matching to pinpoint the legal essence of inquiries.
To facilitate the adoption and reproducible evaluation of RAG systems, the LexiT toolkit provides a modular framework encompassing retrieval, generation, and evaluation components. LexiT supports various retrieval strategies, from BM25 for lexical matching to neural methods like BGE and GTE-Qwen2. For query processing, it offers techniques ranging from simple last-query utilization to sophisticated query rewriting using transformer models to ensure coherent and contextually appropriate inputs for retrieval.
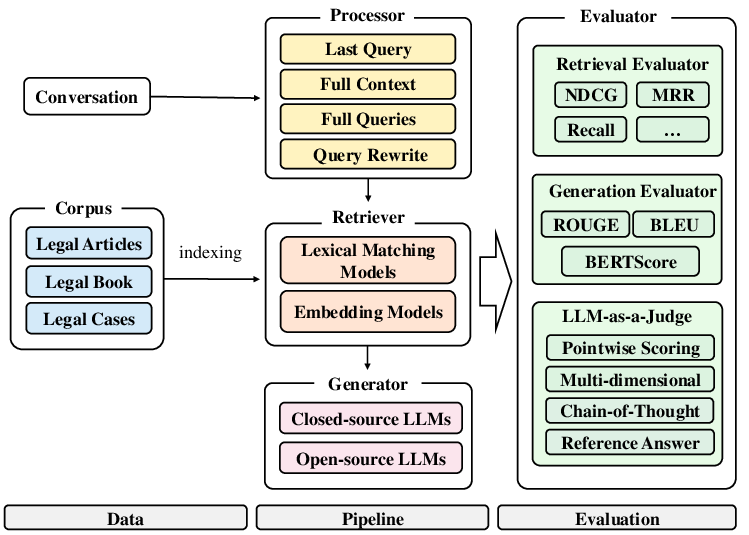
Figure 2: Overview of LexiT Components.
LexiT also features an LLM-as-a-judge evaluation approach, using LLMs to simulate expert evaluation across dimensions like factuality, logical coherence, and completeness.
Challenges and Evaluation
Experiments conducted using LexRAG reveal significant challenges in legal domain RAG systems. While dense retrieval models outperform lexical methods, they still underperform in scenarios requiring complex legal reasoning. The best-performing retrieval strategy only managed a Recall@10 of 33.33%, indicating substantial room for improvement.
Similarly, response generation tasks highlight the limitations of even advanced LLMs. Under ideal settings with reference-annotated legal content, LLMs like Qwen-2.5-72B show improvement but still fail to capture comprehensive legal reasoning. This reflects the foundational gap in LLMs when confronted with the nuanced reasoning required in legal domains.
Conclusion
LexRAG sets a new standard for evaluating RAG systems in legal contexts, providing insights into the unique challenges posed by legal consultation dialogues. By incorporating modules that handle the intricacies of legal query management and context integration, LexRAG serves as an essential tool for advancing legal AI research. Future expansions will target multilingual datasets and the adaptation of RAG systems to diverse legal systems, extending its applicability beyond the Chinese legal context.